本文主要是介绍“奇怪的”WebRTC audio/video 丢包率,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前一段时间在给公司产品的弱网提示功能提供数据支撑的时候,是根据WebRTC抛来上的StatsReport中的packetsLost、packetsSent/packetsReceived作为计算的数据来源进行的。采用的丢包率算法是:
(单位时间内packetsLost差)÷(单位时间内packetsSent/packetsReceived差)= 单位时间内的丢包率
期初,我们采取的单位时间是1秒。即每1秒就计算一次丢包率。但从实际的数据上来看,会发生这样的现象:
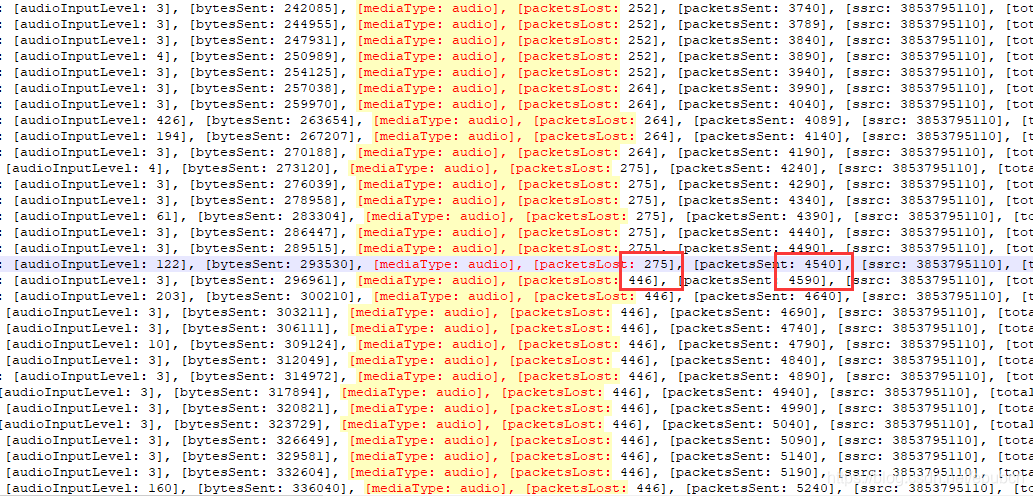
上图是通过WebRTC的StatsReport报上来的原始数据,每1秒打印一条,我过滤了其他,只保留了audio。从数据中我们很容易发现一个问题,就是每秒的packetsSent差都是50,但是packetsLost的值会发生275 -> 446 (差值171) 这种巨大的变化。
所以,如果我们按照单位时间1秒来计算丢包率,就会得到这样的结果:
(446-275) ÷ (4590-4540) = 171 ÷ 50 = 3.42 = 342%
显然如果我们按照单位时间1秒来计算丢包率是不合适的,否则就会出现上面展示的现象,上一秒的丢包率还是0,下一秒的丢包率就成了342%。
所以,我目前的处理方法是修改丢包率的计算公式,丢包率不再采用固定单位时间更新,而是根据丢包数发生变化的时候来计算。即当packetsLost发生变化时,记录当前packetsSent/packetsReceived数值,直到下一次packetsLost发生变化时,记录新的packetsSent/packetsReceived数值,丢包率的计算公式不变(还是本文一开始的),两次packetsLost差值作为分子,两次packetsSent/packetsReceived差值作为分母。得到最终的丢包率。这里的主要变化是不再考虑时间,即丢包率数值的更新不以某个固定时间来计算,而完全按照packetsLost发生变化才计算。
经过上面的调整以后,还是借用图中的数值。当packetsLost首次=275时,packetsSent=4240。之后过了7秒,packetsLost变为446,packetsSent变为4590,那么新的丢包率就是:
(446-275) ÷ (4590-4240) = 171÷350=0.4886=48.86%
这样处理后的丢包率数值看起来“更可信”一点。
欢迎读者提供WebRTC的audio/video更好的丢包率计算方法~
这篇关于“奇怪的”WebRTC audio/video 丢包率的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




