本文主要是介绍Boosting Scene GraphGeneration with Visual Relation Saliency 阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
标题分析
Boosting SceneGraph Generation:论文目的
Visual RelationSaliency:论文方法,利用关系的视觉 显著性改善SGG效果
动机
任务:生成带有关系 显著性的场景图。如图1(a),我们看向这张图时会把注意力放在<woman-holding-bat>和<bat-hitting-ball>两个三元组上,自发的描述相对重要的关系,而现有场景图方法不具备这种感知关系的视觉 显著性的能力,这不符合人类看图像的本能,并且由于场景图内信息太过琐碎,可能导致下游任务在进行时受到干扰。
这是否是一个新的细分任务?不是,生成带有关系 显著性的场景图最早由Sketching Image Gist(2020 ECCV)提出,这篇论文还构造了VG-KR数据集,本文的实验主要是在VG-KR上做的。
本文提出Saliency-guided Message Passing(SMP)结构,在普通场景图模型的基础上,引入了 显著性估计分支,对场景图内的关系进行打分(分高即重要),经过排序后筛选出场景内的重要关系并显示,如图(c)。
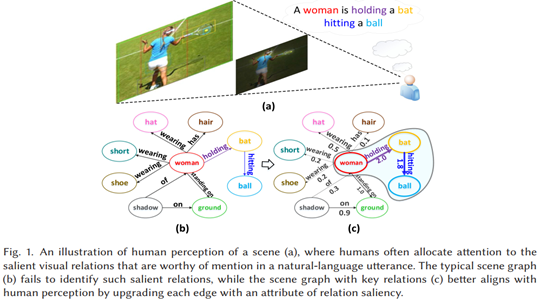
图1 对动机的解释图
贡献
SMP引入了关系 显著性估计模块,使用该模块估计的重要关系引导场景图生成。
本文在VG-KR和VG150数据集上进行实验,证明了SMP在场景图生成上的可行性。
方法概述
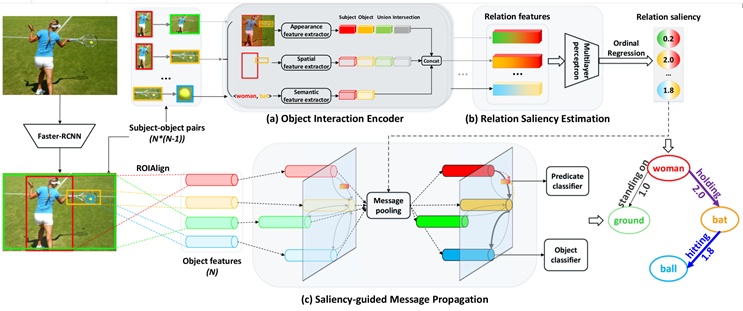
图2 方法框架图
如图2,SMP使用Faster R-CNN作为object detector,先分割出个物体对的图像,输入至物体交互编码器(a),对每一个物体对从外观、空间和语义三个角度挖掘关系信息。将每个物体对的三组特征经过拼接后,得到的个关系特征,输入到关系显著性估计模块(b),通过序数回归来估计每个物体对的关系视觉 显著性分数,将分数和关系特征传入重要性引导的信息传播模块(c)。在(c)中对分数、原始物体特征和关系特征进行信息聚合操作,利用得到的 显著性信息不断更新物体和谓词特征。最后对物体及其谓词进行预测,实现了用重要关系改善场景图的生成的目标。
具体方法
关系特征提取
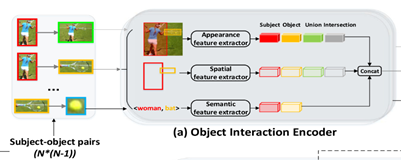
对分离出的个可能的主宾物体图像,使用三个不同角度的特征提取器,提取特征并拼接,得到关系特征。
Appearance Feature Extractor
使用ROIAlign提取主语框、宾语框、两框并集、两框交集处的外观特征,后经过两层使用ReLU激活函数的全连接层,将各外观特征转换为低维向量,两物体的目标框之间没有并交集的话用全0向量表示。最后把四个框的特征串联,就是输出的外观关系特征。
Spatial Feature Extractor
对主语框、宾语框、两框并集、两框交集处的空间特征进行提取,每个边界框的空间特征b统一表示为:
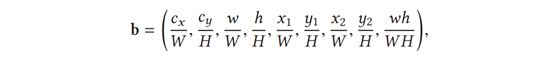
x1y1 x2y2:分别表示边界框的左下和右上坐标
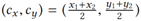
:框的中心点
W H:整张图像的宽和高
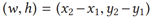
:框的宽和高
同样,两目标框之间没有并交集用全0向量表示。对空间特征使用另一个全连接层,将空间特征映射成一个高维向量。最终输出的空间关系特征由四个框的特征串联。
Semantic Feature Extractor
主语和宾语的语义特征表示为:
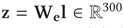
为类别嵌入空间,l是以物体类别为维度的独热向量,串联主语和宾语的语义特征为输出的关系语义特征。
最后对外观、空间、语义三个角度提取的特征,生成关系特征。
关系 显著性估计
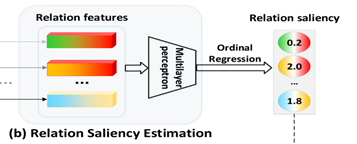
不同等级的 显著性通常以有序的评分机制表示(0,1,2分别表示没有关系,不重要的关系和 显著的关系),因此本文将关系 显著性估计任务类比为序数回归(Ordinal Regression,OR)任务。为什么使用序数回归? 显著性分数的类别间具有顺序联系,比如在训练时,若GT score =1,模型预测分数为2和为3时包含的信息量是不同的,分数为2时的得到的损失更小,但如果使用逻辑回归的话分数为2和3得到的损失相同,体现不出差异。
实现过程:定义第i个物体对的关系特征为,关系为,关系 显著性分数。关系 显著性可以按等级分为{0,1…S-1}(S在VG-KR数据集中取3)。序数回归将关系 显著性估计任务分成S-1个简单的二分类子任务,每个子任务都在判断
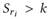
是否成立(k∈{0,1...S-2}),并输出概率值,子任务通过MLP实现,输入特征,输出k个概率值,表示为
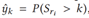
对任意关系的 显著性得分为每个子任务成立的概率加和,即:
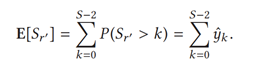
显著性引导的信息传播
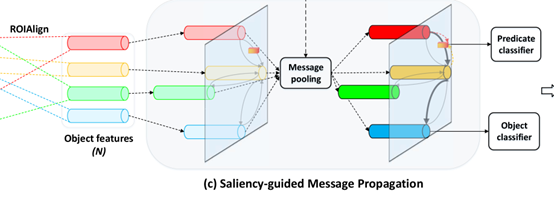
表示通过ROIAlign获得的目标特征。表示通过对象交互编码器(a)得到的关系特征,其中相应的i→j关系 显著性分数为,以i为例,i的节点信息中包含了关系最重要的K*2(inbound&outbound)个节点的特征,计算方式如下:
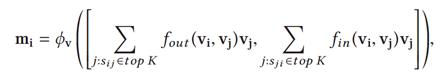
(,): concat操作
φv:映射函数,本质是具有LeakyReLU非线性激活函数的全连接层。
sij,sji:可以理解为节点i与它的出站境(outbound)节点/入站境(inbound)节点的 显著性分数。
top K:取 显著性分数前K个邻居节点形成集合,本文K取4。
fout fin:注意力权重函数,通过一层使用softmax正则化的全连接层实现,下标out和in表示outbound/inbound节点。
接下来计算i→j的边信息,它包含了i和j的目标特征:
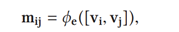
φe:映射函数,本质是具有LeakyReLU非线性激活函数的全连接层。
根据两组信息(类似于Motifs的上下文信息)使用GRU不断更新节点特征和边特征,通常迭代2次,更新后的特征分别送入分类器中生成目标类别和谓词类别。
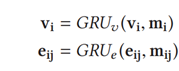
训练部分
在训练阶段, 显著性分数部分的损失函数表示为
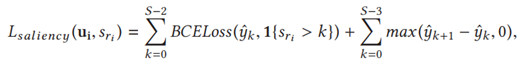
BCELoss:二元交叉熵损失,
sri:关系 显著性分数的GT值
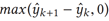
:求两项的最大值,损失函数的后半部分为了防止预测不合理的情况出现,比如
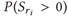
对目标分类的损失函数

Nobj:场景图中节点的数量
fobj:目标分类器预测的概率分布
yi:GT标签
CE:交叉熵损失
对关系分类的损失函数
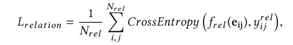
:场景图中关系的数量
:谓词分类器预测的概率分布
:GT标签
总体损失函数为:
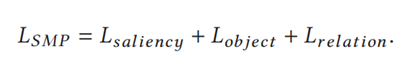
实验
数据集
VG-KR:和传统的VG数据集相比,该数据集新增对关系显著性的标记,包含250755个谓词,其中101312个谓词被标记为关键/ 显著关系。
VG150:包含108,073张图片,150个对象类别和50个谓词类别。在场景图实验上广泛应用
任务分类
三个子任务:PREDCLS,SGCLS,SGDET
评价指标
kR@K:在前K(K=1,5)个预测的三元组中的关键关系召回率,由于引入了关系重要性得分,三元组的排名分数计算方式变为
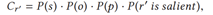
R@K
实验结果
性能实验
表1 VG-KR上的性能实验
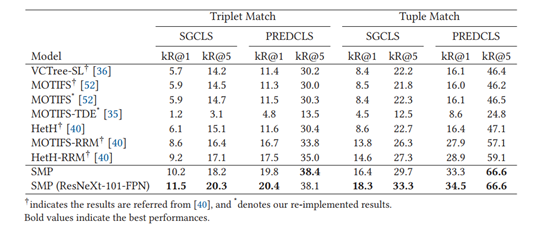
如表1,加粗为最好结果,SMP在VG-KR数据集上的表现达到了SOTA,说明模型对关系 显著性的感知能力极强。下图为SMP和Motifs的对比实验,在SGCLS任务下,每个谓词类别前20名的召回率进行比较,谓词类别按照SMP与Motifs的差异排序,结果表明SMP能够识别"动词"的视觉关系,Motifs在这方面做得很差(Recall@20=0)。
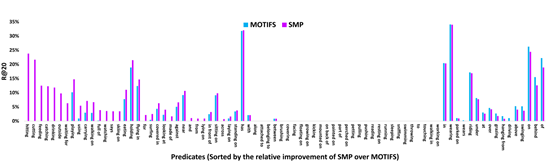
表2 在VG-150上的性能实验
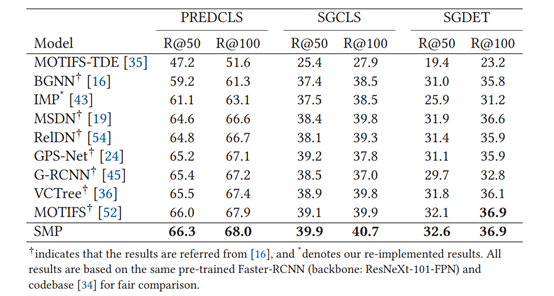
如表2 ,SMP模型在传统场景图生成任务上,也有不错的表现,这也证明了根据关系 显著性生成的场景图,能过滤掉部分琐碎信息(噪声标签)。
消融实验
表3 在VG-KR上的SGCLS任务进行消融实验
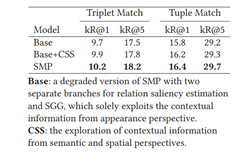
Base:估计关系 显著性的分支中,只用到外观特征CSS:既用外观特征,又用空间特征。当把外观、空间和语义特征充分融合时,性能最好。
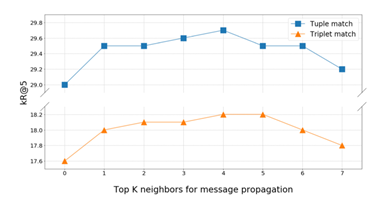
图4 对邻居节点个数K进行的超参消融实验
图4实验在SGCLS子任务上进行,Tuple match:要求三元组主语和宾语与GT匹配,Triplet match:要求三元组主语、宾语和谓词都要与GT匹配,K=0时,SMP为普通的场景图模型,K=4性能最好,之后的性能随着K增加变差,推测是由于预测了噪声三元组。
思考
论文不足:
本文和Sketching Image Gist: Human-Mimetic Hierarchical Scene GraphGeneration针对的任务相同,在实验时直接引用了对方的数据,但,感觉别的论文最起码会说一说方法的差异在哪,前人方法没针对什么问题等等,本文没怎么写这些。
论文好的地方:
本文针对下游任务进行分析,很清楚自己的定位和优势。
引入其他领域方法有序回归(最典型是用在年龄估计上)到场景图任务。
存疑的点:
实验中普通场景图模型(baseline)的kR@K计算方式(看引用文献)
评价指标里为什么没有m@K
想法:物体对的交并集对提取框的关系特征,是否总是有利,能否优化
补充部分:
两个任务(跨模态检索和图像描述)与场景图模型SMP结合的框架图
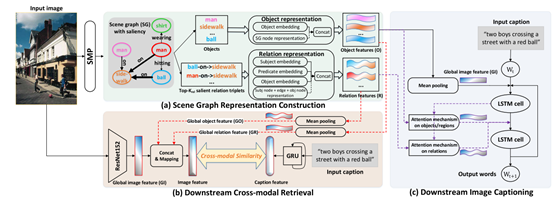
在跨模态检索上:
性能实验
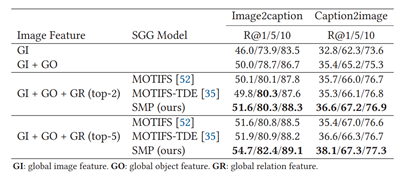
GI、GO、GR:在跨模态检索模型上利用了全局图像、目标、关系特征
评价指标R@K:召回率
可视化实验
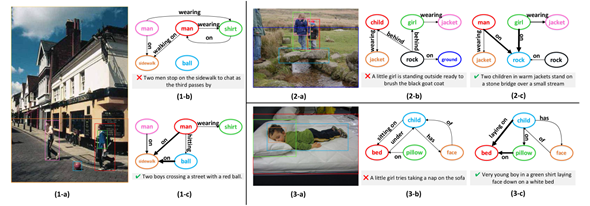
Motifs和SMP在image2caption任务上的可视化,如图1-a,图中最 关系应围绕“ball”展开,SMP在这方面做的出色,也提升了跨模态检索模型的性能。
在图像描述上:
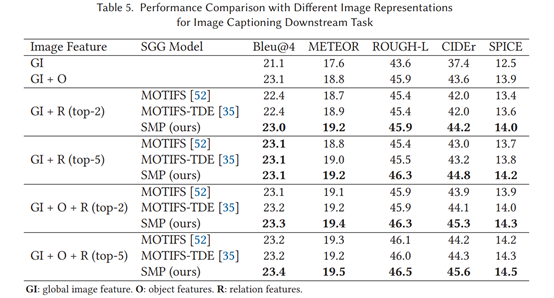
top-2/5:没找到相关解释,猜测是对生成的字幕评分排序?
评价指标
Bleu@n:将GT中的单词按顺序以n个为一组,与生成的字幕组与组之间对比,作为衡量生成文本与GT文本的相似度的指标。
METEOR:基于Bleu计算N-gram相似度,并计算查全率和查准率,并将二者调和平均作为评价指标。
ROUGH-L:
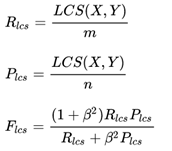
LCS(X,Y)是X和Y的最长公共子序列的长度,m,n分别表示GT字幕和生成字幕的长度,β是超参,通常设置为一个很大的数。
CIDEr:将句子的N-gram表示成向量,通过对每个n元组进行权重计算,然后计算生成字幕与GT字幕的余弦相似度,来衡量图像标注的一致性。与Bleu的区别就是,CIDEr指标将那些常常出现,但对视觉内容信息没有多大帮助的单词的重要性降低了。
SPICE:使用基于图的语义表示来编码字幕中的目标, 分布和关系。它先将待评价字幕和ground truth字幕用ProbabilisticContext-Free Grammar (PCFG) 编码成语义依赖树,然后用基于规则的方法把语义依赖树映射成场景图。最后计算待评价的字幕中目标、分布和关系的F-score。
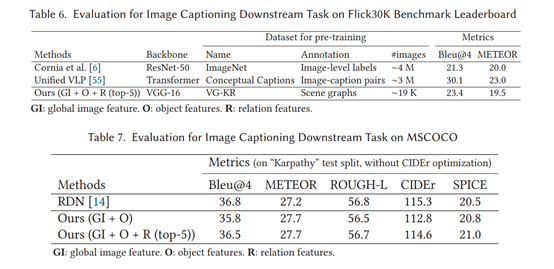
#images:用于预训练的图像数量
在不同数据集下做的实验,结果表明SMP对图像字幕任务有帮助。
这篇关于Boosting Scene GraphGeneration with Visual Relation Saliency 阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









