本文主要是介绍《A Unified MRC Framework for Named Entity Recognition》ACL2020论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
机构为浙江大学、香侬科技。
存在的问题:
论文认为目前的的NER方法能够很高的解决flat NER任务,但是对于nested NER任务就显得不那么power。一般方法是分开做。
解决办法:
论文提出一种统一框架能够同时处理flat和nested两种类型问题。不将实体抽取看作NER问题,而是看作MRC。
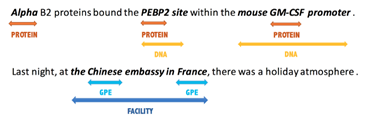
上图为flat和nested实体的实例
举例:
抽取PER(PERSON)实体,“[Washington] was born into slavery on the farm of James Burroughs”,可以用问题“which person is mentioned in the text?”,当作一个抽取式问题回答。这种策略很自然地解决了nested NER中的实体重叠问题:提取两个具有不同类别重叠的实体需要回答两个独立的问题,那么flat和nested自然就是分别独立进行回答。
动机:
一般处理nested NER方法为pipeline的方法,但是pipeline有错误传播的缺点。受到目前将NLP任务看作QA tasks的潮流,提出能够统一处理flat和nested NER框架,每种实体类型都有一个question,实体是通过在给定的上下文中回答问题来提取的。类似SQuAD的形式。
Nested NER:
嵌套的实体识别方法:1.利用多层的CRF进行抽取,可能先抽取最内层的实体,接下来抽取最外层的实体,或者反过来。2.利用解析树。3.使用hyper-graphs识别重叠部分。等等许多方法
MRC:
论文提到有人将关系抽取作为QA问答。每种类型都可以被参数化为问题
答案为
。例如:关系EDUCATED-AT可以被映射为“where did
study?” 给定问题
,如果非空答案
可以从段落里抽取出来,这意味着当前段是
。 有的将summarization或者情感分析作为MRC,summary任务的问题可以是“what is the summary?”。论文受到来自2019年的《A general framework for information extraction using dynamic span graphs》 的启发,2019的论文将entity-relation extraction作为多轮QA任务。
设计过程:
NER任务描述:
给定一个文本序列: 其中n为句子的长度,我们需要在序列X中找到每一个实体,并且
进行标注,
是预先定义的labels集合。
数据集构建:
首先将NER数据集转为(question,answer,context)三元组。对于每个tag type ,都会有一个问题
,
是生成问题的长度。标注实体为
是一个子串,每一个实体都会有一个golden标签
,通过生成问题
,可以获得三元组
。
问题生成:
这是最关键的一步,论文利用annotation guideline notes作为参考进行构造答案。annotation guideline notes是为标注工作提供依据。Guideline为tag定义类别并能够归纳类别和准确为人类标注提供了注释防止歧义。下图为例子:

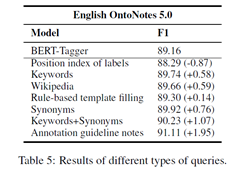
为什么选择guideline这个方法,是因为论文探索不同的方法去生成问题以及评估他们的效果,发现guidline最好。探索过程如下:
- Position index of labels:使用index tag进行构造问题如,“one”、“two”
- Keyword:问题是描述tag的关键词,如:查询ORG tag的问题是organization
- Rule-based template filling:问题生成基于模板,对ORG tag的问题是:“which organization is mentioned in the text”。
- Wikipedia:使用wikipedia的定义进行构造问题,ORG tag的问题为:“an organization is an entity comprising multiple people, such as an institution or an association”
- Synonyms:从牛津词典中抽取与tag相近的同义词。ORG tag的问题为association
- Keyword+Synonyms:连接关键词和同义词
- Annotation guideline notes:该论文使用的方法,ORG tag的问题为:“find organizations including companies, agencies and institutions”
在后面做实验进行对比,结果如下:
模型:
使用BERT作为baseline,输入形式为![]() 。输出为context representation 矩阵
。输出为context representation 矩阵![]() 。d 为BERT最后一层vector维度。
。d 为BERT最后一层vector维度。
区间选择:
论文中采用了两个二分类器,去判断每个![]() 是否为start,是否为end。
是否为start,是否为end。
Start index预测如下:
![]()
![]() 是权重,
是权重,![]() 代表了start的可能性。
代表了start的可能性。
End index也类似如上的公式
Start-End匹配:
对于文本![]() ,可能有多个同类实体,这意味着有多个start和end下标会被预测出来。找到start对应的end也需要去进行匹配。
,可能有多个同类实体,这意味着有多个start和end下标会被预测出来。找到start对应的end也需要去进行匹配。
对![]() 和
和![]() 每一行做argmax,得到了两个长度为n 的one-hot 编码的向量,记作
每一行做argmax,得到了两个长度为n 的one-hot 编码的向量,记作![]() 和
和![]() 。
。
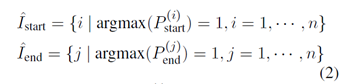
上标![]() 代表矩阵的第
代表矩阵的第![]() 行,
行,![]() 、
、![]()
![]()
简单的说,对于![]() 中,子序列
中,子序列![]() 属于实体的概率为矩阵E 中start和end 所在行的两个向量先concat 然后乘参数m ,最后过一层sigmoid 函数即可。 m 是学习参数。
属于实体的概率为矩阵E 中start和end 所在行的两个向量先concat 然后乘参数m ,最后过一层sigmoid 函数即可。 m 是学习参数。
训练:
定义三个loss如下:
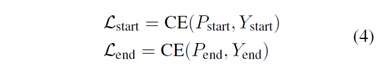
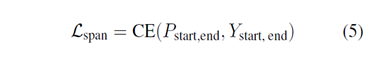
总loss如下:
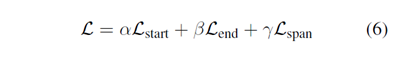
其中![]() 是超参,控制三个不同loss的贡献度。
是超参,控制三个不同loss的贡献度。
实验过程:
数据集:
ACE 2004, ACE 2005, GENIA,KBP2017,各自包含了24%、22%、10%、19%的nested NER。
ACE2004和ACE2005:包含7种不同的实体类型,对每类实体都有entity mentions and mention heads。
实验结果:
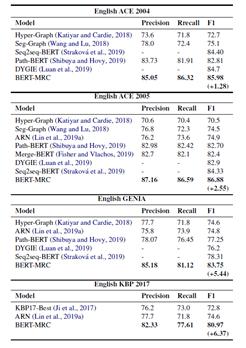
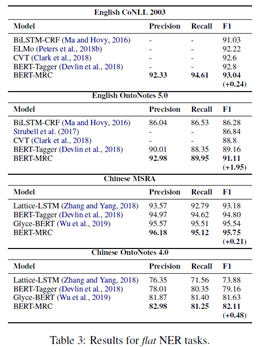
上图展示了基于BERT的MRC的模型表现,均达到最优。
Ablation studies:
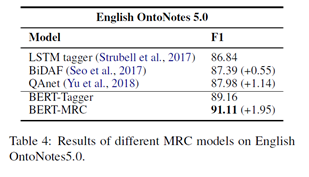
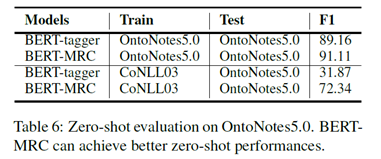
Zero-shot Evaluation on Unseen Labels:
训练模型在CoNLL 2003训练集,测试集为OntoNotes5.0。OntoNotes5.0包含18种不同类型,其中3种和CoNLL2003一样,15种模型没有见过。
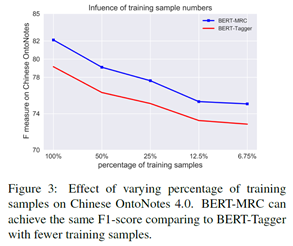
而且,相比BERT-Tagger来说,BERT-MRC达到同样效果所需要的数据量更少。
但是,看代码发现,直接使用guideline来进行问题生成
{"NR": "人名和虚构的人物形象","NS": "按照地理位置划分的国家,城市,乡镇,大洲","NT": "组织包括公司,政府党派,学校,政府,新闻机构"
}数据集:
{"context": "因 有 关 日 寇 在 京 掠 夺 文 物 详 情 , 藏 界 较 为 重 视 , 也 是 我 们 收 藏 北 京 史 料 中 的 要 件 之 一 。","end_position": [3,6,28],"entity_label": "NS","impossible": false,"qas_id": "2.1","query": "按照地理位置划分的国家,城市,乡镇,大洲","span_position": ["3;3","6;6","27;28"],"start_position": [3,6,27]}这样的问题生成和使用模板似乎并没有区别。
对最后的效果保持一定怀疑性。
而且,判断实体是对每个单词都进行二分类操作,判断是否为开始和结束index。

这篇关于《A Unified MRC Framework for Named Entity Recognition》ACL2020论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








