本文主要是介绍使用mpiP工具分析AMG程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习使用mpiP工具
- mpiP工具使用方法
- AMG编译和运行过程
- mpiP对AMG的分析结果
- 分析结果的简单分析和理解
- 小结
mpiP工具使用方法
下载mpiP并查看其UserGuide。得知mpiP需要依赖几个库:
- libunwind : 用来收集调用栈信息
- binutils : 用来解析程序地址到源代码行的信息
安装好依赖库后,相应配置mpiP的安装选项(依赖库路径,编译器,编译选项等),再按照提示安装即可。
mpiP生成一个动态库libmpiP.so,使用起来比较简单,不需要用它来重编程序。但为了得到正确的源文件和行号信息,最好用-g选项重编一下。两种使用方式
- 将mpiP库与可执行文件链接起来。如果链接命令包含MPI库,要将mpiP库排序到MPI库之前,如
-l mpiP -lmpi - 在运行时设置
LD_PRELOAD环境变量来加载mpiP库
mpiP提供一系列运行时选项给用户,通过打开它们来采集对应的信息。主要用到的一些列举如下:
| 选项 | 作用 |
|---|---|
| -k n | 设置调用栈回溯的深度(默认1) |
| -o | 在初始化时关掉profiling,在希望profiling的特定代码段通过MPI_Pcontrol()打开 |
| -p | 报告包含点对点通信的消息大小、通信子 |
| -y | 报告包含集合通信的消息大小、通信子 |
这些选项通过环境变量MPIP的设置来生效,如:export MPIP="-t 10.0 -k 2" (bash)。
AMG编译和运行过程
选择候选程序中的AMG(https://github.com/LLNL/AMG)进行测试。clone下来之后,按照README进行编译。注意几个编译选项,开启了-DHYPRE_USING_PERSISTENT_COMM来使用MPI的重复非阻塞通信来提高性能,开启了-DHYPRE_HOPSCOTCH来提高OpenMP的优化。它还提供-DHYPRE_PROFILE来做一些很简单的计时(具体的记时项见seq_mv/HYPRE_seq_mv.h文件里的HYPRE_TimerID枚举类型,还需要自己手动在测试程序的最后写出文件),但这里没有用。
编译需要修改Makefile.include中的INCLUDE_CFLAGS,加上-g选项;同时修改INCLUDE_LFLAGS,加上-lmpip选项。
编译过程:依次进入子目录utilities,krylov,IJ_mv,parcsr_ls,parcsr_mv,seq_mv,编译各个源文件,并生成一个对应的静态库*.a,最后进入test目录编译和链接测试程序。过程如图所示:

在docs/amg.README中可知,测试程序提供两个问题的求解,和参数的设置方式,我们就只运行第一个就好了。在单节点内开128进程,每个进程计算120x120x120的网格数据,进程排布方式为4x4x8。
salloc -N 1 --exclusive --ntasks-per-node 128 mpirun --map-by slot:PE=1 --bind-to core amg -problem 1 -P 4 4 8 -n 120 120 120 -printallstats
运行过程如下所示(从左到右):
 | 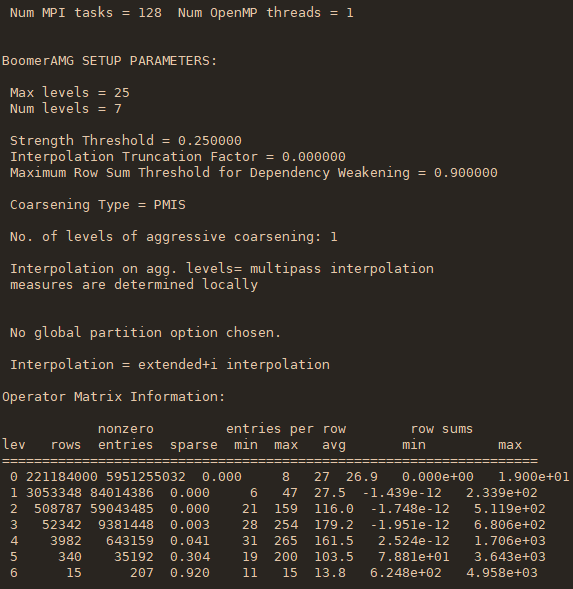 | 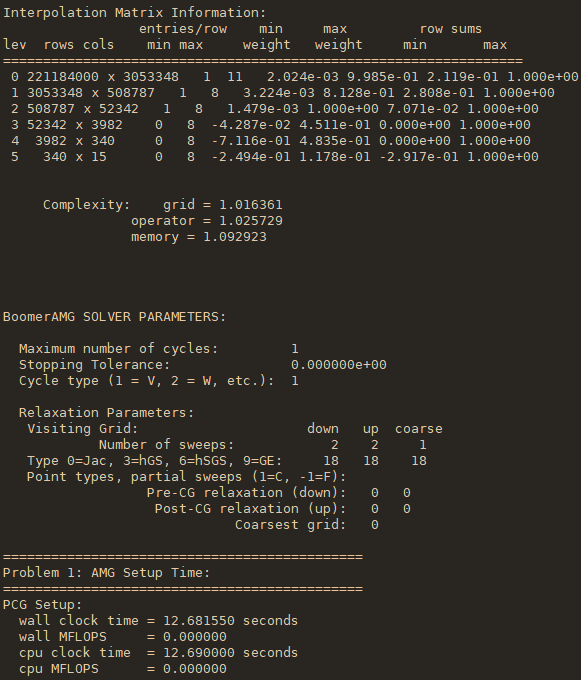 | 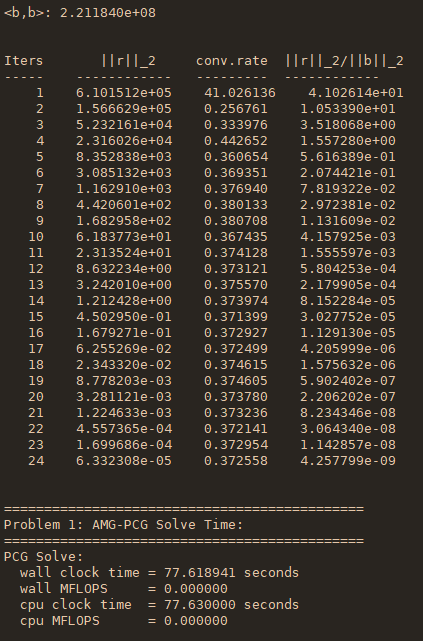 |
简单来说,这个程序包括问题的建立(Laplace方程离散后得到的27点网格的矩阵)、问题的求解(使用代数多重网格作为预条件子的共轭梯度算法)。其中代数多重网格(AMG)需要一个setup的过程。在上面的程序输出中,也简单地做了计时。
上面左起第一个图展示了稀疏矩阵A和右端向量的建立过程和耗时,第二个图展示了自动生成的代数多重网格的结构信息(每一层的算子复杂度和稀疏度等),第三个图展示了层-层之间的插值矩阵的信息和整个setup过程的耗时,第四个图展示了共轭梯度法的迭代过程的每一迭代步的残差和求解过程的耗时。
mpiP对AMG的分析结果
设置环境变量MPIP="-k5,-e,-y,-p",程序结束运行时输出一个mpiP的记录文件。
打开可以看到几部分。首先是记录了程序运行的信息,每个MPI进程的分布:

第二部分记录了每个进程花在MPI相关的函数上的时间,占总的时间比例:

可以看到通信负载并不是很均衡,最小通信耗时的进程只是最大的一半左右。
第三部分展示了各个MPI相关函数调用的信息,每一个ID对应一个位置的调用(同样的MPI函数出现在不同地方的调用,有不同的ID,如下图的Waitall),这里设置了调用栈回溯为5层,所以每个ID重复出现5次,Lev较大的是调用者,同时有每一个函数所在的源文件和行数。

如果程序所使用的进程很多,且通信模式复杂的话,这一部分将会非常庞大。这一次的运行,该部分共有47733条记录。
第四部分记录了总耗时在前20个的MPI函数调用。这里的site就对应上一部分的ID,可以据此判定这一项对应哪个位置的调用。

类似的记录还有发的消息总大小、次数、平均大小。按照消息总大小展示前20名。

由于打开了-y选项,下一部分展示了集合通信的总耗时、通信子大小、数据大小。可见程序中涉及的集合通信只有四个地方。但不知道为什么,这里没有site,不知道怎么去找对应的调用位置。

由于打开了-p选项,下一部分展示了点对点通信的通信子大小、消息大小等,MPI_Sent %似乎表示的是这一个调用占的发送消息的总比例,但也没有显示site。

最后一部分是每个调用位置的统计信息。该部分首先是时间信息,包括了操作时间的最大最小值和平均值,以及该调用位置耗时在它进程的MPI总时间和整个程序时间中的占比(Rank列中的星号代表该调用位置的累加的信息)。这部分的排序是按字母序的,a开头的Allreduce在前。

该部分然后是通信的消息大小的统计。

分析结果的简单分析和理解
mpiP只能简单测量通信特征,从以上结果,大致可以有几点判断:
- 程序中的通信以点对点通信为主
ISend在发送消息的量上占比很高,各个位置的调用次数都很多,且通信消息的大小较大;对应使用的异步接收的Waiall说明是重复的非阻塞通信,且耗时占比很高- 集合通信的类型较少,耗时占比小,消息大小也很小
- 最耗时的点对点通信(即程序中的update halo操作),消息大小都在5.5 KB左右
- 通信负载很不均衡,MPI时间的min/max只有50%左右
- 程序的通信热点所在的路径包含了函数
hypre_ParCSRMatrixMatvecOutOfPlace,因为在调用位置的栈回溯中大量出现该函数(但仅通过通信特征来明确程序热点似乎有点不足,虽然它确实就是程序最耗时的部分)
小结
综合来看,要对一个程序进行性能分析,包括全面的计算、访存和通信,得需要多种的分析工具。光靠一种有点难以全面评估。而mpiP给出的信息只能覆盖通信特征,且缺乏直观,尤其在大规模进程数时,得到的callsite statistics非常庞大,需要用户自己通过site ID去找最耗时的通信调用对应在哪个地方。虽然通过mpiP的MPI_Pcontrol()可以实现任意具体代码段的分析,能减小输出的文件的规模,便于针对性的分析,但这就需要用户对程序代码本身有理解了才能在代码里添加MPI_Pcontrol()的控制。而且配合MPI_Pcontrol()启用-o选项后,不知道为什么,输出的文件里就没有具体通信调用处的通信子大小、消息大小等信息了。
这篇关于使用mpiP工具分析AMG程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




