本文主要是介绍tds测量电路图_用于tds咖啡测量的过滤注射器似乎是不必要的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
tds测量电路图
As I poked around the World Wide Web, I came across a small study looking at filtering an espresso sample before taking a TDS (Total Dissolved Solids) measurement. TDS is widely used to measure coffee extraction as a more objective measurement of the quality of a coffee. This small study examined using a centrifuge for sample filtration as compared to a syringe filter. They compared centrifuge, syringe filter, and unfiltered samples across 20 shots split between two coffee beans over the span of a few weeks. They were meticulous about making sure the samples were good.
当我在万维网上闲逛时,我遇到了一项小型研究,目的是在进行TDS(总溶解固体)测量之前过滤浓缩咖啡样品。 TDS被广泛用于测量咖啡提取率,作为对咖啡质量的更客观的衡量。 与注射器过滤器相比,这项小型研究使用离心机对样品进行过滤。 他们比较了离心机,注射器过滤器和未经过滤的样品,这些样品在几个星期内分两次在两个咖啡豆之间进行了20次注射。 他们在确保样品质量方面一丝不苟。
However, I disagree with their findings, and I think they missed an opportunity because of the way they plotted the data. On the bright side, they seemed to have uncovered something interesting: there is a direct correlation and transformation between filtered samples and unfiltered samples. This means that even when measuring TDS without a filter, you can estimate the filtered TDS with good accuracy. In essence, using a costly centrifuge or costly syringe filters is unnecessary for measuring TDS at home or in cafe settings; the unfiltered measurement is reliable.
但是,我不同意他们的发现,并且我认为他们由于绘制数据的方式而错过了机会。 从好的方面来看,他们似乎发现了一些有趣的东西:过滤后的样本与未过滤后的样本之间存在直接的相关性和转换。 这意味着即使在不使用滤波器的情况下测量TDS的情况下,也可以以较高的精度估算滤波后的TDS。 从本质上讲,在家里或咖啡馆中测量TDS不需要使用昂贵的离心机或昂贵的注射器过滤器。 未经过滤的测量是可靠的。
研究 (The Study)
Previous data from Socratic Coffee suggests filtering results only improves precision. I took previously found filtering not to be useful enough to justify the cost. Ultimately, a centrifuge or syringe filters are quite expensive for a hobby that’s already very expensive.
来自Socratic Coffee的先前数据表明,过滤结果只会提高精度。 我认为以前发现过滤不足以证明成本合理。 最终,离心机或注射器过滤器对于已经非常昂贵的爱好来说是相当昂贵的。
This study took 20 samples across multiple days, multiple shots, split between two coffees. They then computed probability distributions to show the unfiltered samples were problematic. They showed the data in a table, but they didn’t plot the data as a scatter plot.
这项研究在多天的时间里拍摄了20个样本,多次拍摄,分为两杯咖啡。 然后,他们计算了概率分布,以表明未过滤的样本存在问题。 他们在表中显示了数据,但没有将数据绘制为散点图。
I was curious about the data, so I pulled it to take a look. If their data proved filtration was necessary, I would be more inclined to filter all of my results. However, there is a major cost hurdle to filtering samples which is syringe filters are expensive, and even if a centrifuge wasn’t expensive, it takes more time.
我对数据感到好奇,因此我拉动了一下。 如果他们的数据证明有必要过滤,那么我将更倾向于过滤所有结果。 但是,过滤样品存在很大的成本障碍,因为注射器过滤器很昂贵,即使离心机并不昂贵,也要花费更多时间。
数据 (The Data)
They made the raw data available, and I started with some scatter plots.
他们提供了原始数据,我从一些散点图开始。
A simple best fit linear line reveals an R^2 value of 0.68, which is quite high. So let’s cut the data again to the two separate roasts to see how that changes these trends.
简单的最佳拟合线性线显示R ^ 2值为0.68,这是相当高的。 因此,让我们再次将数据剪切到两个单独的烘焙中,以了解如何改变这些趋势。

Now the linear fits for each coffee is much stronger, which indicates a transformation will get you from filtered samples to unfiltered samples. Let’s line up samples and sort them but split by coffee:
现在,每种咖啡的线性拟合都更强,这表明转换将使您从过滤后的样本变为未过滤的样本。 让我们排列样本并对其进行排序,但按咖啡进行拆分:
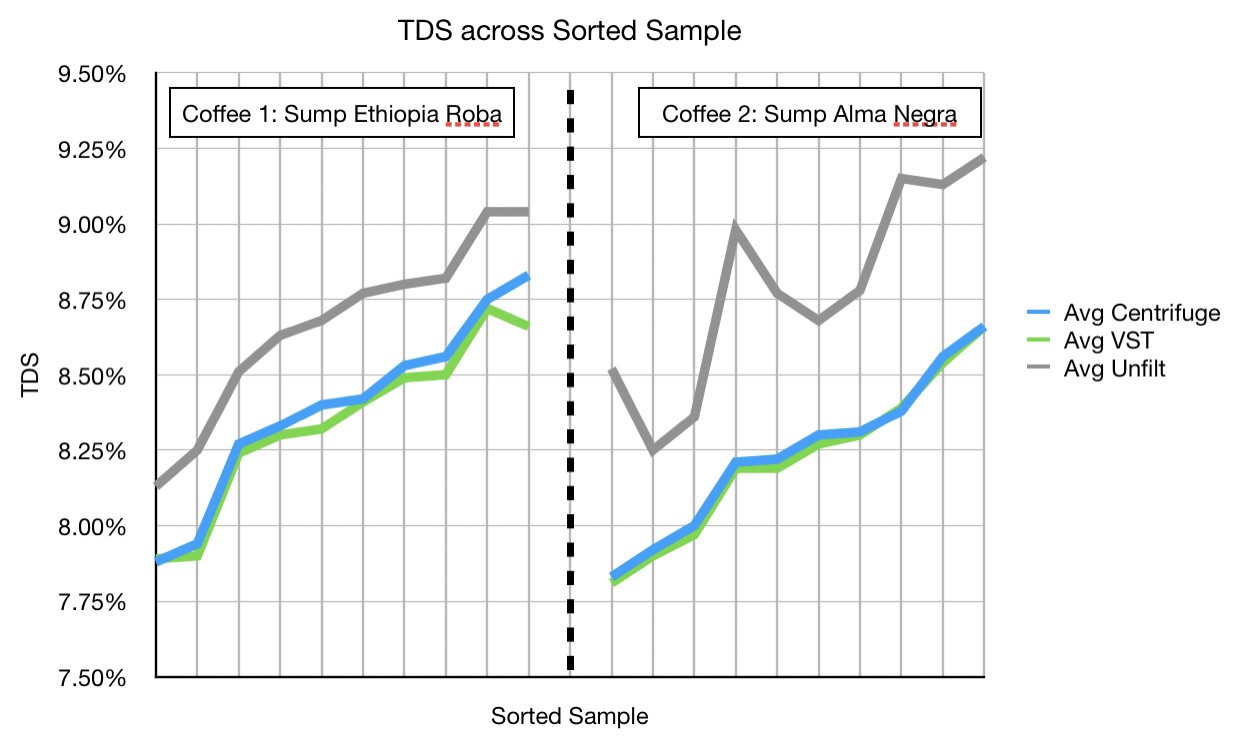
Again, they trend with each other, so we should calculate correlation. Correlation is a metric to help understand how closely two metrics trend with each other:
同样,它们彼此趋向,因此我们应该计算相关性。 关联是一种度量标准,可帮助您了解两个度量标准之间相互接近的趋势:
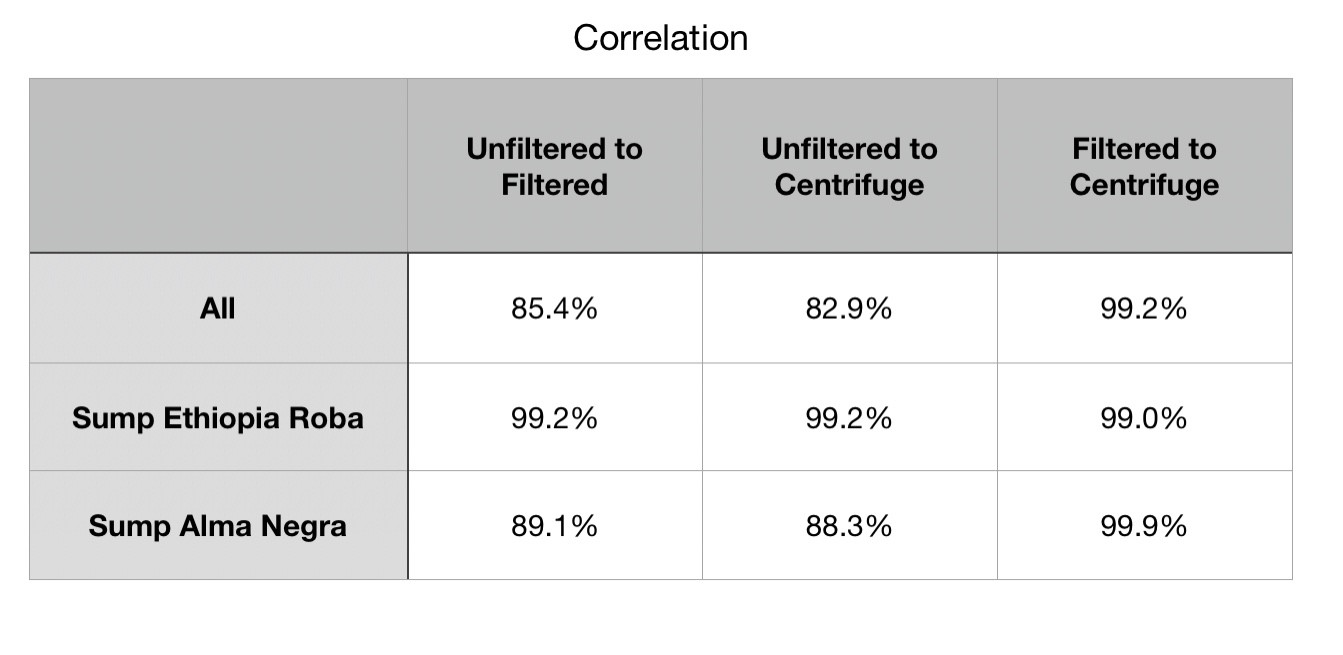
For the Sump Ethiopia Roba, the correlation coefficient is too high to ignore. Even the Sump Alma Negra correlation coefficient in the high 80’s is telling that this link between unfiltered and filtered is just an transformation.
对于坑底埃塞俄比亚Roba,相关系数太高而无法忽略。 甚至在80年代的Sump Alma Negra相关系数也表明,未过滤和已过滤之间的这种联系只是一种转换。
Applying the transformation to each data group, we can compute the percent error (|x — x_GroundTruth|/x_GroundTruth) for the regular measurement and then corrected based on the best fit line transformation.
将变换应用于每个数据组,我们可以计算常规测量的百分比误差(| x — x_GroundTruth | / x_GroundTruth),然后根据最佳拟合线变换进行校正。
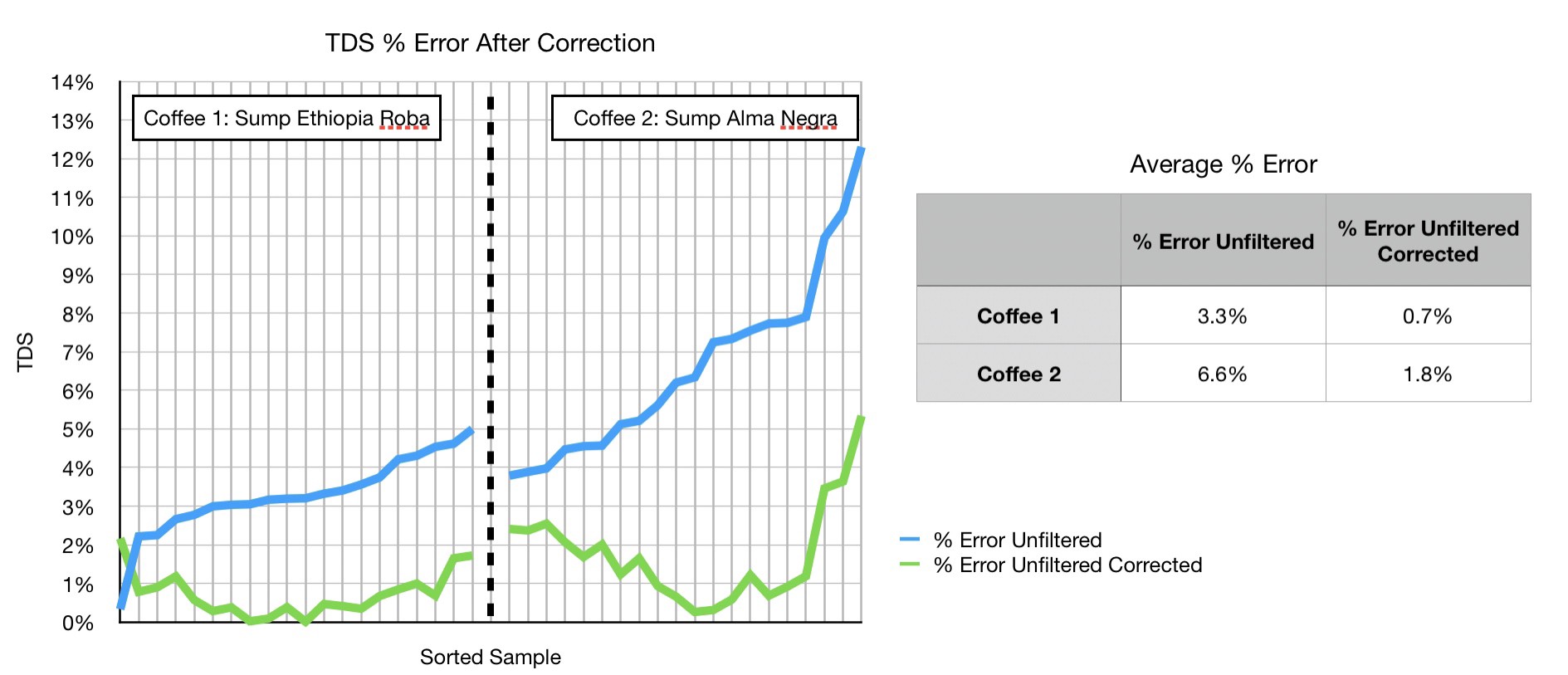
Assuming the centrifuged samples are ground truth, the actual percent error after correction isn’t much to be concerned about.
假设离心后的样品是真实的,校正后的实际百分比误差不大值得关注。
While the author of the study did very well controlling variables and collecting the data, their analysis did not reveal the real findings which is the evidence that filtration of coffee samples for TDS measurement might be unnecessary. The uncertainty is the possibility that every bean has a different correction curve, and if you were quite concerned, a larger study across multiple beans would help confirm this theory.
尽管该研究的作者很好地控制了变量并收集了数据,但他们的分析并未揭示真实的发现,这证明可能不需要过滤咖啡样品以进行TDS测量。 不确定性是每个豆都有不同的校正曲线的可能性,如果您非常担心,则对多个豆进行更大的研究将有助于确认该理论。
If you like, follow me on Twitter and YouTube where I post videos of espresso shots on different machines and espresso related stuff. You can also find me on LinkedIn.
如果您愿意,请在Twitter和YouTube上关注我,在这里我会在不同的机器上发布浓缩咖啡的视频以及与浓缩咖啡相关的内容。 您也可以在LinkedIn上找到我。
我的进一步阅读: (Further readings of mine:)
Coffee Bean Degassing
咖啡豆脱气
Deconstructed Coffee: Split Roasting, Grinding, and Layering for Better Espresso
解构后的咖啡:焙炒,研磨和分层,以获得更浓的意式浓缩咖啡
Pre-infusion for Espresso: Visual Cues for Better Espresso
特浓咖啡的预输注:视觉提示可提供更好的特浓咖啡
The Shape of Coffee
咖啡的形状
To Stir or To Swirl: Better Espresso Experience
搅拌或旋流:更好的意式浓缩咖啡体验
Spicy Espresso: Grind Hot, Tamp Cold for Better Coffee
香浓意式特浓咖啡:磨碎热,捣碎冷可制得更好的咖啡
Staccato Espresso: Leveling Up Espresso
Staccato意式浓缩咖啡:升级意式浓缩咖啡
Improving Espresso with Paper Filters
使用滤纸器改善意式浓缩咖啡
Coffee Solubility in Espresso: An Initial Study
浓咖啡中的咖啡溶解度:初步研究
Staccato Tamping: Improving Espresso without a Sifter
Staccato捣固:无需筛分器即可提高浓咖啡
Espresso Simulation: First Steps in Computer Models
浓缩咖啡模拟:计算机模型的第一步
Pressure Pulsing for Better Espresso
压力脉冲使咖啡更浓
Coffee Data Sheet
咖啡数据表
The Tale of the Stolen Espresso Machine
被盗咖啡机的故事
Espresso filter analysis
浓缩咖啡过滤器分析
Portable Espresso: A Guide
便携式意式浓缩咖啡:指南
翻译自: https://towardsdatascience.com/filter-syringes-for-tds-coffee-measurements-seem-to-be-unnecessary-e52aded77ac4
tds测量电路图
相关文章:
这篇关于tds测量电路图_用于tds咖啡测量的过滤注射器似乎是不必要的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





