本文主要是介绍揭开 Amazon Bedrock 的神秘面纱 | 基础篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在 2023 年 4 月,亚马逊云科技曾宣布将 Amazon Bedrock 纳入使用生成式人工智能进行构建的新工具集。Amazon Bedrock 是一项完全托管的服务,提供各种来自领先 AI 公司(包括 AI21 Labs、Anthropic、Cohere、Stability AI 和 Amazon 等)的高性能基础模型(FM),以及用于构建生成式人工智能应用程序的广泛功能,可简化开发,同时维护隐私和安全。
在 9 月底,我们欣喜地看到 Amazon Bedrock 已经正式发布了!为了帮助广大的中国开发者更快地上手 Amazon Bedrock,来更高效方便地构建生成式人工智能应用程序,特策划了这个“揭秘 Amazon Bedrock ”的系列。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点 这里让它成为你的技术宝库!
本文是“揭秘 Amazon Bedrock ”的第一篇:基础篇。
开始使用 Amazon Bedrock
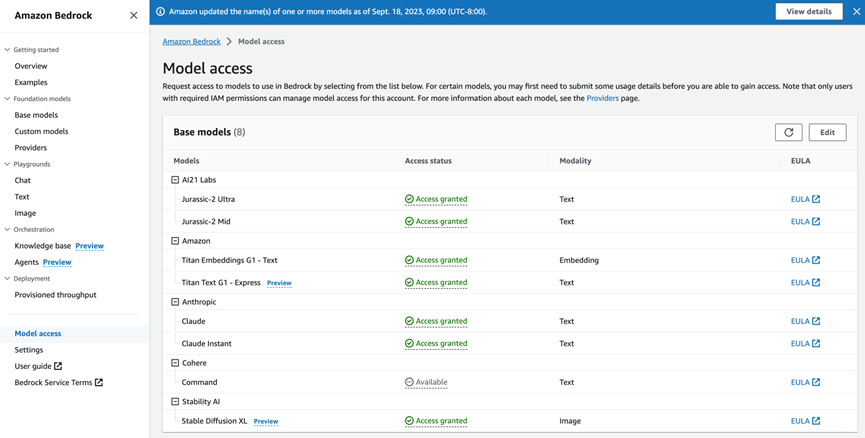
可以通过亚马逊云科技管理控制台、亚马逊云科技软件开发工具包和开源框架(例如 LangChain)访问 Amazon Bedrock 中可用的基础模型(FM)。在 Amazon Bedrock 控制台中,可以浏览 FM,浏览和加载每个模型的示例用例和提示。首先,需要启用对模型的访问权限。在控制台中,选择左侧导航窗格中的模型访问权限并启用您要访问的模型。启用模型访问权限后,可以尝试不同的模型和推理配置设置,以找到适合用例的模型。
1.在 Amazon Bedrock 控制台中使用模型
在 Amazon Bedrock 控制台中,选择左侧导航窗格中的模型访问权限(Model access),然后启用您要访问的模型。启用模型访问权限后,可以选择使用 Playground 的交互方式或者 API 方式来使用模型了。
例如,以下是使用 Claude v2 的 文本生成(Content Generation)用例示例:
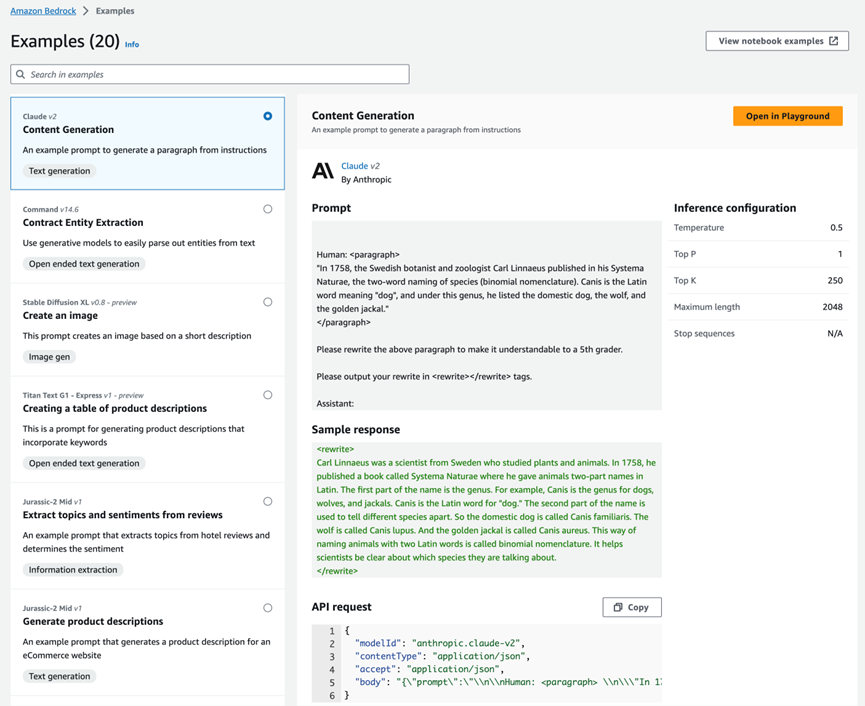
该示例显示了带有示例响应的提示、示例的推理配置参数设置以及运行该示例的 API 请求。如果您选择 “Open in Playground”,则可以在交互式控制台体验中进一步探索模型和用例。Amazon Bedrock 提供聊天、文字和图像模型的 Playground。在聊天平台中,您可以使用对话聊天界面尝试各种 FM。以下示例使用 Anthropic 的 Claude V2 模型,来询问中国香港最值得去的餐厅列表:
- 《Anthropic》
https://www.anthropic.com/?trk=cndc-detail
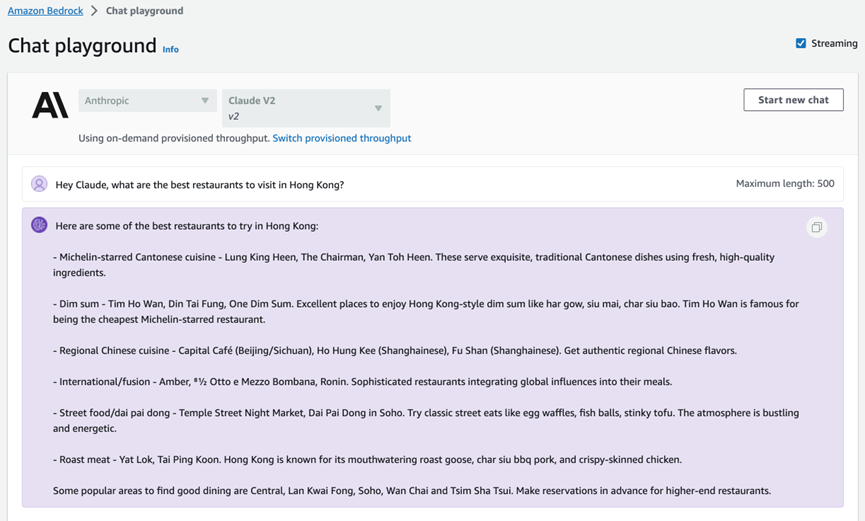
在评估不同的模型时,应尝试各种提示工程技术和推理配置参数。提示词工程(Prompt Engineering) 是一项令人兴奋的新技能,专注于如何更好地理解 FM 并将其应用于你的任务和用例。有效的提示词工程可以充分利用 FM 并获得正确而精确的响应。
以下示例是接着上面截图中 Claude V2 模型的回复,进一步询问铜锣湾附近值得去的餐厅:
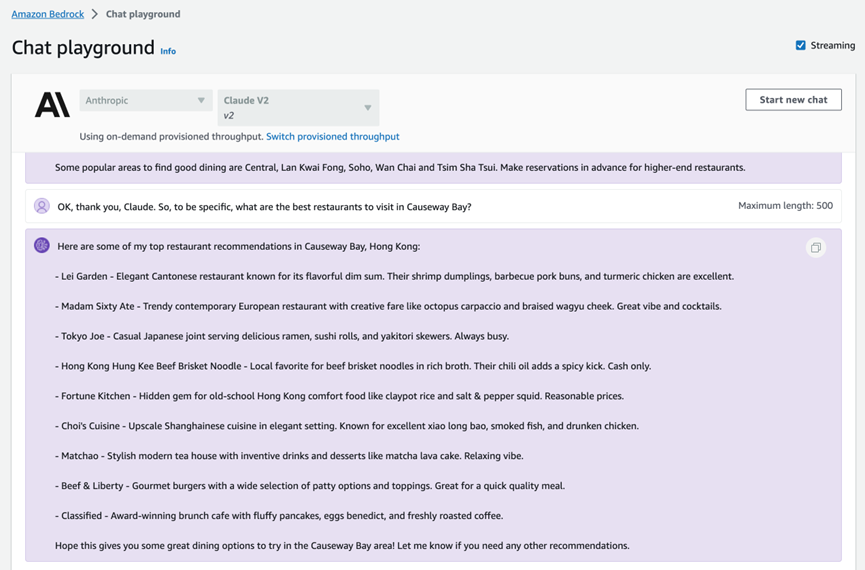
然后可以继续追问 Claude V2:“好的,请在具体一点,铜锣湾附近的广东菜餐厅呢?”,来测试下模型对上下文是否有正确的认知:

推理配置参数会影响模型生成的响应。Temperature、Top-P 和 Top-K 等参数可让您控制随机性和多样性,而 “最大长度”(Maximum) 或 “最大标记”(Max Tokens) 控制模型响应的长度,如下图所示。

请注意,每个模型都公开了一组不同但往往重叠的推理参数。这些参数要么在模型之间命名相同,要么足够相似,足以在你尝试不同的模型时进行推理。
你还可以在提示中提供示例,或者鼓励模型通过更复杂的任务进行推理。可以查看 Amazon Bedrock 文档(如下链接)和模型提供商的相应文档,以获取更多提示词建议和最佳实践:
https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-...
2.用 API 方式使用模型
本章我们将探讨如何通过boto3 Python SDK 来使用Amazon Bedrock 基础模型。
以下代码示例,将使用适用于 Python 的亚马逊云科技开发工具包 (Boto3) 与 Amazon Bedrock 进行交互。完整代码请参阅:
https://github.com/aws-samples/amazon-bedrock-workshop/blob/main/00_Intro/bedrock_boto3_setup.ipynb?trk=cndc-detail
关于适用于 Python 的亚马逊云科技开发工具包,可参考以下链接文档:
https://aws.amazon.com/sdk-for-python/?trk=cndc-detail
2.1 权限设置
首先需要设置 notebook 环境的角色和权限,必须具有足够的 IAM 权限才能调用 Amazon Bedrock 服务。
授予 Amazon Bedrock 权限的参考步骤如下:
- 打开 IAM 控制台
- 查找角色(如果使用 SageMaker 或以其他方式担任 IAM 角色),或者找到用户
- 选择 “添加权限” > “创建内联策略” 以附加新的内联权限,打开 JSON 编辑器并粘贴以下示例策略:
{"Version": "2012-10-17","Statement": [{"Sid": "BedrockFullAccess","Effect": "Allow","Action": ["bedrock:*"],"Resource": "*" } ]
}
我使用我的 “sagemaker-demo-role-haowen” 角色,其中包括上面代码中的 “bedrock_full_access_haowen” 策略。如下面截图所示。
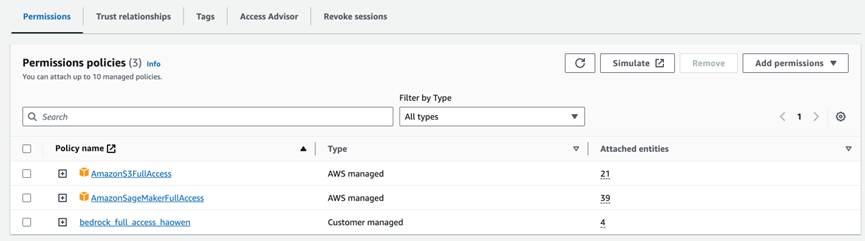
2.2 环境设置
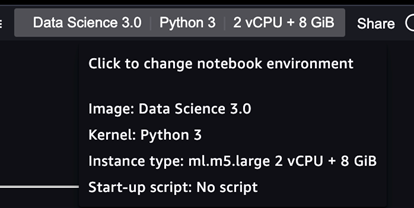
对于 SageMaker Studio,我的环境配置如下:
- Data Science 3.0
- Python 3
- ml.m5.large
- us-east-1 region
对于 SageMaker Notebook Instances,我的环境配置如下:
- Conda_Python3
- ml.m5.large
- us-east-1 region

克隆示例代码并使用 Notebook
在 SageMaker Studio 中,可以通过单击 “File > New > Terminal” 打开 “System Terminal” 来运行这些命令。设置好笔记本环境后,将代码从 GitHub 上克隆到本地:
cd ~/SageMaker(in SageMaker Notebook instance) or cd ~(in SageMaker Studio)git clone https://github.com/aws-samples/amazon-bedrock-workshop.gitcd amazon-bedrock-workshop/bash ./download-dependencies.sh

此脚本将创建一个依赖项文件夹并下载相关的 SDK,但暂时不会 pip 安装它们(安装过程将在后面将要介绍的这个.ipynb 文件里执行来完成)。软件包准备就绪后,你可以通过选择下面的.ipynb 文件开始你的 Amazon Bedrock 体验之旅:
amazon-bedrock-workshop/00_Intro/bedrock_boto3_setup.ipynb
完整的参考代码如下链接,供参考:
https://github.com/aws-samples/amazon-bedrock-workshop/blob/main/00_Intro/bedrock_boto3_setup.ipynb?trk=cndc-detail
2.3 创建 boto3 客户端
我们接下来与 Bedrock API 的交互是通过适用于 Python 的开发工具包 boto3 完成的,运行下面的单元把 boto3 安装到 notebook 内核中:
# Make sure you ran `download-dependencies.sh` from the root of the repository first! %pip install --no-build-isolation --force-reinstall \../dependencies/awscli-*-py3-none-any.whl \ ../dependencies/boto3-*-py3-none-any.whl \ ../dependencies/botocore-*-py3-none-any.whl
安装 LangChain 包:
%pip install --quiet langchain==0.0.304
在创建 Amazon Bedrock 服务客户端时,可能需要自定义设置。get_bedrock_client() 方法支持传入不同的选项,你可以在/utils/bedrock.py 这个文件之中找到这个方法的实现。如下所示。
import json
import osimport sysimport boto3module_path = ".."
sys.path.append(os.path.abspath(module_path))
from utils import bedrock, print_wwboto3_bedrock = bedrock.get_bedrock_client( assumed_role=os.environ.get("BEDROCK_ASSUME_ROLE", None), endpoint_url=os.environ.get("BEDROCK_ENDPOINT_URL", None), region=os.environ.get("AWS_DEFAULT_REGION", None),
)
2.4 验证连通性
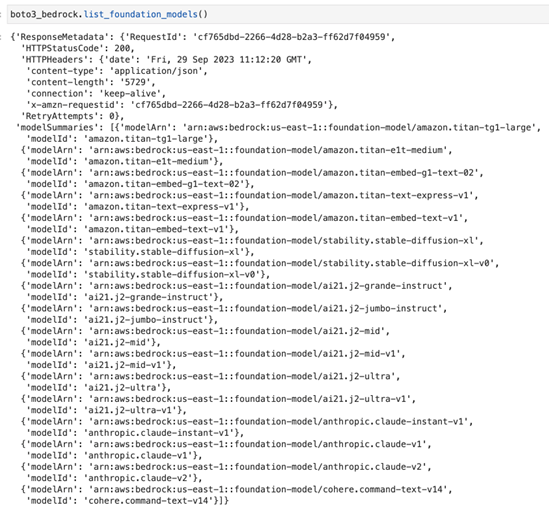
可以通过调用 list_foundation_models() 方法来检查客户端的设置是否正常,该方法将列出所有可供使用的基础模型(foundation models):
boto3_bedrock.list_foundation_models()
2.5 模型输入和输出体格式设置
无论我们使用哪种模型,Amazon Bedrock 客户端的 invoke_model() 方法都是用于大多数文本生成和处理任务的主要方法。该方法输入和输出的格式因所使用的基础模型而异。
以下用 Claude 模型和 Stable Diffusion 模型分别举例说明。
Anthropic Claude
Input
{ "prompt": "\n\nHuman:<prompt>\n\nAnswer:","max_tokens_to_sample": 300,"temperature": 0.5, "top_k": 250, "top_p": 1,"stop_sequences": ["\n\nHuman:"]
}
Output
{ "completion": "<output>", "stop_reason": "stop_sequence"
}
Stability AI Stable Diffusion XL
Input
{ "text_prompts": [ {"text": "this is where you place your input text"} ], "cfg_scale": 10, "seed": 0, "steps": 50
}
Output
{ "result": "success", "artifacts": [ { "seed": 123, "base64": "<image in base64>", "finishReason": "SUCCESS" }, //... ]
}
2.6 常用推理参数定义
- 随机性和多样性(Randomness and Diversity)
基础模型支持以下参数来控制响应的随机性和多样性。
温度(Temperature): 大型语言模型使用概率来构造序列中的单词。对于任何下一个单词,序列中下一个单词的选项都存在概率分布。将温度设置为接近零时,模型倾向于选择概率更高的单词;将温度设置得离零更远时,模型可能会选择一个概率较低的词。
Top K: 温度定义潜在单词的概率分布,前 K 定义模型不再选择单词的截止点。例如,如果 K=50,则模型会从 50 个最有可能出现在给定序列中的下一个单词中进行选择。这降低了在序列中下一个选择不寻常单词的可能性。
Top P - 根据潜在选择的概率之和定义截止点。如果您将 Top P 设置为 1.0 以下,则模型会考虑最可能的选项,而忽略较少可能的选项。Top P 与 Top K 类似,但它没有限制选择的数量,而是根据选项的概率之和来限制选择的数量。对于 “I hear the hoof beats of” 的示例提示,你可能希望模型将 “horses”、“zebras” 或 “unicorns” 作为下一个单词。如果将温度设置为最大值,而不封顶 Top K 或 Top P,则会增加出现异常结果(例如 “unicorns”)的可能性。如果将温度设置为 0,则会增加 “horses” 的概率。
如果您设置一个高的温度值,并同时将 Top K 或 Top P 设置为最大值,则会增加 “horses” 或 “zebras” 的概率,并降低 “unicorns” 的概率。
- 长度(Length)
响应长度(Response length): 配置在生成的响应中使用的最小和最大 token 数。
长度惩罚(Length penalty): 长度惩罚通过惩罚较长的响应来优化模型,使其输出更加简洁。长度惩罚与响应长度不同,因为响应长度是最小或最大响应长度的硬截点。
从技术上讲,长度惩罚会对长度响应的模型造成指数级惩罚。0.0 表示没有惩罚。为模型设置一个小于 0.0 的值以生成更长的序列,或者为模型设置一个大于 0.0 的值以生成更短的序列。
- 重复度(Repetitions)
重复度参数有助于控制生成的响应中的重复性。
重复惩罚(存在惩罚):防止在响应中重复相同的单词(标记)。1.0 表示没有惩罚,大于 1.0 可减少重复次数。
2.7 测试基础模型
介绍完上面的基本设置和一些参数后,让我们来看看模型的实际应用。以下逐行运行该示例 notebook 的代码,来看看如何使用 Amazon Bedrock API 来调用测试基础模型:
Amazon Titan Large 模型调用示例
# If you'd like to try your own prompt, edit this parameter!
prompt_data = """Command: Write me a blog about making strong business decisions as a leader.Blog:
"""body = json.dumps({"inputText": prompt_data})
modelId = "amazon.titan-tg1-large"
accept = "application/json"
contentType = "application/json"response = boto3_bedrock.invoke_model( body=body, modelId=modelId, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())print(response_body.get("results")[0].get("outputText"))
我自己运行以上代码后,获得的模型输出如下:

Anthropic Claude 模型调用示例
# If you'd like to try your own prompt, edit this parameter!
prompt_data = """Human: Write me a blog about making strong business decisions as a leader.Assistant:
"""body = json.dumps({"prompt": prompt_data, "max_tokens_to_sample": 500})
# modelId = "anthropic.claude-instant-v1" # change this to use a different version from the model provider
modelId = "anthropic.claude-v2"
accept = "application/json"
contentType = "application/json"response = boto3_bedrock.invoke_model( body=body, modelId=modelId, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())print(response_body.get("completion"))
复制代码我自己运行以上代码后,获得的模型输出如下:

Stability Stable Diffusion XL 模型调用示例
prompt_data = "a fine image of an astronaut riding a horse on Mars"
body = json.dumps({ "text_prompts": [{"text": prompt_data}],"cfg_scale": 10, "seed": 20, "steps": 50
})
modelId = "stability.stable-diffusion-xl"
accept = "application/json"
contentType = "application/json"response = boto3_bedrock.invoke_model( body=body, modelId=modelId, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())print(response_body["result"])
print(f'{response_body.get("artifacts")[0].get("base64")[0:80]}...')import base64
import io
from PIL import Imagebase_64_img_str = response_body.get("artifacts")[0].get("base64")
image = Image.open(io.BytesIO(base64.decodebytes(bytes(base_64_img_str, "utf-8"))))
image
我自己运行以上代码后,获得的模型输出如下:

数据隐私和网络安全
使用 Amazon Bedrock,你可以控制自己的数据,并且所有输入和自定义设置保密。你的数据(例如输入提示、输出结果和微调模型)不会用于服务改进。此外,数据绝不会与第三方模型提供商共享。
你的数据会保留在处理 API 调用的区域。所有数据在传输过程中均使用 TLS 1.2 加密。传输完成后的静止数据(data at rest)将使用 KMS 的 AES-256 托管加密密钥进行加密。你也可以使用自己的密钥(customer managed keys)来加密数据。
可以将你自己的亚马逊云科技账户里的 VPC,配置为使用 VPC 终端节点(在PrivateLink 上构建);这种配置将通过亚马逊云科技的网络,安全地连接到 Amazon Bedrock。这种方式可以在 VPC 中运行的应用程序与 Amazon Bedrock 之间,实现安全和私密的数据通信连接。
Governance and Monitoring 治理和监测
Amazon Bedrock 与 IAM 集成,可帮助你管理 Amazon Bedrock 的权限。此类权限包括访问特定模型、访问 Bedrock 的 playground 或其它 Amazon Bedrock 的功能特性。所有亚马逊云科技托管的服务 API 活动,包括 Amazon Bedrock 活动,都将记录到你自己账户的 CloudTrail 中。
Amazon Bedrock 使用 “Amazon/Bedrock” 命名空间向 CloudWatch 发送数据点,以跟踪常见指标,例如:InputTokenCount、OutputTokenCount、InvocationLatency 和调用次数等。通过在搜索指标时指定模型 ID 维度,你可以筛选结果并获取特定模型的统计数据。
当你开始使用 Amazon Bedrock 构建生成式 AI 应用程序时,这种近乎实时的见解可以帮助你跟踪使用情况和成本(输入和输出 token 数量),并解决性能问题(调用延迟和调用次数)。
总结
本篇文章作为 Amazon Bedrock 的基础篇,介绍了使用 Amazon Bedrock 服务的两种基本使用方式:
- 在 Amazon Bedrock 控制台中使用模型
- 用 API 方式使用模型
篇幅所限,关于 Amazon Bedrock 的更高阶的功能特性,我们会在接下来的文章中继续探索和分析,敬请期待。
请持续关注 Build On Cloud 微信公众号,了解更多面向开发者的技术分享和云开发动态!
参考文献
1.Amazon Bedrock Is Now Generally Available – Build and Scale Generative AI Applications with Foundation Models
https://aws.amazon.com/blogs/aws/amazon-bedrock-is-now-genera...
2.Quickly build Generative AI applications with Amazon Bedrock
https://community.aws/posts/amazon-bedrock-quick-start?trk=cn...
3.Amazon Bedrock Workshop
https://catalog.us-east-1.prod.workshops.aws/workshops/a4bdb0...
Build On Cloud
我们是由技术布道师,社区经理,项目经理等角色组成的群体,致力于与开发者建立并维系积极的关系,进行持续的双向技术交流,以及构建充满活力的开发者社区和生态。 40篇原创内容
公众号

文章来源:
https://dev.amazoncloud.cn/column/article/6528f32f959b5d5de0b35af2?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN
这篇关于揭开 Amazon Bedrock 的神秘面纱 | 基础篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









