本文主要是介绍一文详解模型调参神器:Hyperopt,体验后真的很棒,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
hyperopt 是一个 Python 库,主要使用
- 随机搜索算法
- 模拟退火算法
- TPE算法
来对某个算法模型的最佳参数进行智能搜索,它的全称是Hyperparameter Optimization。
本文将介绍一种快速有效的方法用于实现机器学习模型的调参。有两种常用的调参方法:网格搜索和随机搜索。每一种都有自己的优点和缺点。网格搜索速度慢,但在搜索整个搜索空间方面效果很好,而随机搜索很快,但可能会错过搜索空间中的重要点。幸运的是,还有第三种选择:贝叶斯优化。本文我们将重点介绍贝叶斯优化的一个实现,一个名为hyperopt的 Python 模块。喜欢记得收藏、点赞、关注。
【注】完整版代码、数据、技术交流文末获取
使用贝叶斯优化进行调参可以让我们获得给定模型的最佳参数,例如逻辑回归模型。这也使我们能够执行最佳的模型选择。通常机器学习工程师或数据科学家将为少数模型(如决策树,支持向量机和 K 近邻)执行某种形式(网格搜索或随机搜索)的手动调参,然后比较准确率并选择最佳的一个来使用。该方法可能比较的是次优模型。也许数据科学家找到了决策树的最优参数,但却错过了 SVM 的最优参数。
这意味着他们的模型比较是有缺陷的。如果 SVM 参数调整得很差,K 近邻可能每次都会击败 SVM。贝叶斯优化允许数据科学家找到所有模型的_最佳_参数,并因此比较最佳模型。这会得到更好的模型选择,因为你比较的是最佳的 k 近邻和最佳的决策树。只有这样你才能非常自信地进行模型选择,确保选择并使用的是实际最佳的模型。
本文涵盖的主题有:
-
目标函数
-
搜索空间
-
存储评估试验
-
可视化
-
应用案例
K 近邻
支持向量机
决策树
随机森林
LightGBM
要使用下面的代码,你必须安装hyperopt和pymongo
什么是Hyperopt
Hyperopt是一个强大的python库,用于超参数优化,由jamesbergstra开发。Hyperopt使用贝叶斯优化的形式进行参数调整,允许你为给定模型获得最佳参数。它可以在大范围内优化具有数百个参数的模型。
Hyperopt的特性
Hyperopt包含4个重要的特性,你需要知道,以便运行你的第一个优化。
搜索空间
hyperopt有不同的函数来指定输入参数的范围,这些是随机搜索空间。选择最常用的搜索选项:
-
hp.choice(label, options)-这可用于分类参数,它返回其中一个选项,它应该是一个列表或元组。示例:hp.choice(“criterion”, [“gini”,”entropy”,])
-
hp.randint(label, upper)-可用于整数参数,它返回范围(0,upper)内的随机整数。示例:hp.randint(“max_features”,50)
-
hp.uniform(label, low, high)-它返回一个介于low和high之间的值。示例:hp.uniform(“max_leaf_nodes”,1,10)
你可以使用的其他选项包括:
-
hp.normal(label, mu, sigma)-这将返回一个实际值,该值服从均值为mu和标准差为sigma的正态分布
-
hp.qnormal(label, mu, sigma, q)-返回一个类似round(normal(mu, sigma) / q) * q的值
-
hp.lognormal(label, mu, sigma)-返回exp(normal(mu, sigma))
-
hp.qlognormal(label, mu, sigma, q) -返回一个类似round(exp(normal(mu, sigma)) / q) * q的值
注:每个可优化的随机表达式都有一个标签(例如n_estimators)作为第一个参数。这些标签用于在优化过程中将参数选择返回给调用者。
目标函数
这是一个最小化函数,它从搜索空间接收超参数值作为输入并返回损失。这意味着在优化过程中,我们使用选定的超参数值训练模型并预测目标特征,然后评估预测误差并将其返回给优化器。优化器将决定要检查哪些值并再次迭代。你将在一个实际例子中学习如何创建一个目标函数。
一个简单的例子
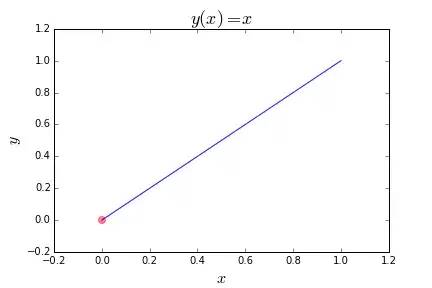
假设你有一个定义在某个范围内的函数,并且想把它最小化。也就是说,你想找到产生最低输出值的输入值。下面的简单例子找到x的值用于最小化线性函数y(x) = x
from hyperopt import fmin, tpe, hp
best = fmin(fn=lambda x: x,space=hp.uniform('x', 0, 1),algo=tpe.suggest,max_evals=100)
print best
我们来分解一下这个例子。
函数fmin首先接受一个函数来最小化,记为fn,在这里用一个匿名函数lambda x: x来指定。该函数可以是任何有效的值返回函数,例如回归中的平均绝对误差。
下一个参数指定搜索空间,在本例中,它是0到1之间的连续数字范围,由hp.uniform('x', 0, 1)指定。hp.uniform是一个内置的hyperopt函数,它有三个参数:名称x,范围的下限和上限0和1。
algo参数指定搜索算法,本例中tpe表示 tree of Parzen estimators。该主题超出了本文的范围,但有数学背景的读者可以细读这篇[1]文章。algo参数也可以设置为hyperopt.random,但是这里我们没有涉及,因为它是众所周知的搜索策略。但在未来的文章中我们可能会涉及。
最后,我们指定fmin函数将执行的最大评估次数max_evals。这个fmin函数将返回一个python字典。
上述函数的一个输出示例是{'x': 0.000269455723739237}。
以下是该函数的图。红点是我们试图找到的点。
更复杂的例子
这有一个更复杂的目标函数:lambda x: (x-1)**2。这次我们试图最小化一个二次方程y(x)=(x-1)**2。所以我们改变搜索空间以包括我们已知的最优值(x=1)加上两边的一些次优范围:hp.uniform('x', -2, 2)。
现在我们有:
best = fmin(fn=lambda x: (x-1)**2,space=hp.uniform('x', -2, 2),algo=tpe.suggest,max_evals=100)
print best
输出应该看起来像这样:
{'x': 0.997369045274755}
这是函数图。

有时也许我们想要最大化目标函数,而不是最小化它。为此,我们只需要返回函数的负数。例如,我们有函数y(x) = -(x**2):

我们如何解决这个问题?我们采用目标函数lambda x: -(x**2)并返回负值,只需给出lambda x: -1*-(x**2)或者lambda x: (x**2)即可。
这里有一个和例子1类似,但我们不是最小化,而是试图最大化。

这里有许多(无限多且无限范围)局部最小值的函数,我们也试图将其最大化:

搜索空间
hyperopt模块包含一些方便的函数来指定输入参数的范围。我们已经见过hp.uniform。最初,这些是随机搜索空间,但随着hyperopt更多的学习(因为它从目标函数获得更多反馈),通过它认为提供给它最有意义的反馈,会调整并采样初始搜索空间的不同部分。
以下内容将在本文中使用:
-
hp.choice(label, options)其中options应是 python 列表或元组。 -
hp.normal(label, mu, sigma)其中mu和sigma分别是均值和标准差。 -
hp.uniform(label, low, high)其中low和high是范围的下限和上限。
其他也是可用的,例如hp.normal,hp.lognormal,hp.quniform,但我们不会在这里使用它们。
为了查看搜索空间的一些例子,我们应该导入另一个函数,同时定义搜索空间。
import hyperopt.pyll.stochasticspace = {'x': hp.uniform('x', 0, 1),'y': hp.normal('y', 0, 1),'name': hp.choice('name', ['alice', 'bob']),
}print hyperopt.pyll.stochastic.sample(space)
一个示例输出是:
{'y': -1.4012610048810574, 'x': 0.7258615424906184, 'name': 'alice'}
尝试运行几次并查看不同的样本。
通过 Trials 捕获信息
如果能看到hyperopt黑匣子内发生了什么是极好的。Trials对象使我们能够做到这一点。我们只需要导入一些东西。
from hyperopt import fmin, tpe, hp, STATUS_OK, Trialsfspace = {'x': hp.uniform('x', -5, 5)
}def f(params):x = params['x']val = x**2return {'loss': val, 'status': STATUS_OK}trials = Trials()
best = fmin(fn=f, space=fspace, algo=tpe.suggest, max_evals=50, trials=trials)print('best:', best)
print('trials:')
for trial in trials.trials[:2]:print(trial)
STATUS_OK和Trials是新导入的。Trials对象允许我们在每个时间步存储信息。然后我们可以将它们打印出来,并在给定的时间步查看给定参数的函数评估值。
这是上面代码的一个输出示例:
best: {'x': 0.014420181637303776}
trials:
{'refresh_time': None, 'book_time': None, 'misc': {'tid': 0, 'idxs': {'x': [0]}, 'cmd': ('domain_attachment', 'FMinIter_Domain'), 'vals': {'x': [1.9646918559786162]},'workdir': None},'state': 2, 'tid': 0, 'exp_key': None, 'version': 0, 'result': {'status': 'ok', 'loss': 3.8600140889486996}, 'owner': None, 'spec': None}
{'refresh_time': None, 'book_time': None, 'misc': {'tid': 1, 'idxs': {'x': [1]},'cmd': ('domain_attachment', 'FMinIter_Domain'), 'vals': {'x': [-3.9393509404526728]}, 'workdir': None}, 'state': 2, 'tid': 1, 'exp_key': None, 'version': 0, 'result': {'status': 'ok', 'loss': 15.518485832045357}, 'owner': None, 'spec': None
}
Trials对象将数据存储为BSON对象,其工作方式与JSON对象相同。BSON来自pymongo模块。我们不会在这里讨论细节,这是对于需要使用MongoDB进行分布式计算的hyperopt的高级选项,因此需要导入pymongo。回到上面的输出。tid是时间 id,即时间步,其值从0到max_evals-1。它随着迭代次数递增。'x'是键'vals'的值,其中存储的是每次迭代参数的值。'loss'是键'result'的值,其给出了该次迭代目标函数的值。
我们用另一种方式来看看。
可视化
我们将在这里讨论两种类型的可视化:值 vs. 时间与损失 vs. 值。首先是值 vs. 时间。以下是绘制上述Trial.trials数据的代码和示例输出。
f, ax = plt.subplots(1)
xs = [t['tid'] for t in trials.trials]
ys = [t['misc']['vals']['x'] for t in trials.trials]
ax.set_xlim(xs[0]-10, xs[-1]+10)
ax.scatter(xs, ys, s=20, linewidth=0.01, alpha=0.75)
ax.set_title('$x$ $vs$ $t$ ', fontsize=18)
ax.set_xlabel('$t$', fontsize=16)
ax.set_ylabel('$x$', fontsize=16)
假设我们将max_evals设为1000,输出应该如下所示。

我们可以看到,最初算法从整个范围中均匀地选择值,但随着时间的推移以及参数对目标函数的影响了解越来越多,该算法越来越聚焦于它认为会取得最大收益的区域-一个接近零的范围。它仍然探索整个解空间,但频率有所下降。
现在让我们看看损失 vs. 值的图。
f, ax = plt.subplots(1)
xs = [t['misc']['vals']['x'] for t in trials.trials]
ys = [t['result']['loss'] for t in trials.trials]
ax.scatter(xs, ys, s=20, linewidth=0.01, alpha=0.75)
ax.set_title('$val$ $vs$ $x$ ', fontsize=18)
ax.set_xlabel('$x$', fontsize=16)
ax.set_ylabel('$val$', fontsize=16)

它给了我们所期望的,因为函数y(x)=x**2是确定的。
总结一下,让我们尝试一个更复杂的例子,伴随更多的随机性和更多的参数。
hyperopt调参案例
在本节中,我们将介绍4个使用hyperopt在经典数据集 Iris 上调参的完整示例。我们将涵盖 K 近邻(KNN),支持向量机(SVM),决策树和随机森林。需要注意的是,由于我们试图最大化交叉验证的准确率(acc请参见下面的代码),而hyperopt只知道如何最小化函数,所以必须对准确率取负。最小化函数f与最大化f的负数是相等的。
对于这项任务,我们将使用经典的Iris数据集,并进行一些有监督的机器学习。数据集有有4个输入特征和3个输出类别。数据被标记为属于类别0,1或2,其映射到不同种类的鸢尾花。输入有4列:萼片长度,萼片宽度,花瓣长度和花瓣宽度。输入的单位是厘米。我们将使用这4个特征来学习模型,预测三种输出类别之一。因为数据由sklearn提供,它有一个很好的DESCR属性,可以提供有关数据集的详细信息。尝试以下代码以获得更多细节信息。
print(iris.feature_names) # input names
print(iris.target_names) # output names
print(iris.DESCR) # everything else
我们通过使用下面的代码可视化特征和类来更好地了解数据。如果你还没安装别忘了先执行pip install searborn。
import seaborn as sns
sns.set(style="whitegrid", palette="husl")iris = sns.load_dataset("iris")
print(iris.head())iris = pd.melt(iris, "species", var_name="measurement")
print(iris.head())f, ax = plt.subplots(1, figsize=(15,10))
sns.stripplot(x="measurement", y="value", hue="species", data=iris, jitter=True, edgecolor="white", ax=ax)
这是图表:

K 近邻
我们现在将使用hyperopt来找到 K近邻(KNN)机器学习模型的最佳参数。KNN 模型是基于训练数据集中 k 个最近数据点的大多数类别对来自测试集的数据点进行分类。关于这个算法的更多信息可以参考这里。下面的代码结合了我们所涵盖的一切。
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.targetdef hyperopt_train_test(params):clf = KNeighborsClassifier(**params)return cross_val_score(clf, X, y).mean()space4knn = {'n_neighbors': hp.choice('n_neighbors', range(1,100))
}def f(params):acc = hyperopt_train_test(params)return {'loss': -acc, 'status': STATUS_OK}trials = Trials()
best = fmin(f, space4knn, algo=tpe.suggest, max_evals=100, trials=trials)
print('best:')
print(best)
现在看看输出结果的图。y轴是交叉验证分数,x轴是 k 近邻个数。下面是代码和它的图像:
f, ax = plt.subplots(1)#, figsize=(10,10))
xs = [t['misc']['vals']['n'] for t in trials.trials]
ys = [-t['result']['loss'] for t in trials.trials]
ax.scatter(xs, ys, s=20, linewidth=0.01, alpha=0.5)
ax.set_title('Iris Dataset - KNN', fontsize=18)
ax.set_xlabel('n_neighbors', fontsize=12)
ax.set_ylabel('cross validation accuracy', fontsize=12)

k 大于63后,准确率急剧下降。这是因为数据集中每个类的数量。这三个类中每个类只有50个实例。所以将'n_neighbors'的值限制为较小的值来进一步探索。
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.targetdef hyperopt_train_test(params):clf = KNeighborsClassifier(**params)return cross_val_score(clf, X, y).mean()space4knn = {'n_neighbors': hp.choice('n_neighbors', range(1,50))
}def f(params):acc = hyperopt_train_test(params)return {'loss': -acc, 'status': STATUS_OK}trials = Trials()
best = fmin(f, space4knn, algo=tpe.suggest, max_evals=100, trials=trials)
print('best:')
print(best)
这是我们运行相同的可视化代码得到的结果:

现在我们可以清楚地看到k有一个最佳值,k=4。
上面的模型没有做任何预处理。所以我们来归一化和缩放特征,看看是否有帮助。用如下代码:
# now with scaling as an option
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.targetdef hyperopt_train_test(params):X_ = X[:]if 'normalize' in params:if params['normalize'] == 1:X_ = normalize(X_)del params['normalize']if 'scale' in params:if params['scale'] == 1:X_ = scale(X_)del params['scale']clf = KNeighborsClassifier(**params)return cross_val_score(clf, X_, y).mean()space4knn = {'n_neighbors': hp.choice('n_neighbors', range(1,50)),'scale': hp.choice('scale', [0, 1]),'normalize': hp.choice('normalize', [0, 1])
}def f(params):acc = hyperopt_train_test(params)return {'loss': -acc, 'status': STATUS_OK}trials = Trials()
best = fmin(f, space4knn, algo=tpe.suggest, max_evals=100, trials=trials)
print('best:')
print(best)
并像这样绘制参数:
parameters = ['n_neighbors', 'scale', 'normalize']
cols = len(parameters)
f, axes = plt.subplots(nrows=1, ncols=cols, figsize=(15,5))
cmap = plt.cm.jet
for i, val in enumerate(parameters):xs = np.array([t['misc']['vals'][val] for t in trials.trials]).ravel()ys = [-t['result']['loss'] for t in trials.trials]xs, ys = zip(\*sorted(zip(xs, ys)))ys = np.array(ys)axes[i].scatter(xs, ys, s=20, linewidth=0.01, alpha=0.75, c=cmap(float(i)/len(parameters)))axes[i].set_title(val)

我们看到缩放和/或归一化数据并不会提高预测准确率。k的最佳值仍然为4,这得到98.6%的准确率。
所以这对于简单模型 KNN 调参很有用。让我们看看用支持向量机(SVM)能做什么。
支持向量机(SVM)
由于这是一个分类任务,我们将使用sklearn的SVC类。超参数调整代码如下:
iris = datasets.load_iris()
X = iris.data
y = iris.targetdef hyperopt_train_test(params):X_ = X[:]if 'normalize' in params:if params['normalize'] == 1:X_ = normalize(X_)del params['normalize']if 'scale' in params:if params['scale'] == 1:X_ = scale(X_)del params['scale']clf = SVC(**params)return cross_val_score(clf, X_, y).mean()space4svm = {'C': hp.uniform('C', 0, 20),'kernel': hp.choice('kernel', ['linear', 'sigmoid', 'poly', 'rbf']),'gamma': hp.uniform('gamma', 0, 20),'scale': hp.choice('scale', [0, 1]),'normalize': hp.choice('normalize', [0, 1])
}def f(params):acc = hyperopt_train_test(params)return {'loss': -acc, 'status': STATUS_OK}trials = Trials()
best = fmin(f, space4svm, algo=tpe.suggest, max_evals=100, trials=trials)
print('best:')
print(best)parameters = ['C', 'kernel', 'gamma', 'scale', 'normalize']
cols = len(parameters)
f, axes = plt.subplots(nrows=1, ncols=cols, figsize=(20,5))
cmap = plt.cm.jet
for i, val in enumerate(parameters):xs = np.array([t['misc']['vals'][val] for t in trials.trials]).ravel()ys = [-t['result']['loss'] for t in trials.trials]xs, ys = zip(\*sorted(zip(xs, ys)))axes[i].scatter(xs, ys, s=20, linewidth=0.01, alpha=0.25, c=cmap(float(i)/len(parameters)))axes[i].set_title(val)axes[i].set_ylim([0.9, 1.0])
这是我们得到的:

同样,缩放和归一化也没有帮助。核函数的首选是(linear),C的最佳值是1.4168540399911616,gamma的最佳值是15.04230279483486。这组参数得到了99.3%的分类准确率。
决策树
我们将尝试只优化决策树的一些参数。调参数代码如下。
iris = datasets.load_iris()
X_original = iris.data
y_original = iris.targetdef hyperopt_train_test(params):X_ = X[:]if 'normalize' in params:if params['normalize'] == 1:X_ = normalize(X_)del params['normalize']if 'scale' in params:if params['scale'] == 1:X_ = scale(X_)del params['scale']clf = DecisionTreeClassifier(**params)return cross_val_score(clf, X, y).mean()space4dt = {'max_depth': hp.choice('max_depth', range(1,20)),'max_features': hp.choice('max_features', range(1,5)),'criterion': hp.choice('criterion', ["gini", "entropy"]),'scale': hp.choice('scale', [0, 1]),'normalize': hp.choice('normalize', [0, 1])
}def f(params):
acc = hyperopt_train_test(params)
return {'loss': -acc, 'status': STATUS_OK}trials = Trials()
best = fmin(f, space4dt, algo=tpe.suggest, max_evals=300, trials=trials)
print('best:')
print(best)
输出如下,其准确率为97.3%。
{'max_features': 1, 'normalize': 0, 'scale': 0,
'criterion': 0, 'max_depth': 17}
以下是图表。我们可以看到,对于不同的scale值,normalize和criterion,性能几乎没有差别。
parameters = ['max_depth', 'max_features', 'criterion', 'scale', 'normalize'] # decision tree
cols = len(parameters)
f, axes = plt.subplots(nrows=1, ncols=cols, figsize=(20,5))
cmap = plt.cm.jet
for i, val in enumerate(parameters):xs = np.array([t['misc']['vals'][val] for t in trials.trials]).ravel()ys = [-t['result']['loss'] for t in trials.trials]xs, ys = zip(\*sorted(zip(xs, ys)))ys = np.array(ys)axes[i].scatter(xs, ys, s=20, linewidth=0.01, alpha=0.5, c=cmap(float(i)/len(parameters)))axes[i].set_title(val)#axes[i].set_ylim([0.9,1.0])

随机森林
让我们来看看集成分类器随机森林发生了什么,随机森林只是在不同分区数据上训练的决策树集合,每个分区都对输出类进行投票,并将绝大多数类的选择为预测。
iris = datasets.load_iris()
X_original = iris.data
y_original = iris.targetdef hyperopt_train_test(params):X_ = X[:]if 'normalize' in params:if params['normalize'] == 1:X_ = normalize(X_)del params['normalize']if 'scale' in params:if params['scale'] == 1:X_ = scale(X_)del params['scale']clf = RandomForestClassifier(**params)return cross_val_score(clf, X, y).mean()space4rf = {'max_depth': hp.choice('max_depth', range(1,20)),'max_features': hp.choice('max_features', range(1,5)),'n_estimators': hp.choice('n_estimators', range(1,20)),'criterion': hp.choice('criterion', ["gini", "entropy"]),'scale': hp.choice('scale', [0, 1]),'normalize': hp.choice('normalize', [0, 1])
}best = 0
def f(params):global bestacc = hyperopt_train_test(params)if acc > best:best = accprint 'new best:', best, paramsreturn {'loss': -acc, 'status': STATUS_OK}trials = Trials()
best = fmin(f, space4rf, algo=tpe.suggest, max_evals=300, trials=trials)
print('best:')
print(best)同样,与决策树相同,我们仅得到97.3%的准确率。
这是绘制参数的代码:
parameters = ['n_estimators', 'max_depth', 'max_features', 'criterion', 'scale', 'normalize']
f, axes = plt.subplots(nrows=2, ncols=3, figsize=(15,10))
cmap = plt.cm.jet
for i, val in enumerate(parameters):print i, valxs = np.array([t['misc']['vals'][val] for t in trials.trials]).ravel()ys = [-t['result']['loss'] for t in trials.trials]xs, ys = zip(\*sorted(zip(xs, ys)))ys = np.array(ys)axes[i/3,i%3].scatter(xs, ys, s=20, linewidth=0.01, alpha=0.5, c=cmap(float(i)/len(parameters)))axes[i/3,i%3].set_title(val)#axes[i/3,i%3].set_ylim([0.9,1.0])

调参融合
自动调整一个模型的参数(如SVM或KNN)非常有趣并且具有启发性,但同时调整它们并取得全局最佳模型则更有用。这使我们能够一次比较所有参数和所有模型,因此为我们提供了最佳模型。代码如下:
digits = datasets.load_digits()
X = digits.data
y = digits.target
print X.shape, y.shapedef hyperopt_train_test(params):t = params['type']del params['type']if t == 'naive_bayes':clf = BernoulliNB(**params)elif t == 'svm':clf = SVC(**params)elif t == 'dtree':clf = DecisionTreeClassifier(**params)elif t == 'knn':clf = KNeighborsClassifier(**params)else:return 0return cross_val_score(clf, X, y).mean()space = hp.choice('classifier_type', [{'type': 'naive_bayes','alpha': hp.uniform('alpha', 0.0, 2.0)},{'type': 'svm','C': hp.uniform('C', 0, 10.0),'kernel': hp.choice('kernel', ['linear', 'rbf']),'gamma': hp.uniform('gamma', 0, 20.0)},{'type': 'randomforest','max_depth': hp.choice('max_depth', range(1,20)),'max_features': hp.choice('max_features', range(1,5)),'n_estimators': hp.choice('n_estimators', range(1,20)),'criterion': hp.choice('criterion', ["gini", "entropy"]),'scale': hp.choice('scale', [0, 1]),'normalize': hp.choice('normalize', [0, 1])},{'type': 'knn','n_neighbors': hp.choice('knn_n_neighbors', range(1,50))}
])count = 0
best = 0
def f(params):global best, countcount += 1acc = hyperopt_train_test(params.copy())if acc > best:print 'new best:', acc, 'using', params['type']best = accif count % 50 == 0:print 'iters:', count, ', acc:', acc, 'using', paramsreturn {'loss': -acc, 'status': STATUS_OK}trials = Trials()
best = fmin(f, space, algo=tpe.suggest, max_evals=1500, trials=trials)
print('best:')
print(best)
由于我们增加了评估数量,此代码需要一段时间才能运行完:max_evals=1500。当找到新的最佳准确率时,它还会添加到输出用于更新。好奇为什么使用这种方法没有找到前面的最佳模型:参数为kernel=linear,C=1.416,gamma=15.042的SVM。
LightGBM自动化调参
下面我们利用hyperopt对lightgbm进行自动化调参,以下程序用时较长,可以根据情况增加或者减少尝试的超参数组合个数。
注意我们的num_boost_round是通过early_stop自适应的,无需调参。
导包等准备
import datetime
import numpy as np
from numpy.random import RandomState
import pandas as pd
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,f1_score
import matplotlib.pyplot as plt
from hyperopt import fmin,hp,Trials,space_eval,rand,tpe,anneal
import warnings
warnings.filterwarnings('ignore')def printlog(info):nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("\n"+"=========="*8 + "%s"%nowtime)print(info+'...\n\n')
读取数据
printlog("step1: reading data...")# 读取dftrain,dftest
breast = datasets.load_breast_cancer()
df = pd.DataFrame(breast.data,columns = [x.replace(' ','_') for x in breast.feature_names])
df['label'] = breast.target
df['mean_radius'] = df['mean_radius'].apply(lambda x:int(x))
df['mean_texture'] = df['mean_texture'].apply(lambda x:int(x))
dftrain,dftest = train_test_split(df)categorical_features = ['mean_radius','mean_texture']
lgb_train = lgb.Dataset(dftrain.drop(['label'],axis = 1),label=dftrain['label'],categorical_feature = categorical_features,free_raw_data=False)lgb_valid = lgb.Dataset(dftest.drop(['label'],axis = 1),label=dftest['label'],categorical_feature = categorical_features,reference=lgb_train,free_raw_data=False)
搜索超参
printlog("step2: searching parameters...")
boost_round = 1000
early_stop_rounds = 50params = {'learning_rate': 0.1,'boosting_type': 'gbdt',#'dart','rf' 'objective':'binary','metric': ['auc'],'num_leaves': 31,'max_depth': 6,'min_data_in_leaf': 5, 'min_gain_to_split': 0,'reg_alpha':0,'reg_lambda':0,'feature_fraction': 0.9,'bagging_fraction': 0.8,'bagging_freq': 5,'feature_pre_filter':False,'verbose': -1
}
定义目标函数
def hyperopt_objective(config):params.update(config)gbm = lgb.train(params,lgb_train,num_boost_round= boost_round,valid_sets=(lgb_valid, lgb_train),valid_names=('validate','train'),early_stopping_rounds = early_stop_rounds,verbose_eval = False)y_pred_test = gbm.predict(dftest.drop('label',axis = 1),num_iteration=gbm.best_iteration)val_score = f1_score(dftest['label'],y_pred_test>0.5)return -val_score
带CV方法交叉验证
若需要带交叉验证,则可以
def hyperopt_objective(config):params.update(config)gbm = lgb.train(params,lgb_train,num_boost_round= boost_round,valid_sets=(lgb_valid, lgb_train),valid_names=('validate','train'),early_stopping_rounds = early_stop_rounds,verbose_eval = False)num_round = 10res = lgb.cv(params, # 如果lgb.LGBMRegressor.get_params()lgb_train,num_round,nfold=5,metrics='auc',early_stopping_rounds=10)return min(res['auc-mean'])
定义超参空间
#可以根据需要,注释掉偏后的一些不太重要的超参
spaces = {"learning_rate":hp.loguniform("learning_rate",np.log(0.001),np.log(0.5)),"boosting_type":hp.choice("boosting_type",['gbdt','dart','rf']),"num_leaves":hp.choice("num_leaves",range(15,128)),#"max_depth":hp.choice("max_depth",range(3,11)),#"min_data_in_leaf":hp.choice("min_data_in_leaf",range(1,50)),#"min_gain_to_split":hp.uniform("min_gain_to_split",0.0,1.0),#"reg_alpha": hp.uniform("reg_alpha", 0, 2),#"reg_lambda": hp.uniform("reg_lambda", 0, 2),#"feature_fraction":hp.uniform("feature_fraction",0.5,1.0),#"bagging_fraction":hp.uniform("bagging_fraction",0.5,1.0),#"bagging_freq":hp.choice("bagging_freq",range(1,20))}
执行超参搜索
# hyperopt支持如下搜索算法
#随机搜索(hyperopt.rand.suggest)
#模拟退火(hyperopt.anneal.suggest)
#TPE算法(hyperopt.tpe.suggest,算法全称为Tree-structured Parzen Estimator Approach)
trials = Trials()
best = fmin(fn=hyperopt_objective, space=spaces, algo= tpe.suggest, max_evals=100, trials=trialsrstate=RandomState(123))
获取最优参数
best_params = space_eval(spaces,best)
print("best_params = ",best_params)
绘制搜索过程
losses = [x["result"]["loss"] for x in trials.trials]
minlosses = [np.min(losses[0:i+1]) for i in range(len(losses))]
steps = range(len(losses))fig,ax = plt.subplots(figsize=(6,3.7),dpi=144)
ax.scatter(x = steps, y = losses, alpha = 0.3)
ax.plot(steps,minlosses,color = "red",axes = ax)
plt.xlabel("step")
plt.ylabel("loss")
训练模型
printlog("step3: training model...")params.update(best_params)
results = {}
gbm = lgb.train(params,lgb_train,num_boost_round= boost_round,valid_sets=(lgb_valid, lgb_train),valid_names=('validate','train'),early_stopping_rounds = early_stop_rounds,evals_result= results,verbose_eval = True)
评估模型
printlog("step4: evaluating model ...")y_pred_train = gbm.predict(dftrain.drop('label',axis = 1), num_iteration=gbm.best_iteration)
y_pred_test = gbm.predict(dftest.drop('label',axis = 1), num_iteration=gbm.best_iteration)train_score = f1_score(dftrain['label'],y_pred_train>0.5)
val_score = f1_score(dftest['label'],y_pred_test>0.5)print('train f1_score: {:.5} '.format(train_score))
print('valid f1_score: {:.5} \n'.format(val_score))fig2,ax2 = plt.subplots(figsize=(6,3.7),dpi=144)
fig3,ax3 = plt.subplots(figsize=(6,3.7),dpi=144)
lgb.plot_metric(results,ax = ax2)
lgb.plot_importance(gbm,importance_type = "gain",ax=ax3)
保存模型
printlog("step5: saving model ...")
model_dir = "gbm.model"
print("model_dir: %s"%model_dir)
gbm.save_model("gbm.model",num_iteration=gbm.best_iteration)
printlog("task end...")
推荐文章
-
李宏毅《机器学习》国语课程(2022)来了
-
有人把吴恩达老师的机器学习和深度学习做成了中文版
-
上瘾了,最近又给公司撸了一个可视化大屏(附源码)
-
如此优雅,4款 Python 自动数据分析神器真香啊
-
梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
-
香的很,整理了20份可视化大屏模板
技术交流
完整代码、技术交流、数据获取,可以找我来要

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

这篇关于一文详解模型调参神器:Hyperopt,体验后真的很棒的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







