本文主要是介绍TiDB 在2021汽车之家818全球汽车夜的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文来源: https://tidb.net/blog/12f7c8b5
【是否原创】是
【首发渠道】TiDB 社区
【正文】
作者:
靳献旗 汽车之家高级 DBA
张 帆 汽车之家业务架构师
1、背景介绍
汽车之家 (NYSE:ATHM) 成立于 2005 年,目前是全球访问量最大的汽车网站,为消费者提供优质的汽车消费和汽车生活服务。
“818 全球汽车节” 是由汽车之家与湖南卫视联手打造的汽车行业顶级盛典,今年已经成功举办三届。“818 全球汽车节” 就像是电商中的双十一、618 一样,是专为购车用户打造的节日狂欢,并在"818 全球汽车夜"电视直播和 APP 活动同步达到高峰,为 8 月的汽车行业带来了一场购车盛宴。

2、业务场景介绍
本次 818 活动中,TiDB 的主要应用场景是台网互动项目,该项目通过台上与线上相结合、晚会与 App 互动的形式,让广大用户在欣赏精彩节目的同时,参与到秒杀、抽奖等活动当中。
作为整场晚会的亮点,一元秒杀车、红包抽奖以及超级大锦鲤等活动,自然是用户参与度最高,峰值流量出现的环节。更因为活动涉及到金融支付、用户权益兑现等业务,其背后的系统设计首要考虑的就是数据的一致性、安全性。此外,在晚会期间我们也需要秒级准实时数据播报,包含用户参与人数、互动次数、奖品发放情况等。由此看来,在整个系统设计中,一款强大的数据库是必不可少的重要组件,而支持两地三中心部署、HTAP 的 TiDB 5.0 便进入了我们的视线。
3、数据库选型
818 全球汽车节作为公司战略级项目,不允许有一点闪失。为了应对流量暴涨和突发异常情况,各大部门协作进行了十轮全链路压测及双活演练。
历数往年 818,2019 年数据库使用的是 MySQL,2020 年换成了分布式 NewSQL 数据库 TiDB,有了 2020 年的使用经验及参考,2021 年我们首先考虑的便是 TiDB ,经过与 PingCAP 技术同学几轮电话会议和面对面沟通,对业务形式和数据库使用场景充分交换了意见,使得我们更坚定的选择了 TiDB。而 TiDB 5.0 金融级高可用,实时 HTAP ,两地三中心的部署架构也符合我们的业务需求。
这里顺便提一下,项目中使用到的所有基础组件,包括 Kafka,Redis,ES 都是分布式的,上层 Nginx 使用 LVS 做负载均衡可以水平扩展,各个组件做了跨可用区部署,因此使用分布式数据库也成了自然选择。
4、架构描述
818 期间我们使用了国内一线云厂商高速云主机部署 TiDB 集群 ,云主机分布在北京 A 区、C 区、D 区,多 IDC 部署,采用同城三中心,五副本架构。
相比 2020 年,今年架构的最大特点是:所有组件实现了跨区高可用,包括 TiFlash,TiCDC,而且 TiFlash 引入了 MPP 架构。
4.1、架构简介
同城三数据中心方案,即同城有三个机房部署 TiDB 集群,同城三数据中心间的数据同步通过集群自身内部(Raft 协议)完成。同城三数据中心可同时对外进行读写服务,任意一个数据中心故障时,集群能自动恢复服务,不需要人工介入,并能保证数据一致性。
4.2、集群架构
818 TiDB 整体架构图如下,最上层是 LVS,未在图中展示。
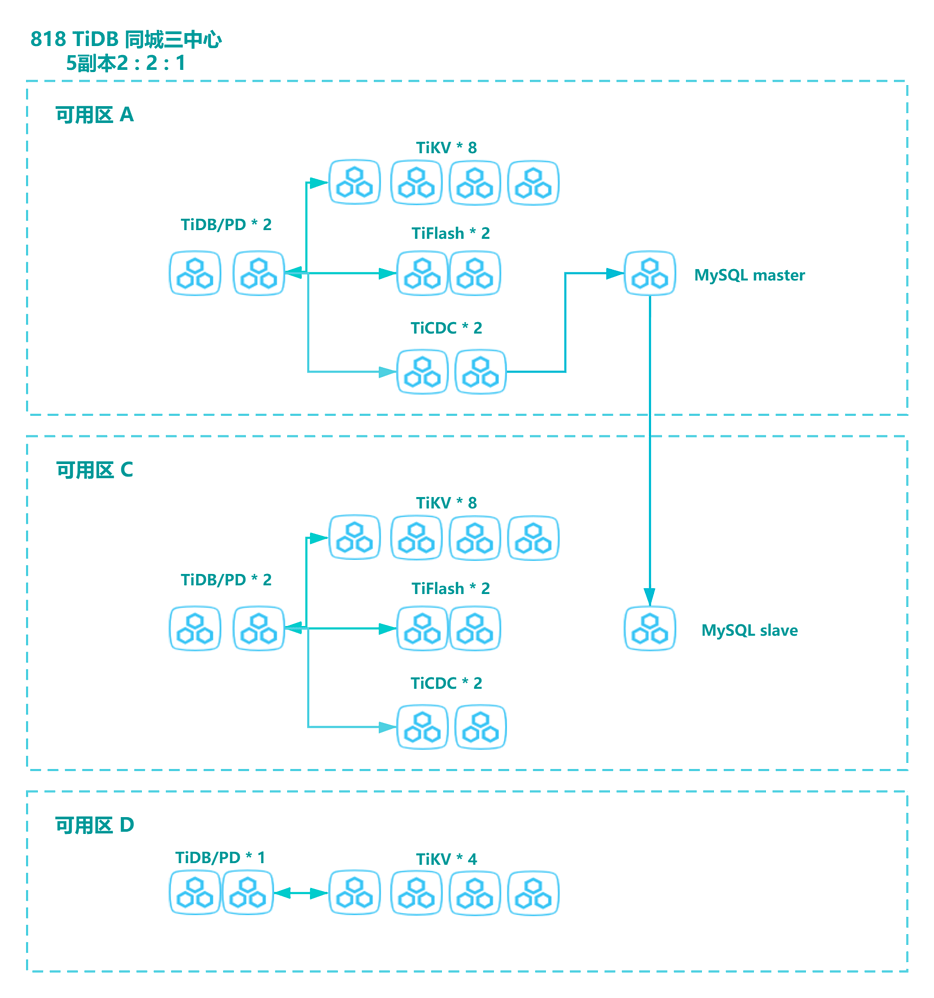
下面将对图中的架构进行说明:
- 本次 818 项目中使用了 TiDB 最新的版本 5.1.1,MySQL 的版本是 Percona 5.7.25。
- TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,主要用于 OLAP 业务。TiFlash 跨区部署提高容灾能力,我们利用 TiFlash 解决统计分析类的 SQL,实时展示在大屏。
- TiCDC 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,具有将数据还原到与上游任意 TSO 一致状态的能力,支持其他系统订阅数据变更。 TiCDC 跨区部署, 将 TiDB 集群数据实时同步至下游的 MySQL 数据库,作为故障应急的备份,实现业务容灾能力的提升。
- MySQL 跨区部署主从,作为 TiDB 集群的应急,降级之用,实现业务容灾能力的提升。
另外,TiDB 5.1.1 版本的新特性也给我们带来了一些惊喜,比如 TiFlash MPP 架构为大屏近实时展示提供了强有力的支撑,Async Commit 特性有效降低了某些事务提交的延迟:
- TiFlash MPP 架构
TiDB 从 5.0 版本开始通过 TiFlash 节点引入了 MPP 架构,使得大型表连接类查询可以由不同 TiFlash 节点共同分担完成,把计算压力分摊到各个 TiFlash 执行节点,从而达到加速计算的目的。v5.1.1 版本相比 5.0 版本又添加了更多函数的支持,比如 count distinct 场景的下推函数,经过测试,相比 5.0 版本的 count distinct 有 3 倍+的性能提升。
- Async Commit 特性
数据库的客户端会同步等待数据库通过两阶段 (2PC) 完成事务的提交。开启 Async Commit 特性后事务两阶段提交在第一阶段提交成功后就会返回结果给客户端,第二阶段会在后台异步执行。通过事务两阶段异步提交的方式降低事务提交的延迟。
5、遇到问题及解决方案
818 前期,我们和业务方一起做了充分的测试,包括异常测试,性能测试等。这里提一下,压测工具我们除了使用 Sysbench 工具外,还使用了更贴近业务的仿真压测程序及 QA 模拟完整真实业务流程的压测。
在压测期间,我们遇到一些典型问题,这些问题最终在 PingCAP 小伙伴的帮助下得到解决,这里简单做下描述并给出解决方案或者最佳实践。
5.1、索引热点问题
我们使用仿真程序压测(10 台压测服务器,每台 200 并发)单张业务表的写入性能时,表的主键是 AUTO_RANDOM,在没任何二级索引的情况下,单表写入可达 10 万 TPS(非批量写入),性能曲线请见下图,其中图 1 是我们自己开发的一个统计 TiDB TPS 的工具,每两秒采点一次记录到 Redis。图 1 和图 2 是不同时间测试的截图。
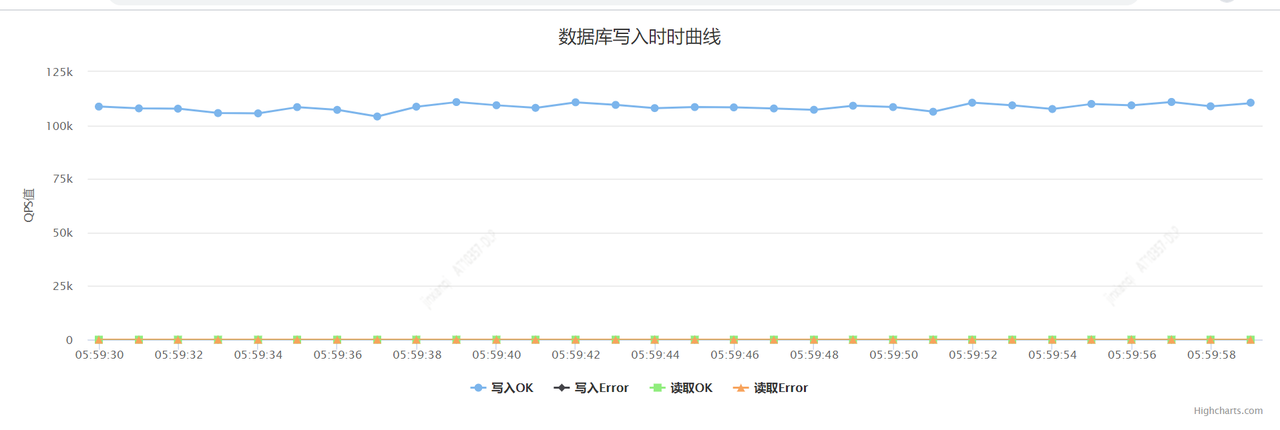
图1
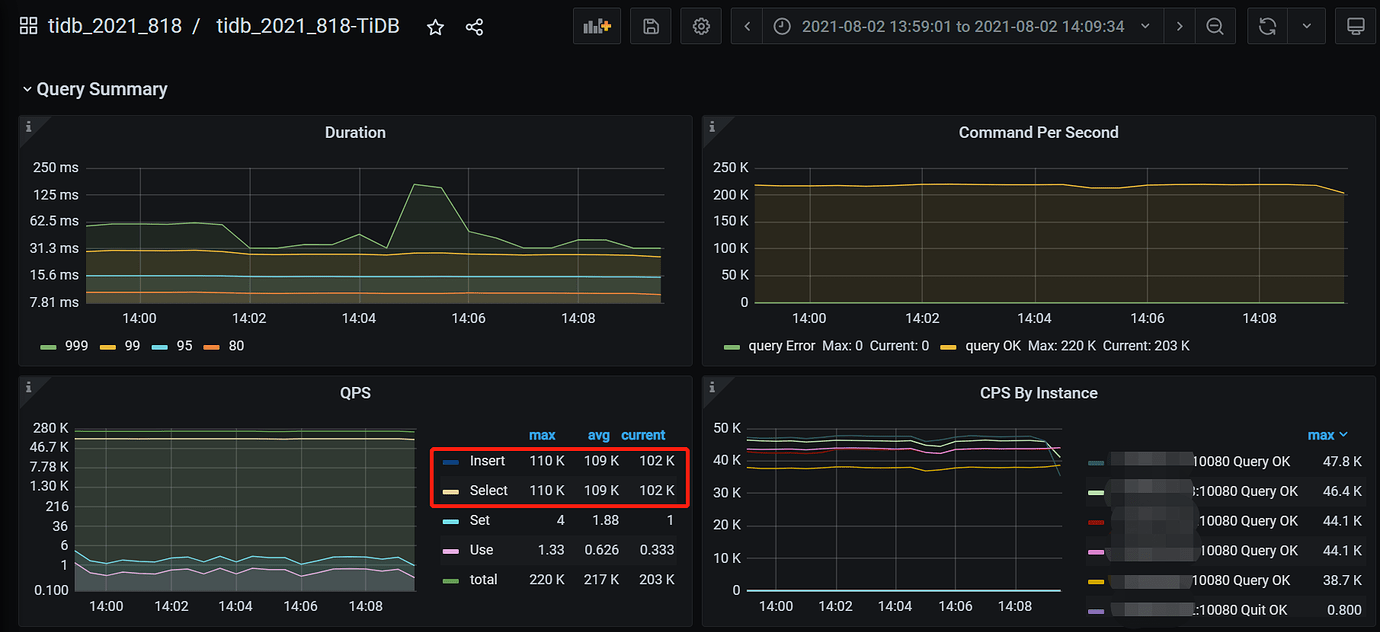
图2
但是,当表中添加一个 user_id 的二级索引后,TPS 迅速下降至 2 万 TPS。通过分析,是索引热点导致的 TPS 严重下降。
解决办法:
表结构添加一个哈希字段提前打散索引上因连续值而带来的热点。
(1) 业务方配合将索引业务列进行 mod 256 取模操作,并向新加列 user_id_hash 填充取模数据 0 ~ 255 hash 结果数。
(2) 在 hash 列 user_id_hash 和原有业务列 user_id 上建立联合索引,使底层索引存储的 Key 值实现打散效果。
按照上面方法优化后,再次压测,TPS 可以达到 5 万+ TPS,距离之前的 10 万 TPS 还差一倍,为什么仅添加一个二级索引对 TPS 影响如此之大?
5.2、2PC 问题
回到上一小节遗留的问题:为什么向表中添加一个二级索引后,TPS 从 10 万降低到 5 万?为什么二级索引对 TPS 影响如此之大?
原因如下:
(1) 当一个事务涉及的 Key 分布在不同 Region 里时,就没办法走 1PC 。由于 TiDB Key 的编码规则,索引和数据前缀不一样,很容易就会落在不同 Region 里,由于前面做了打散,一个事务涉及的 Key 都分布在不同的 Region 里,所以走的 2PC。
(2) 加索引以后走 2PC 天然要比 1PC 慢,从 QPS 来看 2PC 下发到 TiKV 的请求多了 3 倍(Prewrite 变成 1 Prewrite + 1 Commit,1 Key 变成 2 Key)资源消耗也更多。
(3) 2PC 下 GRPC 由于处理更多的请求,已经成为瓶颈(默认 5 线程,400% 多的使用率),增加更多的线程可以减小下降的幅度,建议将 GRPC 调整为 8。
下图是表中只有主键时的事务类型监控,可以看到产生了大量 1PC 的事务。
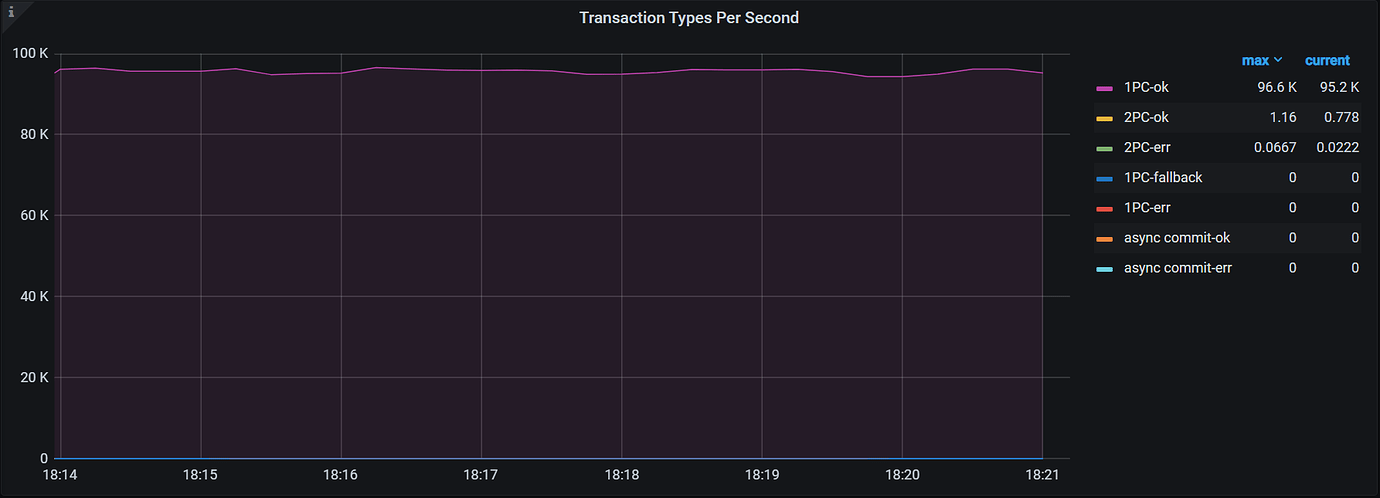
下图是表包含一个二级索引时的事务类型监控,可以看到 1PC 事务数是 0。
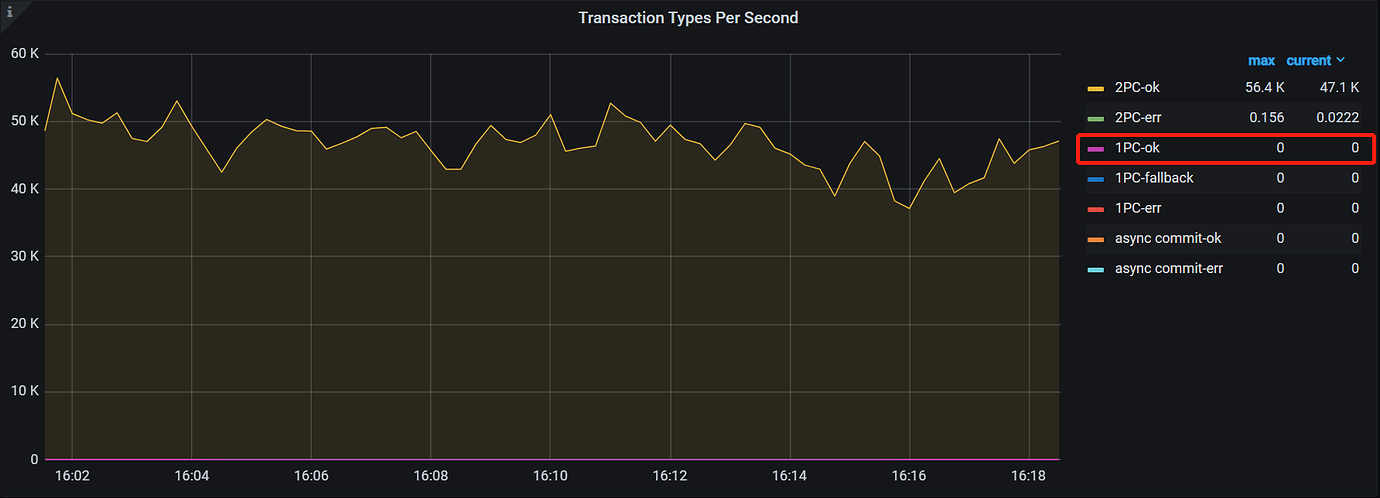
解决办法:
这个问题在数据库层面暂时无解,涉及到 TiDB 底层编码,改动较大,官方后续会做优化。业务上采用批量写优化这个问题。
5.3、TiCDC 节点 TPS 不均衡
5.1.1 版本的 TiCDC 性能很强劲,同步速度高达 13 万行每秒,但是某些节点 TPS 相差几十倍,如下图所示:
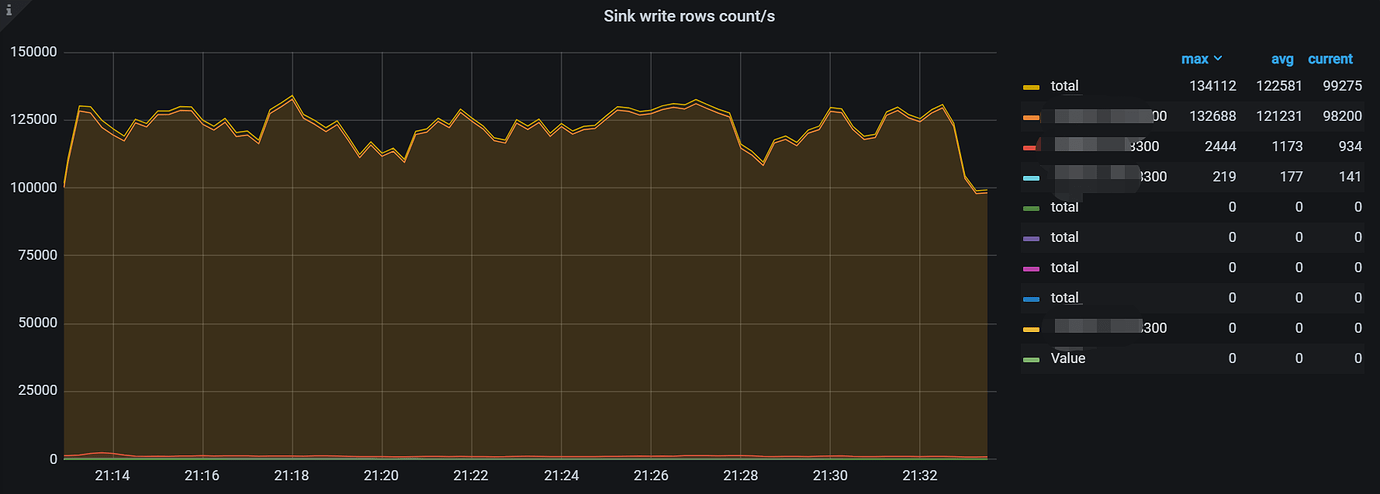
问题原因:
将 TiDB 数据通过 TiCDC 向下游 MySQL 同步时,只建立了一个 Changefeed,导致表在各个节点分配不均,多张大表全部落在同一个 TiCDC 节点上,导致这个节点的 TPS 非常高,其它 TiCDC 节点低的现象。
解决办法:
提前规划,创建多个 Changefeed ,将各个大表手动均匀分配到不同 TiCDC 节点。
5.4、最佳实践
在本次 818 项目中,我们也总结了一些最佳实践,希望能给有类似场景的用户提供参考:
- 同城三中心五副本架构,机房之间延迟应当尽量小,最好控制在 2ms 以内。
- OLTP 的业务,通常压测瓶颈在于 TiKV 的磁盘 IO 上,对于普通 SSD ,可以做成 RAID0 来提升 IOPS。
- 一旦某个可用区整体故障,正常不需要手动干预,但是为了避免性能下降严重,建议手动将五副本调整为三副本。
- 合理设计表结构和索引,尽量避免热点问题,和业务一起做好充分压测,压测期间尽早发现问题并优化。
6、晚会期间集群表现
TiDB 同城三中心架构在 818 晚会期间顺利的支撑了业务,运行稳定,下面是晚会期间集群的表现:
(1) TiDB 峰值每秒近 40 万行的写入,SQL 99 在 30ms 以下。
(2) TiCDC 性能表现强劲,向下游 MySQL 同步速度高达 13 万行每秒 。
(3) 跨中心的 TiFlash MPP 架构,为大屏近实时展示助力总次数,秒杀和摇奖的每轮参与用户等信息提供了强有力的支撑。
(4) 顺利支撑了晚会期间 APP 用户 9048 万次互动。
7、展望
TiDB 同城三中心架构具备很多优点:
- 五副本,多 IDC 部署,金融级高可用。
- 实时 HTAP ,一站式解决 OLTP 和 OLAP 业务。
- 一键水平扩容或者缩容。
- TiCDC 高可用,低延迟,支持大规模集群。
在测试 TiDB 同城三中心期间和使用过程中也发现一些小问题,相信这些问题官方在不久的将来都会得到解决,也希望 TiDB 越来越好。
- 无法查看集群每秒的写入行数
希望 TiDB 可以提供类似 MySQL Innodb_rows_deleted/Innodb_rows_inserted/Innodb_rows_updated 等统计信息,可以很方便的查看集群每秒写入的行数。
- TiCDC 稳定性有待提升
TiCDC 的稳定性有待进一步提升,在使用过程中发现偶尔产生同步中断的情况,例如 truncate 表可能导致同步中断。
- TiCDC 小 Bug
测试过程中发现,当关闭 A 区所有的 TiDB、PD、TiKV、TiFlash、TiCDC 节点后,C 区的 TiCDC 同步任务中断,官方已经确认这是 TiCDC 的一个 Bug。
8、感谢
818 晚会的完美举行,离不开苏丹、王贤静、东玫、陈乃琦、李仲舒等 PingCAP 小伙伴在测试过程中的帮助和建议,多次来汽车之家面对面沟通交流,对每一个细节精雕细琢,及时的解决了测试过程中遇到的难题和 Bug,并亲临 818 全球超级车展指挥中心现场,为 818 全球汽车夜保驾护航,在此表示衷心的感谢。
这篇关于TiDB 在2021汽车之家818全球汽车夜的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






