本文主要是介绍【三维重建】DreamGaussian:高斯splatting的单视图3D内容生成(原理+代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 摘要
- 一、前言
- 二、相关工作
- 2.1 3D表示
- 2.2 Text-to-3D
- 2.3 Image-to-3D
- 三、本文方法
- 3.1生成式 高斯 splitting
- 3.2 高效的 mesh 提取
- 3.3 UV空间的纹理优化
- 四. 实验
- 4.1实施细节
- 4.2 定性比较
- 4.3 定量比较
- 4.4 消融实验
- 总结(特点、局限性)
- 五、安装与使用、代码解析
- 5.1 环境配置
- 5.2 如何使用:单张图/文本-生成3D
- 5.3 代码解析
- 01.rembg 库,自动剪掉背景
- 02.self.prepare_train()
- 03.生成位姿信息
- 04. gaussians光栅化器的渲染
- 04. loss损失:
- 扩展
- 1.Marching cubes算法
项目主页:https://dreamgaussian.github.io/
(包含论文和代码)
提示:以下是本篇文章正文内容,下面案例可供参考
摘要
常用的3D内容创建方式,主要是利用基于优化的通过分数蒸馏采样(SDS)进行的3D生成。该方法每个样本优化较慢,很难实际应用。本文提出了DreamGaussian,兼顾效率和质量:设计一个生成的三维高斯splitting 模型,并在 uv 空间中配合网格提取和纹理细化。与NeRF中使用的 occupancy pruning 相比,三维高斯分布的渐进致密化收敛速度明显更快。为了进一步提高纹理质量,促进下游应用,我们引入了一种高效的算法,将三维高斯矩阵转换为纹理网格,并应用一个微调阶段来细化细节。
一、前言
自动3D数字内容生成 可以发现跨不同领域的应用程序,包括数字游戏、广告、电影和元语言。核心技术,包括图像到3D和文本到3D,通过显著减少了专业艺术家对手工劳动的需求,并授权非专业用户参与3D资产的创造,提供了实质性的优势。有益于2D内容生成(Rombach et al.,2022),3D内容创作领域经历了快速的发展。最近关于三维生成的研究可以分为两大类:仅限推理的三维原生方法和基于优化的二维提升方法。3D原生方法(Jun & Nichol,2023;Nichol等人,2022;Gupta等人,2023)显示出在几秒钟内生成3D一致的潜力,代价是需要在大规模3D数据集上进行广泛的训练。这种数据集仍然缺少,且缺少多样性,和现实分布有很大偏差。
另一方面, Dreamfusion 提出分数蒸馏抽样(SDS)解决三维数据限制,通过提取三维几何和外观从强大的2D扩散模型,激发了最近的2D提升方法的发展。为了应对SDS监督引起的不一致和模糊性,通常采用NeRF建模丰富的三维信息的能力。但由于NeRF渲染费时,优化需要数小时。用于加速NeRF的 occupancy pruning 技术在模糊SDS损失的监督下,在生成环境中是无效的。
DreamGaussian 通过细化在一个基于优化的管道中的设计选择,大大提高了3D内容的生成效率。使用我们的方法,可以在仅2分钟内从单个视图图像中生成具有显式网格和纹理贴图的逼真3D物体。我们的核心设计是将三维高斯 splitting 应用到生成设置中,并配合网格提取和纹理细化。以往的NeRF表示方法难以有效地修剪空白空间,高斯 splitting 显著简化了优化形式。具体地说,我们演示了高斯分裂的渐进致密化,它高度符合生成设置的优化进程,大大提高了生成效率,单个GPU上以大约500步有效地收敛。
由于SDS监督和空间致密化的模糊性,从三维高斯分布中直接生成的结果趋于模糊。为了解决这个问题,我们确定纹理需要明确地细化,这需要从生成的三维高斯模型中提取精细的纹理多边形网格。虽然这一任务以前没有被探索过,但我们设计了一种有效的算法,从网格提取三维高斯通过局部密度查询。然后提出了一个生成的 UV空间细化阶段来增强纹理细节。考虑到在第一阶段直接应用潜在空间SDS损失会导致UV图上过饱和的块状伪影,借鉴了基于扩散的图像编辑方法 Sdedit,并进行图像空间监督。与以往的纹理细化方法相比,我们的细化阶段在保持高效率的情况下获得了更好的保真度。
综上所述,贡献如下:
1.提出了一种新的三维内容生成模型,通过将高斯splittinig 应用到生成设置中,显著减少了基于优化的二维提升方法的生成时间。
2.设计了一种高效的三维高斯网格提取算法和 UV空间网格细化阶段,以进一步提高生成质量。
3.在Image-3D, 以及text-3D任务上的大量实验表明,方法有效地平衡了优化时间和生成保真度。
二、相关工作
2.1 3D表示
NeRF 采用体渲染,在只有二维监督下实现三维优化。虽然NeRF已广泛应用于三维重建和生成,但优化NeRF可能耗费时间。InstantNGP等NeRF加速工作,只关注重建;常用的空间剪枝技术并不能加速生成设置。今年,三维高斯 splitting 作为NeRF的替代三维表示方法,显示出了令人印象深刻的质量和速度。高效的可微渲染实现和模型设计可以在不依赖空间剪枝的情况下进行快速训练。在这项工作中,我们首次将三维高斯 splitting 纳入生成任务,以释放基于优化的方法的潜力。
2.2 Text-to-3D
文本到3D的生成旨在从文本提示符生成3D物体。最近,数据驱动的二维扩散模型在文本到图像生成方面取得了显著的成功(DDPM等生成模型)。然而,由于管理大规模的3D数据集的挑战,将其转移到3D生成并不是一件很简单的事情。现有的三维原生扩散模型通常针对单一的对象类别,多样性有限。为了实现开放词汇表的三维生成,一些方法用于提升二维图像模型进行三维生成,如 dream fields、 Dreamfusion、 Score jacobian chaining、 Clip-mesh、Text2mesh:等。这种二维提升方法对三维表示进行优化,在预先训练的二维扩散模型中实现高可能性,从而保证三维的一致性和实现性。接下来的工作继续提高各个方面,如生成保真度和训练稳定性。然而,这些方法通常存在长时间优化时间的问题。特别是,使用NeRF作为三维表示会导致在正向和向后时进行昂贵的计算。
2.3 Image-to-3D
图像到3D的生成目标,也可以表述为单视图三维重建,但由于缺乏不确定性建模,这种重建设置通常会产生模糊的结果。文本到3D方法也可用于图像到3D生成。最近,Zero-1-3明确地将相机转换为二维扩散模型,并实现了zero shot 图像条件下的新视图合成。当与SDS结合时,它实现了较高的3D生成质量,但优化时间仍然较长。One-2-3-45(Liu et al.,2023a)训练了一个多视图重建模型,以牺牲生成质量为代价进行加速。
三、本文方法
在本节中,我们将介绍我们的两阶段框架。首先,我们将三维高斯 splitting应用到生成任务中,以便通过SDS有效地初始化(第3.1节)。接下来,我们提出了一种从三维高斯模型中提取纹理网格的有效算法(第3.2节)。然后通过可微渲染,通过uv空间细化阶段(第3.3节)对该纹理进行微调,以进行最终输出。
3.1生成式 高斯 splitting
高斯 splitting 用一组三维高斯分布表示三维信息。在与NeRF相似的建模时间下,具有较高的推理速度和重建质量。具体地说,每个高斯分布的位置可以用一个中心点 x∈R3、一个比例因子 s∈R3 和一个旋转四元数 q∈R4 来描述。我们还存储了一个不透明度值α∈R和一个颜色特征 c∈R3,用于体渲染。球面谐波被禁用了,因为我们只想建模简单的漫反射颜色。以上所有可优化的参数均由Θ给出,其中 Θi = {xi,si,qi,αi,ci} 是第i个高斯分布的参数。 渲染:将一组三维高斯分布以二维高斯分布的形式投影到图像平面上。然后按前后深度的顺序对每个像素进行体积渲染,以评估最终的颜色和alpha。在这项工作中,我们使用了Kerbl等人(2023年)提供的高度优化的渲染器来优化Θ。
我们在一个球体内,初始化三维高斯与随机位置采样,进行单位缩放,不进行旋转。这些三维高斯分布在优化过程中被周期性地密集化。与重建不同的是,我们从更少的高斯分布开始,但更频繁地密集化它,以与生成进程相一致,并使用SDS优化三维高斯分布。每一个epoch,对一个围绕物体中心旋转的随机摄像机姿态p进行采样,并渲染当前视图的RGB图像 IpRGB 和透明度 IpA。与 Dreamtime 类似,我们线性地减少时间步长t,用于对添加到渲染的RGB图像中的随机噪声ϵ进行加权。然后,利用不同的二维扩散先验ϕ来引导SDS去噪步骤,并反向传播到三维高斯分布。
Image-to-3D.
对于图像到3D任务,图像 I ‾ \overline{\text{I}} IrRGB 和前景掩模 I ‾ \overline{\text{I}} IrA 作为输入。采用 zero 1-3 XL作为二维扩散先验。SDS loss计算如下:
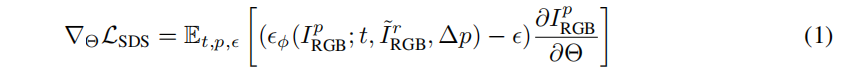 其中,ϵϕ(·) 是二维扩散先验 ϕ 预测噪声,∆p为与参考相机 r的相对姿态变化。此外,我们也优化了参考视图图像IrRGB 和透明度 IrA,以与输入对齐:
其中,ϵϕ(·) 是二维扩散先验 ϕ 预测噪声,∆p为与参考相机 r的相对姿态变化。此外,我们也优化了参考视图图像IrRGB 和透明度 IrA,以与输入对齐:
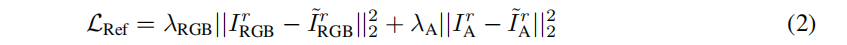
最终损失是上述三项损失的加权和。
Text-to-3D.
从文本到3d的输入是一个单一的文本提示符,SDS损失可表述如下,e是输入文本描述的CLIP嵌入:
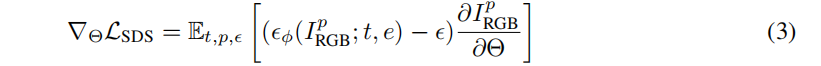
Dissusion.
我们观察到, 即使使用较长的SDS训练迭代,生成的高斯分布往往看起来模糊,缺乏细节。这可以用SDS损失的模糊性来解释。由于每个优化步骤都可能提供不一致的三维指导,因此算法很难像在重建时那样正确地强化欠重建区域或修剪欠重建区域。这一观察结果导致我们进行以下网格提取和纹理细化设计。
3.2 高效的 mesh 提取
多边形网格(Polygonal mesh)是一种广泛应用的三维表示方法,特别是在工业应用中。许多以前的工作将NeRF表示导出为基于mesh 的表示,用于高分辨率的微调。 我们试图将生成的三维高斯矩阵转换为网格,并进一步细化纹理。由于空间密度是由大量的三维高斯分布来描述的,因此对密集的三维密度网格的强力查询可能是缓慢和低效的。也不清楚如何提取3D外观,因为颜色混合仅用投影的二维高斯数定义。本文提出了一种基于 block-wise的局部密度查询 和 反投影颜色的有效纹理网格提取算法。
Local Density Query 局部密度查询
为了提取网格的几何形状,需要一个密集的密度网格来应用Marching Cubes算法(算法解释见最后)。高斯 splitting 算法的一个重要特征是在优化过程中,过大的高斯分布会被分割或修剪。这是tile-based 的高效网格化筛选技术的基础。我们还利用这个特性来执行 block-wise 的密度查询。
我们首先将 (−1,1)3 的三维空间划分为163 个块,然后剔除中心位于每个局部块外的高斯函数。这有效地减少了在每个块中要查询的高斯函数的总数。然后,我们在每个块内查询一个83 个密集的网格,从而得到一个最终的1283 个密集的网格。对于网格位置 x 处的每个查询,我们将每个保持三维高斯分布的加权不透明度相加:
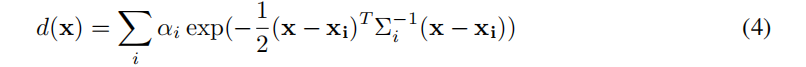
其中,Σi 为由缩放si 和旋转qi 建立的协方差矩阵。然后使用一个经验阈值,通过Marching Cubes 提取网格表面。采用分解和重新划分 (Decimation and Remeshing) 对提取的网格进行后处理,使其光滑。
Color Back-projection 颜色逆投影
由于我们已经获得了网格几何图形,因此我们可以将渲染的RGB图像反向投影到网格表面,并将其贴为纹理。我们首先展开mesh的UV坐标(Young,2021),并初始化一个空的纹理图像。然后我们统一选择8个方位角和3个高度,加上顶部和底部视图来渲染相应的RGB图像。
这些RGB图像中的每个像素都可以根据UV坐标反向投影到纹理图像上。根据(Richardson等人2023),我们排除了具有小相机空间z方向法线的像素,以避免网格边界上的不稳定投影。这个反向投影的纹理图像作为下一个网格纹理微调阶段的初始化。
3.3 UV空间的纹理优化
由于SDS优化的模糊性,从三维高斯模型中提取的 mesh 通常具有模糊的纹理,如下图所示(SDS损失为UV空间纹理优化产生伪影,而提出的MSE损失避免了这种情况。)。因此, 我们提出了第二个阶段来细化纹理图像。然而,用SDS损失直接微调uv空间往往会导致伪影,这在以前的工作中也可以观察到(Liao et al.,2023)。这是由于在可微分栅格化中使用的mipmap纹理采样技术(Laine等人,2020年)。在像SDS这样的模糊指导下,传播到每个mipmap级别的梯度会导致过饱和的颜色块。

我们从 图像到图像的合成算法SDEdit(Meng et al., 2021) 和重建设置中获得灵感。我们已经有了初始化纹理,可以从任意相机视图p渲染模糊图像 Ipcoarse。然后使用随机噪声对图像进行扰动,并使用二维扩散先验执行多步去噪过程 fϕ(·),获得细化的图像:
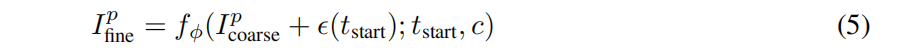
其中ϵ(tstart)是时间步长的随机噪声,c是 image-to-3D任务中的∆p(像机位姿变化),e是text-to-3D。一开始时间步长被精心选择,以限制噪声强度,因此 细化后的图像可以在不破坏原始内容的情况下增强细节。然后使用这个改进的图像通过像素级的MSE损失来优化纹理:

对于 image-to-3D 任务,我们仍使用公式2中的原图 RGBA 损失。大多数情况下,大约50个步骤可以得到很好的细节,而更多的迭代可以进一步增强纹理的细节。
四. 实验
4.1实施细节
第一阶段训练500步,为第二阶段训练50步。在一个半径为0.5的球体内,三维高斯分布被初始化为0.1的不透明度和灰色。高斯 splitting 的渲染分辨率从64增加到512,网格的渲染分辨率从128随机采样到1024。在训练期间,RGB和透明度的损失权重从0到104和103呈线性增加。我们以固定半径为2的 image-to-3D任务,text-to-3D为2.5,y轴FOV为49度,方位角在[−180,180]度,标高在[−30,30]度。背景被随机渲染为白色或黑色的高斯 splitting。
对于 image-to-3D 任务,两阶段的每阶段大约需要1分钟。我们通过背景去除对输入图像进行预处理(Qin et al.,2020),三维高斯分布用5000个随机粒子初始化,每100步密集化。
对于text-to-3D 任务,由于稳定扩散(Rombach et al.,2022)模型使用的512×512的分辨率更大,每个阶段大约需要2分钟才能完成。用1000个随机粒子初始化三维高斯分布,并每50步对它们进行密集化。
对于mesh 提取,使用Marching Cubes.的经验阈值为1。实验使用NVIDIA V100(16GB)GPU。
4.2 定性比较
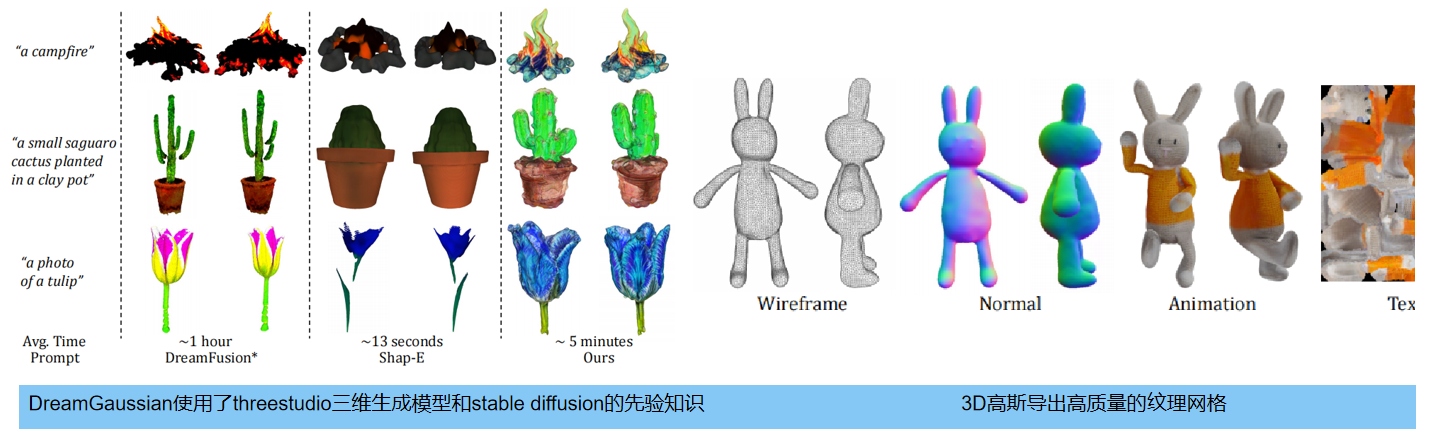
下图 提供了image-to-3D 的定性比较。与基于优化的方法(Zero-1-to-3:Liu et al.,2023b)和仅基于推理的方法( One-2-3-45: Liu et al.,2023a; Shap-e:Jun & Nichol,2023)三个基线进行了比较,所有生成模型导出为带有顶点颜色或纹理图像的多边形mesh,并在环境照明下渲染它们。 生成速度方面,本方法比基于优化的方法显示出显著加速;生成模型的质量方面,本方法优于仅推理的方法,特别是在三维几何的保真度和视觉外观方面。我们的方法在生成质量和速度之间取得了更好的平衡,达到了与基于优化的方法相当的质量,但仅比仅进行推理的方法略慢。

下图左 比较了 text-to-3D 的结果。本方法比基于推理的方法获得更好的质量,比其他基于优化的方法获得更快的速度。此外,我们还在下图右中突出显示了我们导出的mesh的质量:具有均匀的三角化、平滑的表面法线和清晰的纹理图像,使它们非常适合无缝集成到下游应用程序中。例如,利用Blender(社区,2018)等软件,我们可以很容易地将这些 mesh 用于操纵和动画的目的。
4.3 定量比较
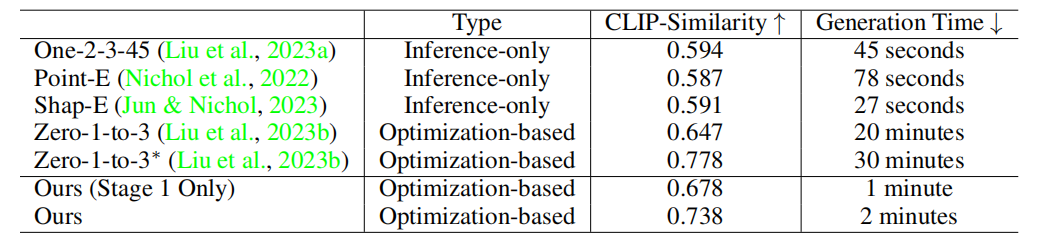
表1报告了 CLIP 相似度 和不同的 image-to-3D 方法的平均生成时间。表2中详细介绍了生成质量进行了用户研究。本研究以评估参考视图的一致性和整体生成质量为中心。与仅进行推理的方法相比,我们的两阶段结果获得了更好的视图一致性和生成质量。虽然mesh 质量略落后于其他基于优化的方法,但达到了超过10倍的显著加速。
以下是用户评分结果

4.4 消融实验
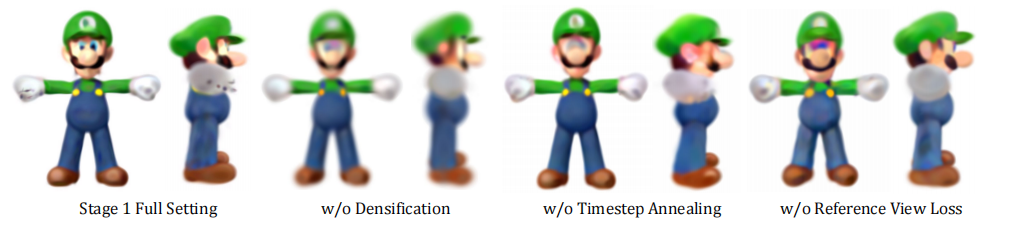
下图是烧蚀实验结果,包括三个方面: 1)三维高斯分布的周期性致密化。2)对SDS损失的时间步长t的线性退火。3)参考视图损失 LRef 的影响。我们的研究结果显示,遗漏任何一个这些设计元素都会导致在第一阶段生成的模型的质量下降。具体来说,最终的高斯分布表现出更多的模糊度和不准确性,这进一步影响了第二个微调阶段。
总结(特点、局限性)
DreamGaussian,一个3D内容生成框架,显著提高了3D内容生成的效率。特点是:
1)设计了一种高效的三维生成的生成高斯 splitting 管道。
2)提出了一种mesh 提取算法,可以有效地从三维高斯模型中推导出纹理 mesh 。
3)通过我们的纹理微调阶段,我们的工作可以在几分钟内从单个图像或文本描述中生成具有高质量多边形网格的随时可以使用的3D assets
缺点
我们与以前的 text-to-3d 工作有共同的问题:
Multi-face Janus problem:多面Janus问题,是指在三维重建过程中,由于物体表面存在多个朝向不同的面,导致无法确定哪个面是物体的正面,从而影响重建结果的问题。
Baked lighting:是指将场景中的光照信息预先计算出来,并将其存储在纹理贴图等静态数据中,以提高实时渲染效率的技术。在三维重建中,由于烘焙光照只能处理静态场景,无法处理动态光照和材质等信息,因此可能会导致重建结果与实际场景存在差异。
幸运的是,通过多视图二维扩散模型的最新进展,以及潜在的BRDF自动编码器,可以解决这些问题( Mvdream:Shi et al., 2023;Syncdreamer:Liu等人,2023c; Efficientdreamer:Zhao等人,2023)。此外, image-to-3D 结果中生成的后视图纹理可能看起来很模糊。这可以通过更长时间的第二阶段训练来缓解。
五、安装与使用、代码解析
5.1 环境配置
首先将项目拉到本地,如下:
git clone https://github.com/dreamgaussian/dreamgaussian.git
下面是环境安装,建议安装在虚拟环境中:
pip install -r requirements.txt# a modified gaussian splatting (+ depth, alpha rendering)
git clone --recursive https://github.com/ashawkey/diff-gaussian-rasterization
pip install ./diff-gaussian-rasterization
# 以上这步如不成功,可以在diff-gaussian-rasterization 路径下使用 python setup.py install 命令安装# simple-knn
pip install ./simple-knn# nvdiffrast
pip install git+https://github.com/NVlabs/nvdiffrast/# kiuikit
pip install git+https://github.com/ashawkey/kiuikit
推荐的电脑配置如下(最好有梯子,会使用duffuser库,自动下载huggingface的zero123模型):
- Ubuntu 22 with torch 1.12 & CUDA 11.6 on a V100.
- Windows 10 with torch 2.1 & CUDA 12.1 on a 3070.
5.2 如何使用:单张图/文本-生成3D
- Image-to-3D:
01.图像预处理:删除图片背景,得到rgba格式的图片:
# 指定输出分辨率为512(不加该参数,默认是256)
python process.py data/name.jpg --size 512# 批量处理一个文件夹的图片
python process.py data
02.训练 高斯模型(粗模型)
# 训练 500个iters (~1 分钟) ,导出 ckpt & 粗的_mesh 到 logs 文件夹
python main.py --config configs/image.yaml input=data/name_rgba.png save_path=name# gui 模式 (训练过程可视化)
python main.py --config configs/image.yaml input=data/name_rgba.png save_path=name gui=True# .可视化 训练好的 高斯模型-----------------------------------------------------------------------------------------
python main.py --config configs/image.yaml load=logs/name_model.ply gui=True# .训练不是front-view的图像 (比如,俯视图可以指定为-30)-------------------------------------------
python main.py --config configs/image.yaml input=data/name_rgba.png save_path=name elevation=-3003.细重建阶段
# 自动载入 粗的 mesh并且精调 50 iters (~1min), export fine_mesh to logs
python main2.py --config configs/image.yaml input=data/name_rgba.png save_path=name# 自己指定 粗的 mesh 的路径
python main2.py --config configs/image.yaml input=data/name_rgba.png save_path=name mesh=logs/name_mesh.obj# gui 模式
python main2.py --config configs/image.yaml input=data/name_rgba.png save_path=name gui=True# 导出 glb 而不是 obj
python main2.py --config configs/image.yaml input=data/name_rgba.png save_path=name mesh_format=glb### 可视化
# gui for visualizing mesh
python -m kiui.render logs/name.obj# 保存 360 degree video of mesh (can run without gui)
python -m kiui.render logs/name.obj --save_video name.mp4 --wogui# 保存 8 view images of mesh (can run without gui)
python -m kiui.render logs/name.obj --save images/name/ --wogui### 验证 CLIP-similarity
python -m kiui.cli.clip_sim data/name_rgba.png logs/name.obj
- Text-to-3D:
### training gaussian stage
python main.py --config configs/text.yaml prompt="a photo of an icecream" save_path=icecream### training mesh stage
python main2.py --config configs/text.yaml prompt="a photo of an icecream" save_path=icecream
配置文件 ./configs/text.yaml 中有更多选项
- 批量处理
# run all image samples (*_rgba.png) in ./data
python scripts/runall.py --dir ./data --gpu 0# run all text samples (hardcoded in runall_sd.py)
python scripts/runall_sd.py --gpu 0# export all ./logs/*.obj to mp4 in ./videos
python scripts/convert_obj_to_video.py --dir ./logs
5.3 代码解析
01.rembg 库,自动剪掉背景
代码位于 process.py
import rembgimage = cv2.imread(file, cv2.IMREAD_UNCHANGED)# carve background
print(f'[INFO] background removal...')
carved_image = rembg.remove(image, session=session) # [H, W, 4]
mask = carved_image[..., -1] > 0
02.self.prepare_train()
预处理阶段,提取图像特征(分别提取clip与vae特征)
# 图片插值到256×256self.input_img_torch = F.interpolate(self.input_img_torch, (256, 256), mode="bilinear", align_corners=False)self.pipe = Zero123Pipeline.from_pretrained( "bennyguo/zero123-xl-diffusers",variant="fp16_ema" if self.fp16 else None, torch_dtype=self.dtype,).to(self.device)self.pipe.image_encoder.eval()self.pipe.vae.eval()self.pipe.unet.eval()self.pipe.clip_camera_projection.eval()x_clip = self.pipe.feature_extractor(images=x_pil, return_tensors="pt").pixel_values.to(device=self.device, dtype=self.dtype) # 256 -> 224c = self.pipe.image_encoder(x_clip).image_embeds # Clip:(1,768)v = self.encode_imgs(x.to(self.dtype)) / self.vae.config.scaling_factor # self.vae.encode : (1,4,32,32)self.embeddings = [c, v]
03.生成位姿信息
# 1. 首先生成位姿信息------------------------------------------------------------
pose = orbit_camera(self.opt.elevation = 0 , 0, self.opt.radius = 2)def orbit_camera(elevation, azimuth, radius=1, is_degree=True, target=None, opengl=True):# radius: scalar# elevation: scalar, in (-90, 90), from +y to -y is (-90, 90)# azimuth: scalar, in (-180, 180), from +z to +x is (0, 90)# return: [4, 4], camera pose matrixif is_degree:elevation = np.deg2rad(elevation)azimuth = np.deg2rad(azimuth)x = radius * np.cos(elevation) * np.sin(azimuth)y = - radius * np.sin(elevation)z = radius * np.cos(elevation) * np.cos(azimuth)if target is None:target = np.zeros([3], dtype=np.float32)campos = np.array([x, y, z]) + target # [3]T = np.eye(4, dtype=np.float32)T[:3, :3] = look_at(campos, target, opengl)T[:3, 3] = camposreturn Tcur_cam = MiniCam( # 用于生成透视投影矩阵,将3维物体映射到2维图像pose,render_resolution,render_resolution, # 128self.cam.fovy, # 0.8569self.cam.fovx, # 0.8569self.cam.near, # 0.01self.cam.far, # 100
) out = self.renderer.render(self.fixed_cam)
04. gaussians光栅化器的渲染
分为两步:
- 首先利用位姿等信息,初始化光栅化器,即函数 GaussianRasterizationSettings
2.光栅化器的 inference 过程,即以下函数 rasterizer。该过程被高度封装成c语言,输入是5000个高斯点的位置和协方差。
screenspace_points = (torch.zeros_like( self.gaussians.get_xyz,dtype=self.gaussians.get_xyz.dtype, requires_grad=True, device="cuda", ) # (5000,3)×·[0]tanfovx = math.tan(viewpoint_camera.FoVx * 0.5) # FoVx: 0.8569tanfovy = math.tan(viewpoint_camera.FoVy * 0.5) # FoVy: 0.8569raster_settings = GaussianRasterizationSettings(image_height=256,image_width=256,tanfovx, tanfovybg=[1,1,1],scale_modifier=1.0,viewmatrix=viewpoint_camera.world_view_transform, # [1,-0,-0,0],[0,1,-0,0],[0,-0,-1, 0],[-0,-0,2,1]projmatrix=viewpoint_camera.full_proj_transform, # [ 2.1892, 0.0000, 0.0000, 0.0000],sh_degree=0, # [ 0.0000, -2.1892, 0.0000, 0.0000],campos=viewpoint_camera.camera_center[0,0,-2], # [ 0.0000, 0.0000, -1.0001, -1.0000],prefiltered=False, # [ 0.0000, 0.0000, 1.9902, 2.0000debug=False,)rendered_image, radii, rendered_depth, rendered_alpha = rasterizer(means3D=means3D,means2D=means2D,shs=shs,colors_precomp=colors_precomp,opacities=opacity,scales=scales,rotations=rotations,cov3D_precomp=cov3D_precomp,)rendered_image = rendered_image.clamp(0, 1)# Those Gaussians that were frustum culled or had a radius of 0 were not visible.# They will be excluded from value updates used in the splitting criteria.return {"image": rendered_image,"depth": rendered_depth,"alpha": rendered_alpha,"viewspace_points": screenspace_points,"visibility_filter": radii > 0,"radii": radii,}04. loss损失:
分为高斯loss和扩散模型loss
扩散模型选用冻结的预训练unet,给latent(参考图像的vae特征)加噪声,再去噪声。其中,参考图像的clip损失 cc_emb,作为unet的条件,其中融入了俯仰角、半径等信息。
# 1.高斯splitting lossimage = out["image"].unsqueeze(0) # [1, 3, H, W] in [0, 1]loss = loss + 10000 * step_ratio * F.mse_loss(image, self.input_img_torch)# mask lossmask = out["alpha"].unsqueeze(0) # [1, 1, H, W] in [0, 1]loss = loss + 1000 * step_ratio * F.mse_loss(mask, self.input_mask_torch)# 2.扩散模型 losswith torch.no_grad():noise = torch.randn_like(latents)latents_noisy = self.scheduler.add_noise(latents, noise, t)x_in = torch.cat([latents_noisy] * 2)t_in = torch.cat([t] * 2)T = np.stack([np.deg2rad(polar), np.sin(np.deg2rad(azimuth)), np.cos(np.deg2rad(azimuth)), radius], axis=-1) # (1,4)T = torch.from_numpy(T).unsqueeze(1).to(self.dtype).to(self.device) # [1, 1, 4]cc_emb = torch.cat([self.embeddings[0].repeat(batch_size, 1, 1), T], dim=-1) # clip(1,768) -> (1,1,772)cc_emb = self.pipe.clip_camera_projection(cc_emb) # (1,1,768)cc_emb = torch.cat([cc_emb, torch.zeros_like(cc_emb)], dim=0)vae_emb = self.embeddings[1].repeat(batch_size, 1, 1, 1)vae_emb = torch.cat([vae_emb, torch.zeros_like(vae_emb)], dim=0)noise_pred = self.unet(torch.cat([x_in, vae_emb], dim=1),t_in.to(self.unet.dtype),encoder_hidden_states=cc_emb,).sample # (2,8,32,32) -> (2,4,32,32)noise_pred_cond, noise_pred_uncond = noise_pred.chunk(2)noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_cond - noise_pred_uncond)grad = w * (noise_pred - noise)grad = torch.nan_to_num(grad)target = (latents - grad).detach()loss = 0.5 * F.mse_loss(latents.float(), target, reduction='sum')return loss
扩展
1.Marching cubes算法
Marching cubes是一种计算机图形学中的算法,用于将三维数据转换为mesh模型。其主要原理是将三维数据分割为小的立方体,然后根据每个立方体内部的数据值确定其表面的形状。该算法通常用于医学成像、地质学、气象学等领域。
Marching Cubes算法的具体步骤:
01.网格划分
将三维数据划分为边长为 h h h 的网格,每个网格包含8个顶点和12条棱。这些顶点和棱分别对应于3D空间中的点和线段。
02.计算网格内部的标量值
对于每个网格,需要计算其内部8个顶点的标量值。这些标量值通常表示为 f ( x , y , z ) f(x,y,z) f(x,y,z),其中 ( x , y , z ) (x,y,z) (x,y,z) 是顶点的坐标。
03.确定网格内部的等值面
根据网格内部的标量值,需要确定其内部的等值面。等值面是指标量值等于某个特定值的表面。在Marching Cubes算法中,通常将等值面的标量值设为0。
04.计算等值面上的顶点
对于每个等值面,需要计算其上的顶点。这些顶点通常位于等值面的边界处,也就是位于两个不同标量值的网格之间的位置。
05.确定等值面的拓扑结构
根据等值面上的顶点,需要确定其拓扑结构。拓扑结构是指等值面上顶点之间的连接关系,通常使用三角形来表示。
06.生成三角形网格
根据等值面的拓扑结构,需要生成三角形网格。在Marching Cubes算法中,使用了一个预定义的查找表来确定每个等值面所对应的三角形网格。
看不懂没关系,下面以二维图形为例解释:
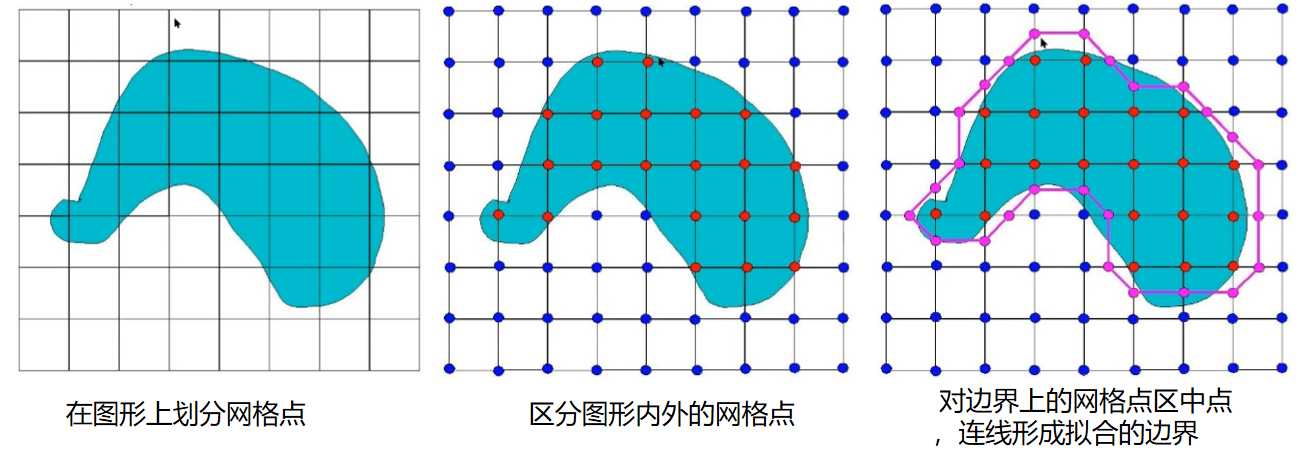
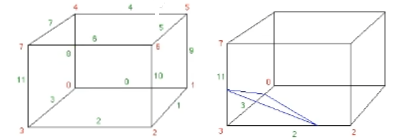
三维也是一样:
这篇关于【三维重建】DreamGaussian:高斯splatting的单视图3D内容生成(原理+代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




