本文主要是介绍佩奇扑街、外星人疯狂!Python 告诉你大年初一应该看哪部电影,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者 | 罗昭成
责编 | 唐小引
本文首发于 CSDN 微信(ID:CSDNnews)
1. 引言
2019 年 1 月,《啥是佩奇》短片在互联网快速传播,各大社交平台形成刷屏之势。不到 24 小时,官博发出的视频已经收获 2800 万次观看,14 万次点赞,17 万次转发。
作为《小猪佩奇过大年》先导片,片中内容不仅引人深思,也把我们的视线拉了到春节档电影。在外工作一年,难得的几天闲暇时间,回到家里,陪陪父母,看看孩子。可以和父母一起去看看电影,重温一家人的温暖。
扎堆上映的一大波影片让我们眼花缭乱,在众多电影中,我们应该选择哪一步电影来看呢?下面,我们用数据来分析分析,看看其他人都在看啥电影,让我们从选择恐惧症中解放出来。
2. 猫眼预售票房数据分析
和之前文章不同,本次爬取的电影都还没有上映,所以笔者将侧重点从评论数据,转移到了其他地方,来进行我们想要的数据分析。
首先我们先来看看,春节档的票房数据,打开猫眼专业版实时票房,我们可以看到某一天的票房数据。
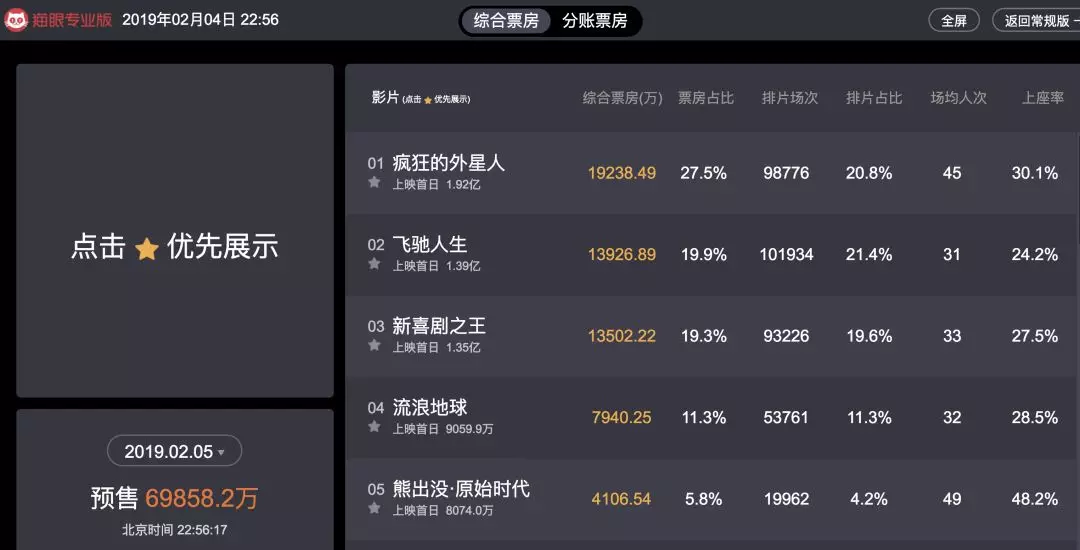
此图截于大年三十晚,可以看到《飞驰人生》在大幅上升,已经赶超《流浪地球》
虽然能看到,但是要进行分析,还是不太方便,所以先把数据都抓取下来:
作者注:抓取分析数据截止时间为 2019-02-03 18:38:49,并非最新数据,可能存在误差。
- 使用 Chrome 的调试模式,在网络请求中可以看到获取实时数据的网络请求:
https://box.maoyan.com/promovie/api/box/second.json?beginDate=20190205
拿到接口,就可以很简单地将数据拿下来,并存储起来。
- 发送网络请求
Python 的 Request 库可以很方便地发送网络请求,代码如下:
def requestData(url, params):session = requests.Session()headers = {"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X)","Accept": "application/json","Connection": "keep-alive","Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6","Accept-Encoding": "gzip, deflate"}response = session.get(url, params=params, headers=headers)if response.status_code == 200:return response.textreturn None
给定一个 URL 地址,和上行的参数,调用此方法,就可以模拟浏览器将数据拿回来。
- 存储数据到数据库中
Python 中还有一个 JSON 库,可以方便地解析 JSON。本文中,也是使用的它来进行的数据解析。因为数据抓取了很多天的预售票房数据,所以在存储的时候,使用 movieId 和 date 组合为每一条数据的唯一 ID。为方便后面处理数据,减少网络请求,所以将所有的原始数据保存起来。代码如下:
def saveItem(date, jsonStr): dic = json.loads(jsonStr)["data"]boxUnit = dic["totalBoxUnitInfo"]dataList = dic["list"]for item in dataList:movieId = item["movieId"]if item["releaseInfo"] == u"上映首日" or item["releaseInfo"] == u"上映2天" or item["releaseInfo"] == u"上映3天" :insertPiaofangMovieInfo(str(movieId) + "_" + date, date, movieId, item["movieName"], item["boxRate"],item["boxInfo"],boxUnit ,item["showRate"],item["showInfo"],item["avgSeatView"],item["avgShowView"])
在猫眼实时票房中,我们可以看到《疯狂的外星人》票房最高。但并不太能直观的感受到和其它几部电影的差距,可视化展示数据能够更加友好,这里使用了 pyechats 来进行数据渲染。看图说话:
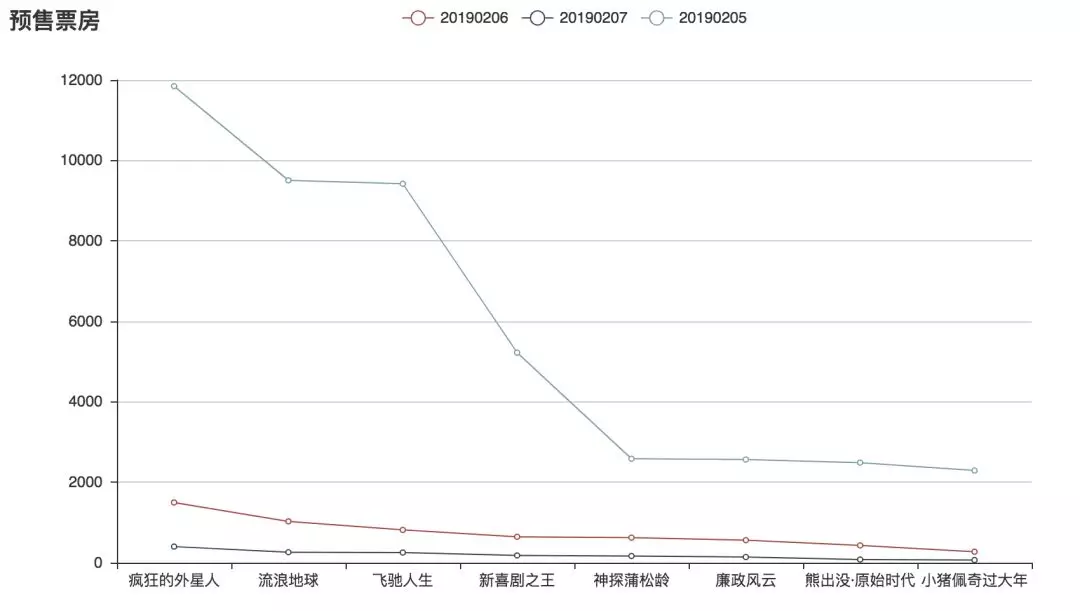
在图中可以看到《疯狂的外星人》的票房要选高于其他电影,而截止 2 月 3 日晚,《流浪地球》与《飞驰人生》的票房相当(编者注:随后在除夕夜《飞驰人生》赶超)。前段时间刷屏的《小猪佩奇过大年》的票房数据落底,实在有点令人吃惊,看这个数据,佩奇再红,还是干不过熊大熊二。

为了更好地给大家作参考,笔者还抓取了春节档电影的“想看”数据。
接口:http://m.maoyan.com/ajax/detailmovie?movieId=movieId
拿到这些数据,绘制了一个折线图:
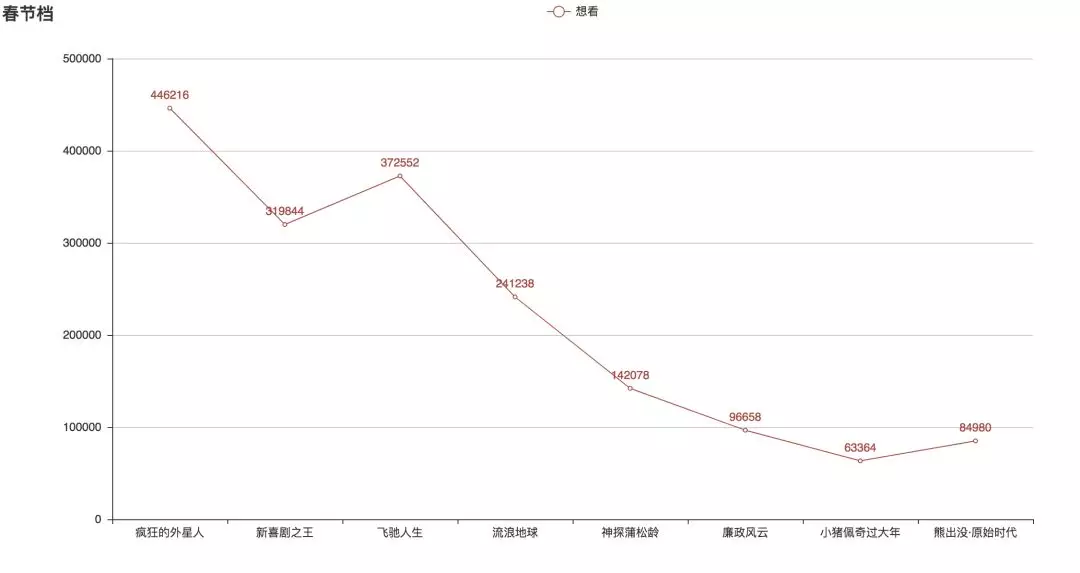
综上我们可以看到,无论是实实在在的预售票房,还是众口热议的口碑上,《疯狂的外星人》都是实质名归的赢家,笔者也建议有时间的朋友去看看。
另一方面,周星驰的《新喜剧之王》的想看量在 319844,位于春节档的第三位。首日的数据票房却只有不到 6000W,难道是朋友们都还在上班,我们欠星爷的电影票还要继续欠着?

3. 史上最强春节档的评分对比
分析完上面的票房与观众想看的数据过后,猫眼中还有关于春节档节目的短评数据,用户也给了相应的评分。凭借对导演与演员的信任度,给出了相应的评分。
先将评论数据抓取到本地存储。
接口: http://m.maoyan.com/review/v2/comments.json
代码如下:
def saveComment(movieId, comment):conn = sqlite3.connect('spring_festival.db')conn.text_factory = strcursor = conn.cursor()ins = "insert into comments(id, movieId, content, gender, nick, score, original) values (?,?,?,?,?,?,?)"v = (comment["id"], movieId,comment["content"], comment["gender"], comment["nick"], comment["score"], json.dumps(comment))cursor.execute(ins, v)cursor.close()conn.commit()conn.close()
评分图如下:
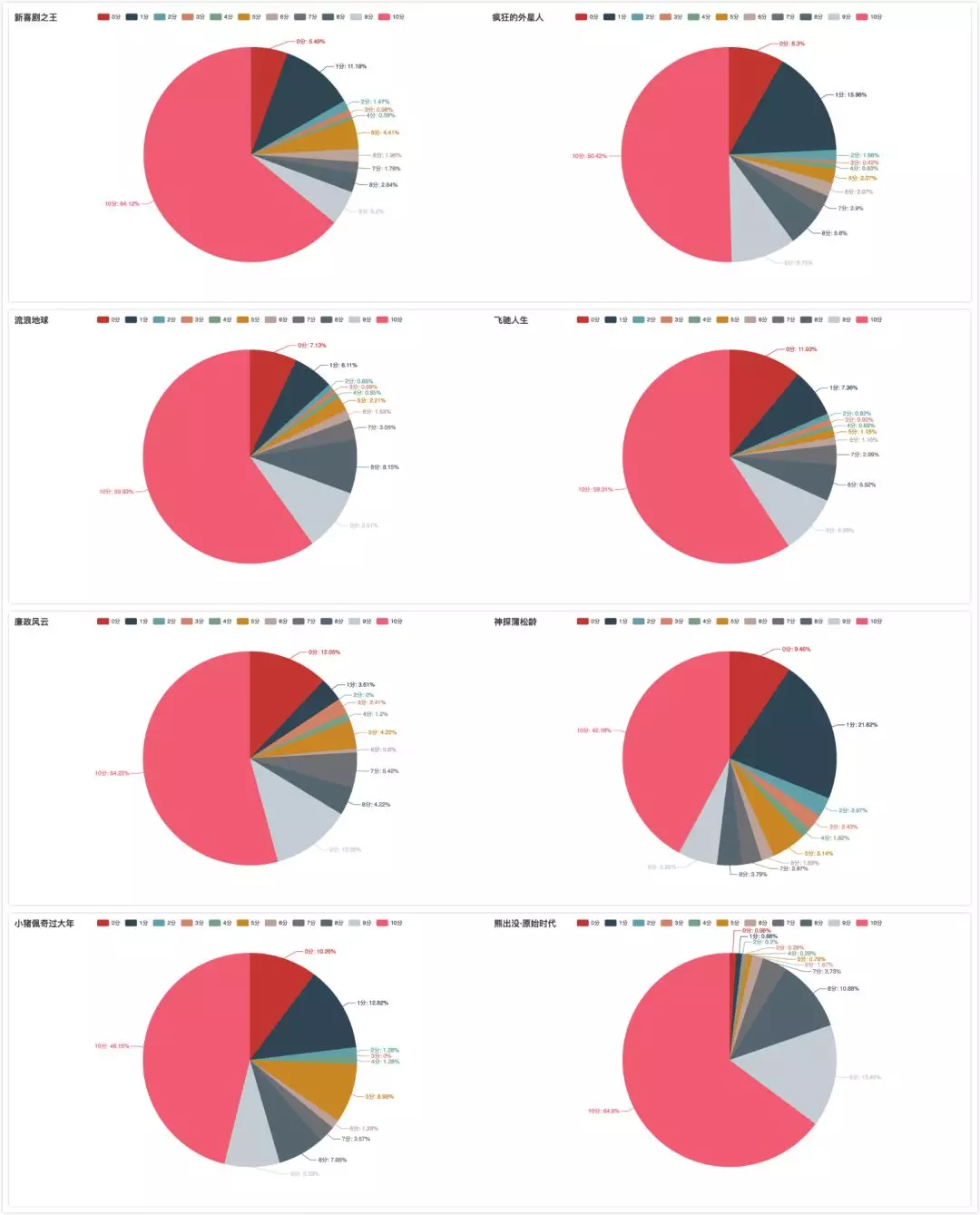
从上图我们可以明显地看出,春节档之中,观众朋友对《新喜剧之王》、《流浪地球》、《飞驰人生》、《廉政风云》、《熊出没-原始时代》明显有超高预期,而如《神探蒲松龄》、《小猪佩奇过大年》,观众对其预期明显比其他电影要低。很难想象,前不久的《啥是佩奇》掀起全民佩奇热,尤其今年还是佩奇年的时候,这股热潮并没有直接反应到佩奇的年度大戏中,而今年春节档唯一一部古装戏,且有成龙大哥坐镇的《神探蒲松龄》也并没有打动观众。
评论词云

最后,我们再以词云来综合看一下以上所有电影的评论关键词,除却“期待”之外,可以显著地看到“沈腾”、“黄渤”、“流浪地球”,这人心所向一定程度上是极大的认可,只不过比较让人疑惑的是,为什么风评不错的《流浪地球》,甚至一度有其(流浪地球)的出现“开启了中国科幻电影‘元年’,可以称得上是春节自救指南,带你流浪人生”这样非常高的赞誉之声,但为什么这一切没有直接体现在票房上?此外,对于春节而言,所求无非是阖家欢乐,无论看什么,最重要的,还是一起看的人。
谨以此文,祝所有程序员朋友新春大吉,阖家欢乐,幸福团圆!
这篇关于佩奇扑街、外星人疯狂!Python 告诉你大年初一应该看哪部电影的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







