本文主要是介绍Django使用haystack来调用Elasticsearch进行全文检索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
django使用haystack来调用Elasticsearch搜索引擎
如何使用django来调用Elasticsearch实现全文的搜索
Haystack为Django提供了模块化的搜索。它的特点是统一的,熟悉的API,可以让你在不修改代码的情况下使用不同的搜索后端(比如 Solr, Elasticsearch, Whoosh, Xapian 等等)。
环境:django ==1.11.11
1.首先安装相关的依赖包:(这里原作者使用的是drf-haystack,如果项目没有使用drf组件,应该选用haystack包)
pip install drf-haystack
pip install elasticsearch==2.4.1
drf-haystack官方文档
2.在django项目配置文件settings.py中注册应用:
INSTALLED_APPS = ['django.contrib.admin','django.contrib.auth','django.contrib.contenttypes','django.contrib.sessions','django.contrib.messages','django.contrib.staticfiles','rest_framework', # DRF'corsheaders', # JS跨域请求问题'ckeditor', # 富文本编辑器'ckeditor_uploader', # 富文本编辑器上传图片模块'django_crontab', # 定时任务'haystack', # 对接搜索引擎 -----加这一行!!
3.在django项目配置文件settings.py中指定搜索的后端:(指定使用那个搜索引擎,服务器地址的配置,索引库的名称等配置)
Haystack
HAYSTACK_CONNECTIONS = {'default': {'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine','URL': 'http://服务器_IP:9200/', # 此处为elasticsearch运行的服务器ip地址,端口号固定为9200'INDEX_NAME': 'fkszdb', # 指定elasticsearch建立的索引库的名称},
}当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'# 指定搜索结果每页的条数 这里设置成了10条HAYSTACK_SEARCH_RESULTS_PER_PAGE = 10
注意:
HAYSTACK_SIGNAL_PROCESSOR 的配置保证了在Django运行起来后,有新的数据产生时,haystack仍然可以让Elasticsearch实时生成新数据的索引
4.创建索引类:(在需要进行索引的应用的目录下创建文件search_indexes.py, 在该文件内创建该索引类,
索引模型类的名称必须是 模型类名称 + Index
from haystack import indexesfrom .models import SPUclass SPUIndex(indexes.SearchIndex, indexes.Indexable):"""SKU索引数据模型类"""# document=True,表名该字段是主要进行关键字查询的字段, 该字段的索引值可以由多个数据库模型类字段组成(是多个字段,不是多个数据库模型类),具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明,其他字段都是通过model_attr选项指明引用数据库模型类的特定字段。text = indexes.CharField(document=True, use_template=True)def get_model(self):"""返回建立索引的模型类"""return SPUdef index_queryset(self, using=None):"""返回要建立索引的数据查询集"""return self.get_model().objects.all()# return self.get_model().objects.filter(is_launched=True)5.在项目的urls.py中添加url
urlpatterns = [...Re_path(r'^search/', include('haystack.urls')),
]
6.在目录“templates/search/indexes/shopadmin/”下创建“模型类名称_text.txt”文件 #spu_text.txt,这里列出了要对哪些列的内容进行检索
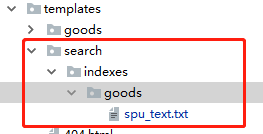
{{ object.name }}
{{ object.description }}
7.建立ChineseAnalyzer.py文件 保存在haystack的安装文件夹下,路径如“python环境下/lib/python3.6/ /site-packages/haystack/backends/”
import jieba
from whoosh.analysis import Tokenizer, Tokenclass ChineseTokenizer(Tokenizer):def __call__(self, value, positions=False, chars=False,keeporiginal=False, removestops=True,start_pos=0, start_char=0, mode='', **kwargs):t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs)seglist = jieba.cut(value, cut_all=True)for w in seglist:t.original = t.text = wt.boost = 1.0if positions:t.pos = start_pos + value.find(w)if chars:t.startchar = start_char + value.find(w)t.endchar = start_char + value.find(w) + len(w)yield tdef ChineseAnalyzer():return ChineseTokenizer()
8.复制whoosh_backend.py文件,改名为whoosh_cn_backend.py 注意:复制出来的文件名,末尾会有一个空格,记得要删除这个空格
from .ChineseAnalyzer import ChineseAnalyzer
查找
analyzer=StemmingAnalyzer()
改为
analyzer=ChineseAnalyzer()
9.生成索引 初始化索引数据
python manage.py rebuild_index
10.子应用 创建serializers.py —并创建序列搜索序列化类
class SPUIndexSerializer(HaystackSerializer):"""SPU索引结果数据序列化器"""object = SPUSerializer(read_only=True)class Meta:index_classes = [SPUIndex]fields = ('text', 'object')
- 新建一个API 继承HaystackViewSet:
# 搜索
class SPUSearchViewSet(HaystackViewSet):"""SKU搜索"""# 返回json重写父类def options(self, request, *args, **kwargs):"""Handler method for HTTP 'OPTIONS' request."""if self.metadata_class is None:return self.http_method_not_allowed(request, *args, **kwargs)data = self.metadata_class().determine_metadata(request, self)return JsonResponse(data, status=status.HTTP_200_OK)def retrieve(self, request, *args, **kwargs):instance = self.get_object()serializer = self.get_serializer(instance)return JsonResponse(serializer.data, safe=False)def list(self, request, *args, **kwargs):queryset = self.filter_queryset(self.get_queryset())page = self.paginate_queryset(queryset)if page is not None:serializer = self.get_serializer(page, many=True)return self.get_paginated_response(serializer.data)serializer = self.get_serializer(queryset, many=True)return JsonResponse(serializer.data, safe=False)def get_paginated_response(self, data):"""Return a paginated style `Response` object for the given output data."""assert self.paginator is not Nonereturn JsonResponse(self.paginator.get_paginated_response(data, safe=False))# 禁用分页pagination_class = None# 索引以 SPU表index_models = [SPU]# 这里的SPUIndexSerializer 是自定义的序列化类serializer_class = SPUIndexSerializer至于前端我们使用的是小程序,具体不从得知, 百度吧
Elasticsearch 的安装, 我使用docker 拉取的也自行百度吧
这篇关于Django使用haystack来调用Elasticsearch进行全文检索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







