本文主要是介绍不懂抓包也能做APP爬虫?1招教你爬取抖音流行歌名,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
版权声明:允许转载,但转载必须保留原链接;请勿用作商业或者非法用途
此文章来源于项目官方公众号:“AirtestProject”
前言
说起APP爬虫,相信大家会很容易联想到一些抓包工具:Fiddler、Charles、mitmproxy和anyproxy等等。
借助这些抓包工具,我们可以知道APP在运行过程中具体发起了什么请求,之后我们就可以详细分析这些请求,再用程序模拟这些请求最终实现爬虫。
然而,在爬虫的实操中,APP的各种反爬措施也是不容小觑的,比如抓包失败、参数加密、代码被编译等等,都增加了我们爬取APP数据的难度。
那么作为一名不懂抓包的小白,是不是就无缘爬虫了呢?不要慌,今天我们就带大家 用airtest来实现1个模拟抓取的过程 ,把网易云音乐中抖音排行榜的100首歌曲名称爬取下来!
准备工作
为了 爬取抖音排行榜100首歌曲的名称 ,首先我们需要编写1个自动化脚本,在APP内打开这个排行榜,步骤如下:
- 1.连接测试设备
- 2.打开网易云音乐的APP
- 3.初始化poco
- 4.同意首页的服务条款弹窗
- 5.勾选用户协议并点击立即体验
- 6.点击输入按钮并输入“抖音”
- 7.点击搜索关键词并等待排行榜加载
- 8.点击进入抖音排行榜
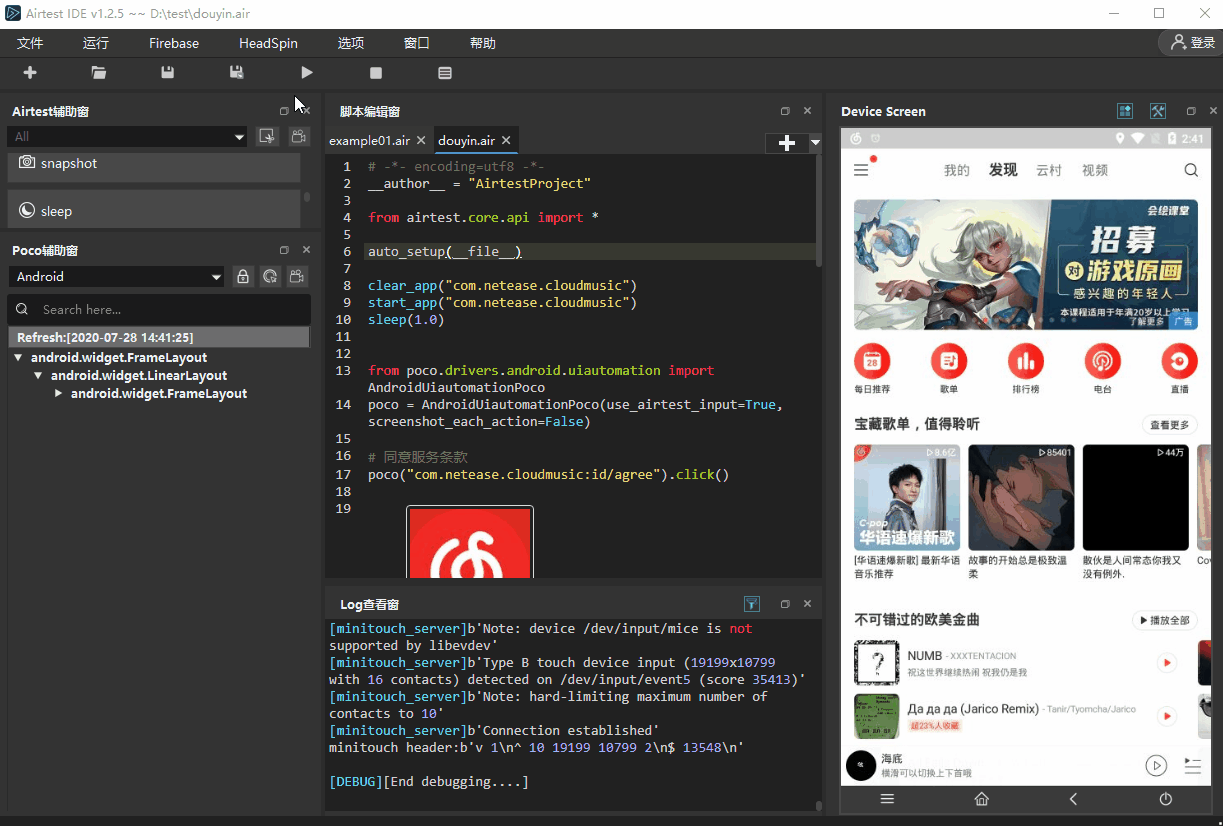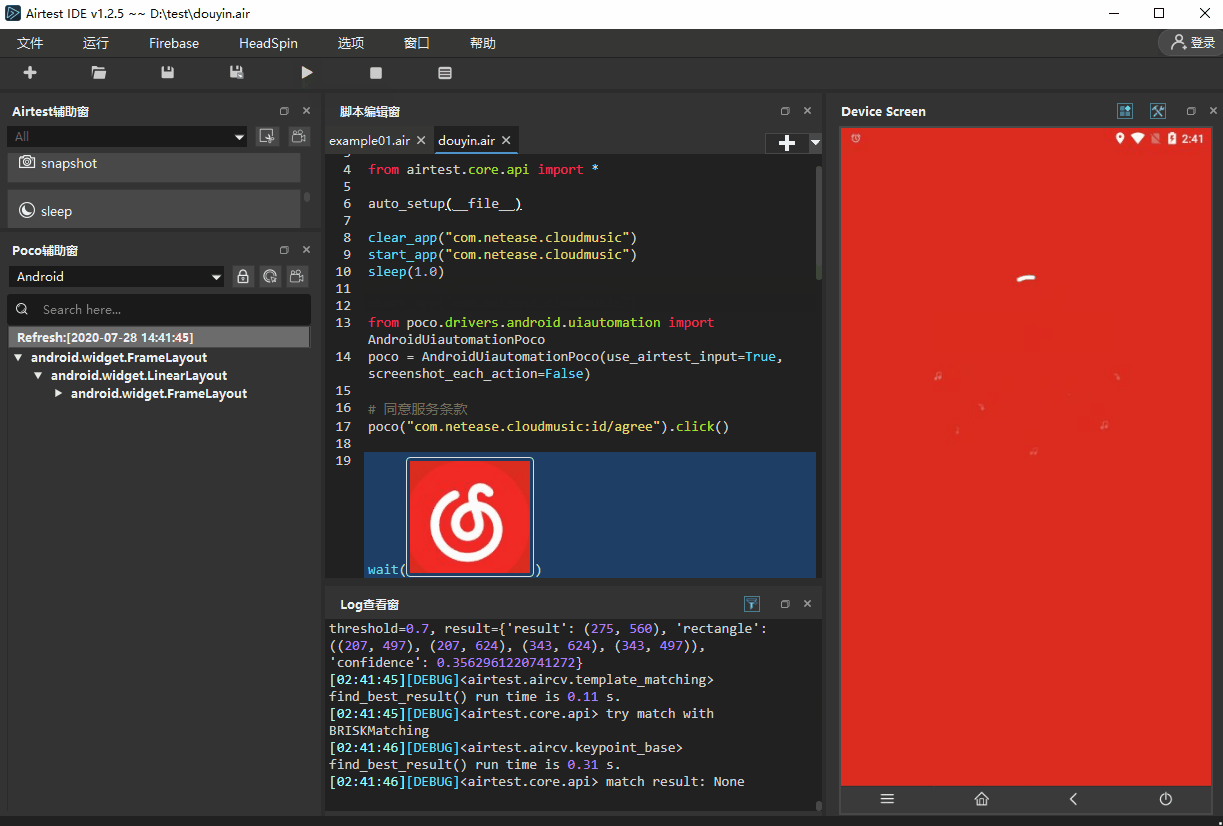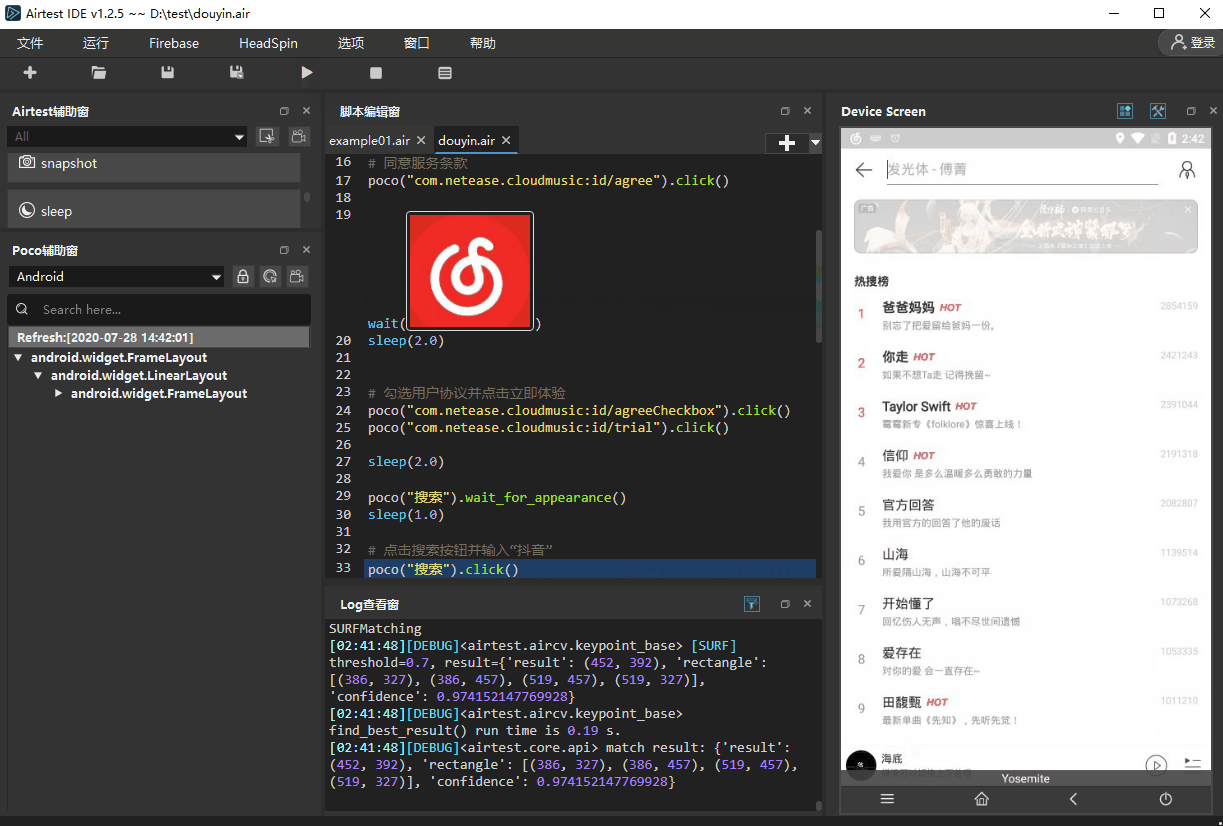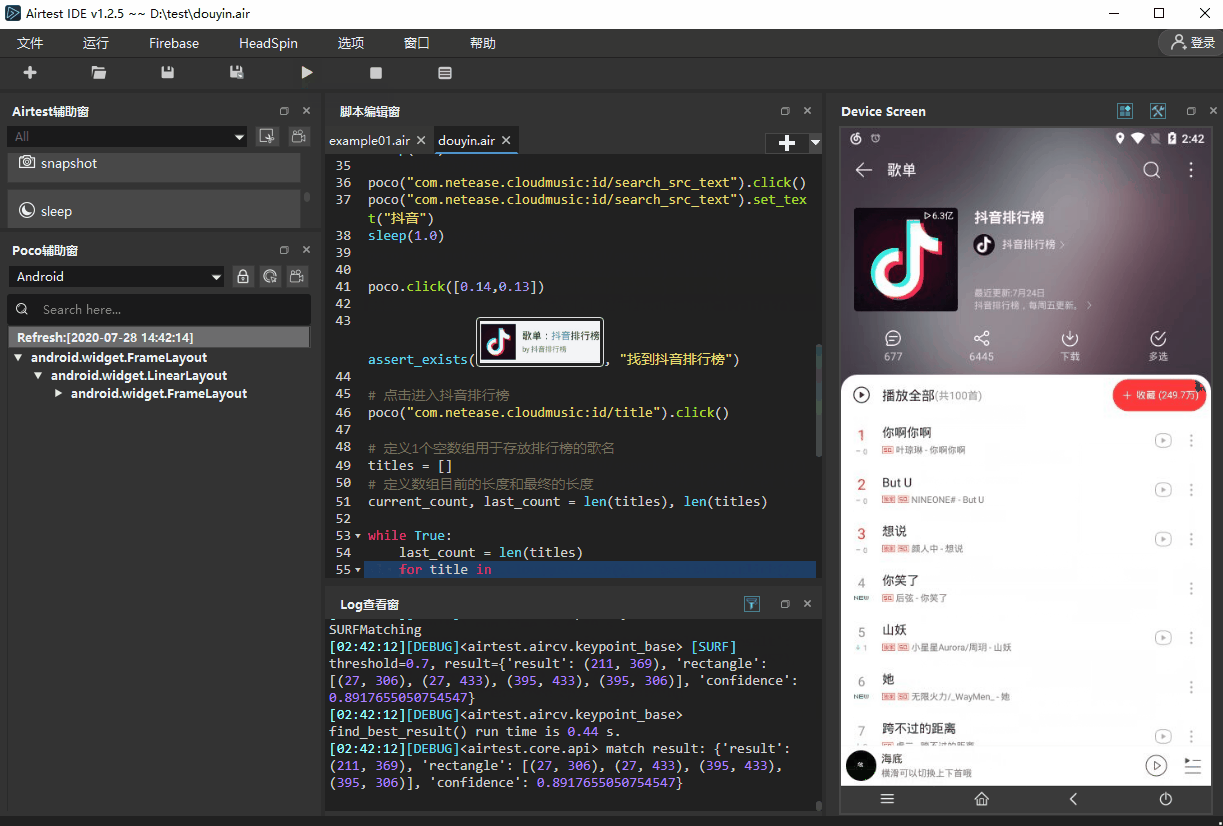
代码实现如下:
# -*- encoding=utf8 -*-
__author__ = "AirtestProject"
from airtest.core.api import *
auto_setup(__file__,devices=["Android://127.0.0.1:5037/emulator-5554"])clear_app("com.netease.cloudmusic")
start_app("com.netease.cloudmusic")
sleep(1.0)from poco.drivers.android.uiautomation import AndroidUiautomationPoco
poco = AndroidUiautomationPoco(use_airtest_input=True, screenshot_each_action=False)# 同意服务条款
poco("com.netease.cloudmusic:id/agree").click()wait(Template(r"tpl1595916981414.png", record_pos=(0.004, -0.452), resolution=(900, 1600)))
sleep(2.0)# 勾选用户协议并点击立即体验
poco("com.netease.cloudmusic:id/agreeCheckbox").click()
poco("com.netease.cloudmusic:id/trial").click()
sleep(2.0)poco("搜索").wait_for_appearance()
sleep(1.0)
# 点击搜索按钮并输入“抖音”
poco("搜索").click()
sleep(1.0)poco("com.netease.cloudmusic:id/search_src_text").click()
poco("com.netease.cloudmusic:id/search_src_text").set_text("抖音")
sleep(1.0)
poco.click([0.14,0.13])assert_exists(Template(r"tpl1595821867472.png", record_pos=(-0.283, -0.489), resolution=(900, 1600)), "找到抖音排行榜")# 点击进入抖音排行榜
poco("com.netease.cloudmusic:id/title").click()
其中需要注意的是poco的初始化顺序,先连接设备,再打开APP,最后才初始化poco,可以有效避免一些奇奇怪怪的错误。
爬取歌名
进入抖音排行榜的歌曲列表之后,我们先来观察下此刻的UI树结构:
从UI树中我们可以知道,歌曲名称这个控件,都在 musicListItemContainer 这个控件里面,所以为了获取歌曲名称,首先我们需要遍历所有加载出来的 musicListItemContainer ,再定位到歌曲名称的控件,依此来获取控件的 text 属性:
for title in poco("com.netease.cloudmusic:id/musicInfoList").child("com.netease.cloudmusic:id/musicListItemContainer"):a = title.offspring("com.netease.cloudmusic:id/songName")name = a.get_text()print(a)
获取完当前页面加载的所有歌曲名称之后,我们可以通过向上滑动列表,来不断加载新的歌曲控件。
但这时候,我们还需要解决2个问题:
① 我们单次向上滑动歌曲列表,并不能保证当前加载出来的歌曲控件都是新的控件,有可能某些控件里面的歌曲名称我们已经获取到了,那么 如何解决获取歌名重复的问题呢 ?
我们可以事先定义好1个空的数组,将获取到的歌曲名称放到数组里面,在放入歌曲名称之前,做1个判断,放入数组的歌名不能与数组已经存在的歌名相同,这样子就能够保证我们每次放入的都是新的歌名;
② 多次滑动列表之后,我们 如何判断所有歌曲名称已经获取完毕呢 ?很简单,我们可以设置1个数组长度的计数器,当数组长度不再增加,即没有新的名字被添加到数组的时候,既可以认为我们已经把排行榜的歌曲名称获取完了。
最终实现的效果如下:
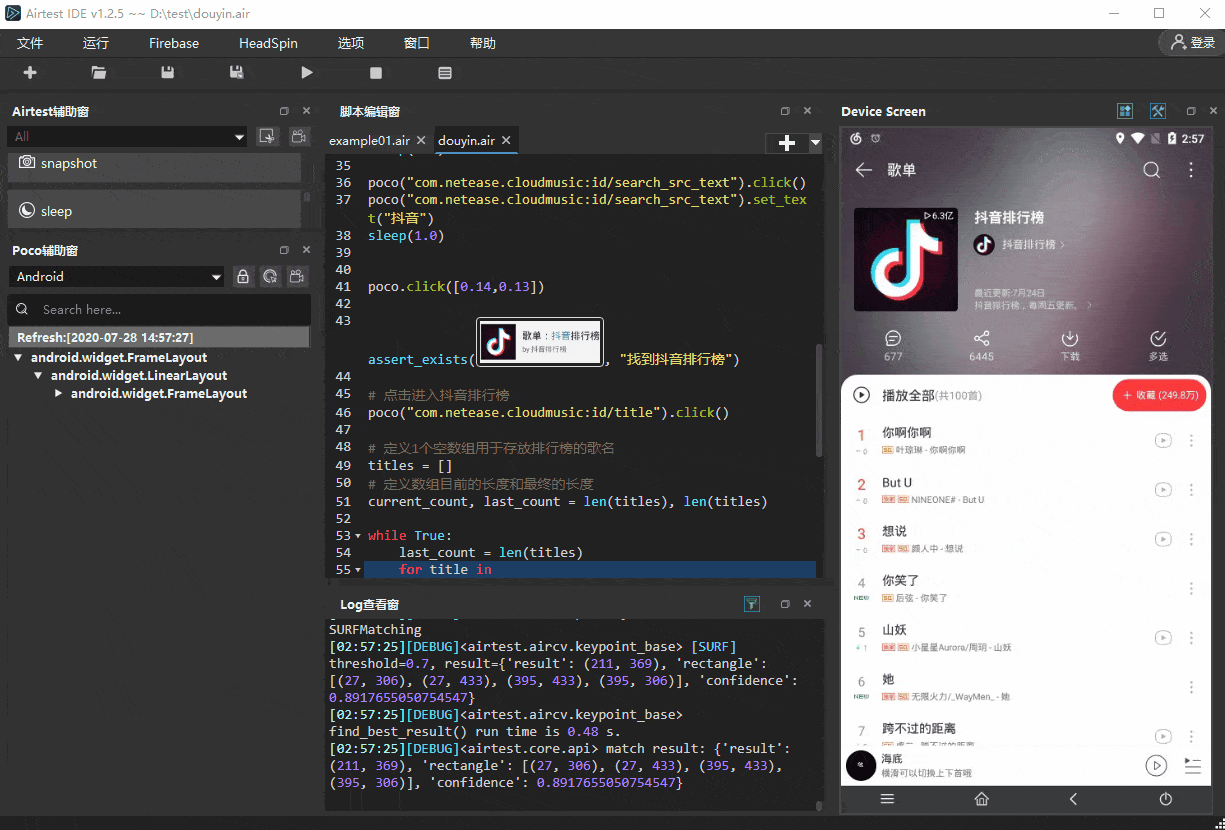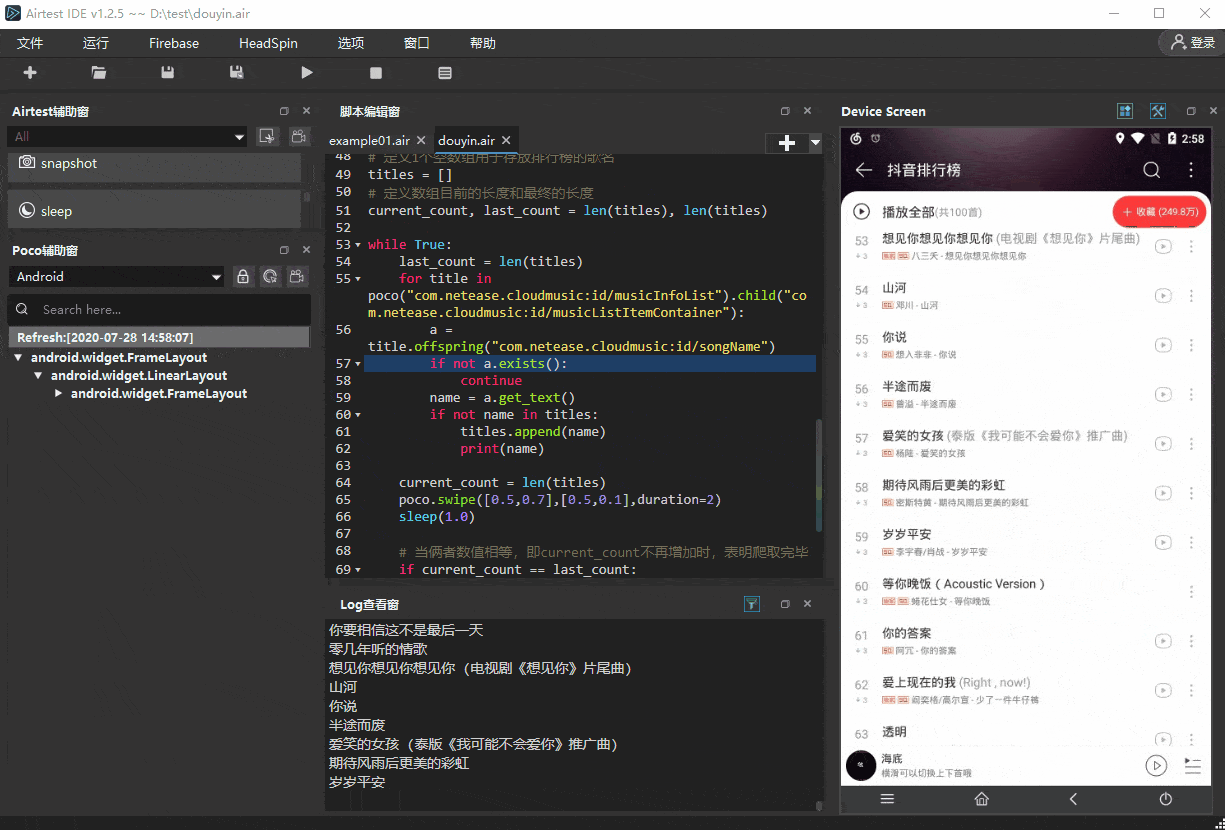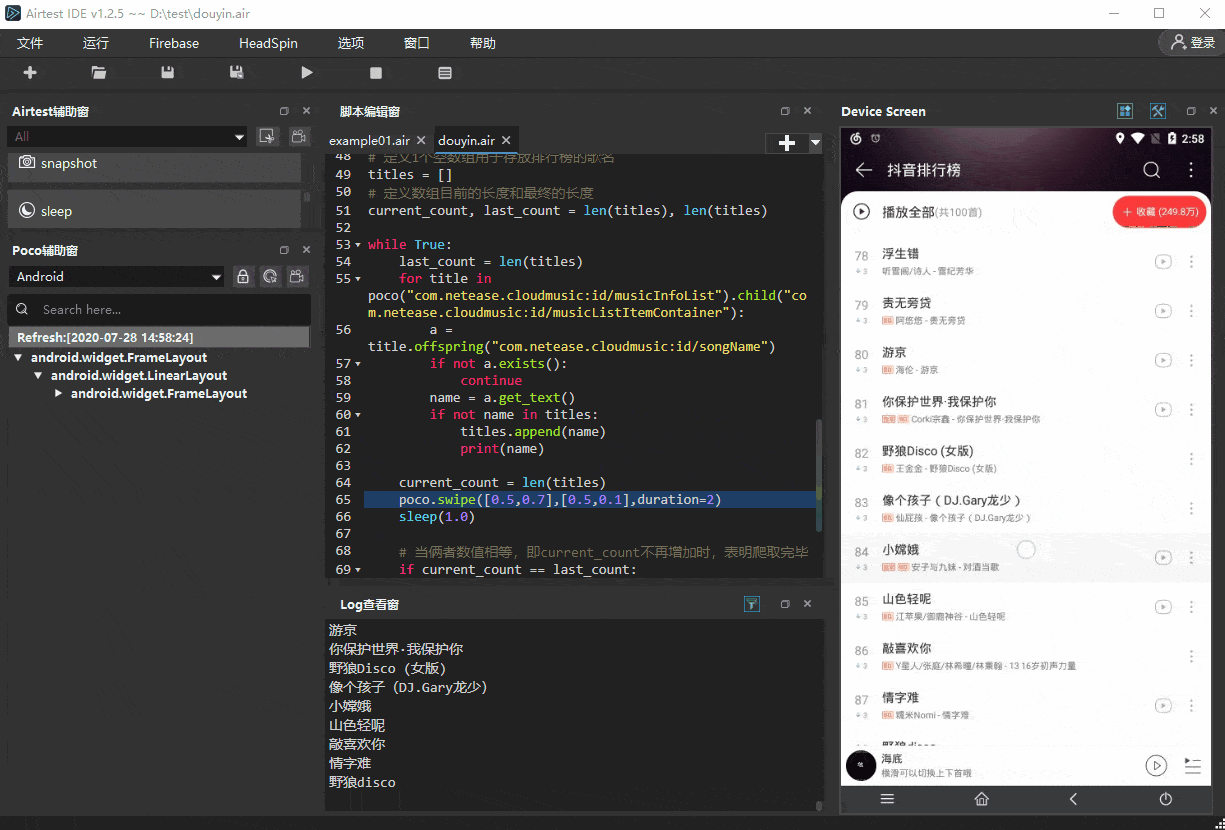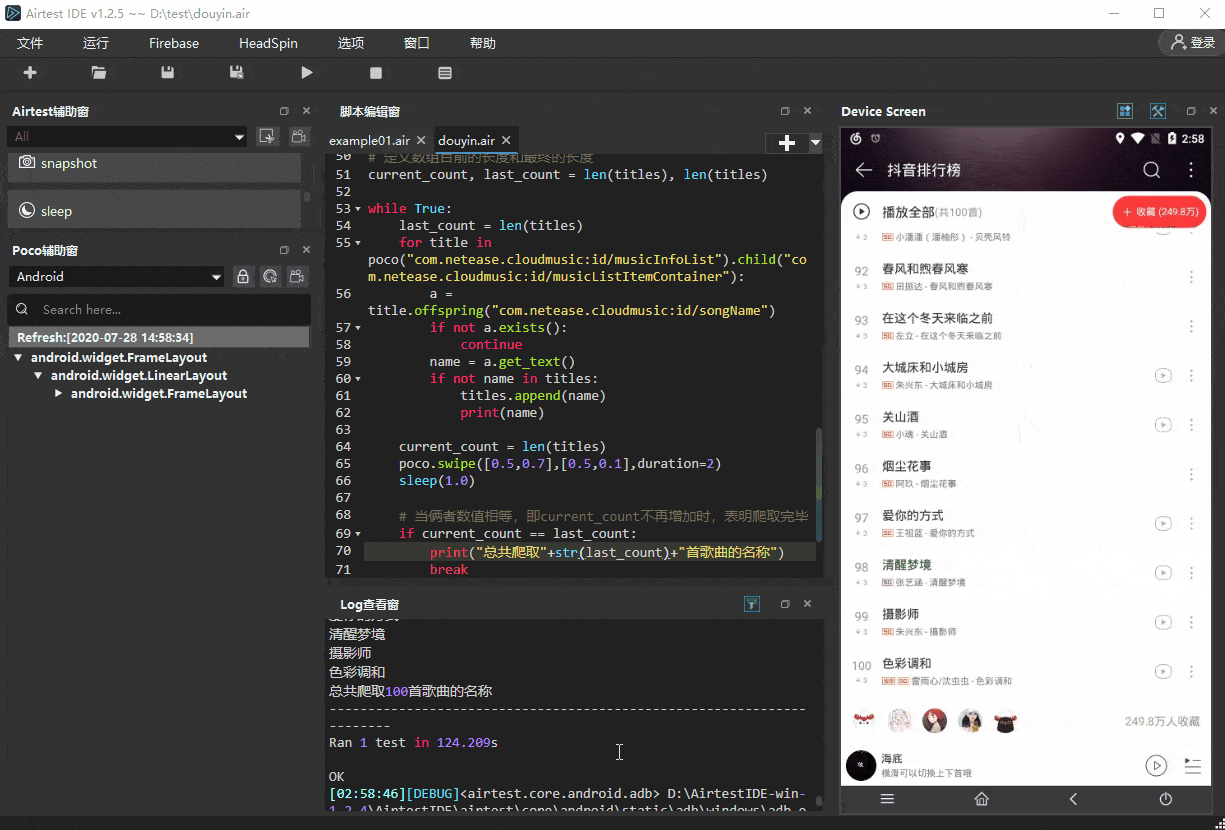
# 定义1个空数组用于存放排行榜的歌名
titles = []
# 定义数组目前的长度和最终的长度
current_count, last_count = len(titles), len(titles)while True:last_count = len(titles)for title in poco("com.netease.cloudmusic:id/musicInfoList").child("com.netease.cloudmusic:id/musicListItemContainer"):a = title.offspring("com.netease.cloudmusic:id/songName")if not a.exists():continuename = a.get_text()if not name in titles:titles.append(name)print(name)current_count = len(titles)poco.swipe([0.5,0.7],[0.5,0.1],duration=2)sleep(1.0)# 当俩者数值相等,即current_count不再增加时,表明爬取完毕if current_count == last_count:print("总共爬取"+str(last_count)+"首歌曲的名称")break
小结
上述就是利用airtest实现模拟爬取的全部过程。当然,我们不仅可以把爬取的歌曲名称打印在log查看窗中,还可以将它保存在指定的文档中,这个大家可以尝试着自己实现一下。
Airtest官网:http://airtest.netease.com/
Airtest教程官网:https://airtest.doc.io.netease.com/
搭建企业私有云服务:https://airlab.163.com/b2b
这篇关于不懂抓包也能做APP爬虫?1招教你爬取抖音流行歌名的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








