本文主要是介绍分型+预后模型多层面验证,干湿结合直达7+,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天给同学们分享一篇铜死亡+分型+预后模型+实验的生信文章“Construction and validation of a cuproptosis-related prognostic model for glioblastoma”,这篇文章于2023年2月6日发表在Front Immunol期刊上,影响因子为7.3。
铜死亡是一种新报道的程序性细胞死亡类型,参与调控肿瘤进展、治疗反应和预后。但铜死亡相关基因(CRGs)对于胶质母细胞瘤(GBM)的具体影响仍不清楚。
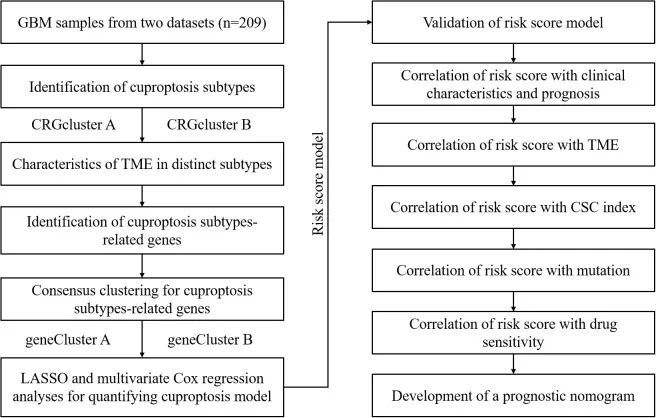
图1 研究的整个分析过程
1. 肿瘤和正常组织之间的CRG差异表达
在这项研究中,总共包括了12个CRGs。作者对正常和GBM样本之间的CRGs进行了差异表达分析,发现在GBM样本中有10个CRGs显著上调表达,包括SLC31A1、CDKN2A、MTF1、LIPT1、FDX1、PDHB、PDHA1、LIAS、DLD和DLAT。相反,有2个CRGs显著下调表达,包括ATP7B和GLS(图2A)。

图2 GBM中12个CRG的转录和遗传改变
接下来,对12个CRG的体细胞突变进行了分析,发现GBM样本中的突变频率较低。在461个GBM样本中,CRG中有16个(3.47%)突变。其中,五个CRG(CDKN2A、MTF1、ATP7B、DLD和GLS)的突变频率分别为1%,而另外三个CRG(FDX1、LIAS和LIPT1)没有突变(图2B)。此外,作者还分析了12个CRG的拷贝数变异(CNV),发现只有2个CRG中频繁出现了CNV。CDKN2A和ATP7B显示出明显的CNV减少(图2D)。图2C显示了12个CNV在各自染色体上的位置。具有CNV丧失的CRG,如ATP7B,在GBM样本中的表达水平低于正常样本,而具有CNV丧失的另一个CRG,CDKN2A,在GBM样本中显著升高。此外,其他显著差异表达的CRG的CNV频率非常低。
2. 鉴定GBM中的铜死亡亚型
总共合并了来自两个GBM队列(TCGA-GBM和GSE83300队列)的209名患者。获得了209个GBM样本的详细信息。通过Kaplan-Meier生存分析和单变量Cox回归分析确定了12个CRGs的预后意义。其中包括ATP7B、CDKN2A、DLD、MTF1和SLC31A1等五个CRGs被确定为预后CRGs。如图3A所示,一个铜死亡网络系统地揭示了GBM中CRGs的相互作用和预后意义。
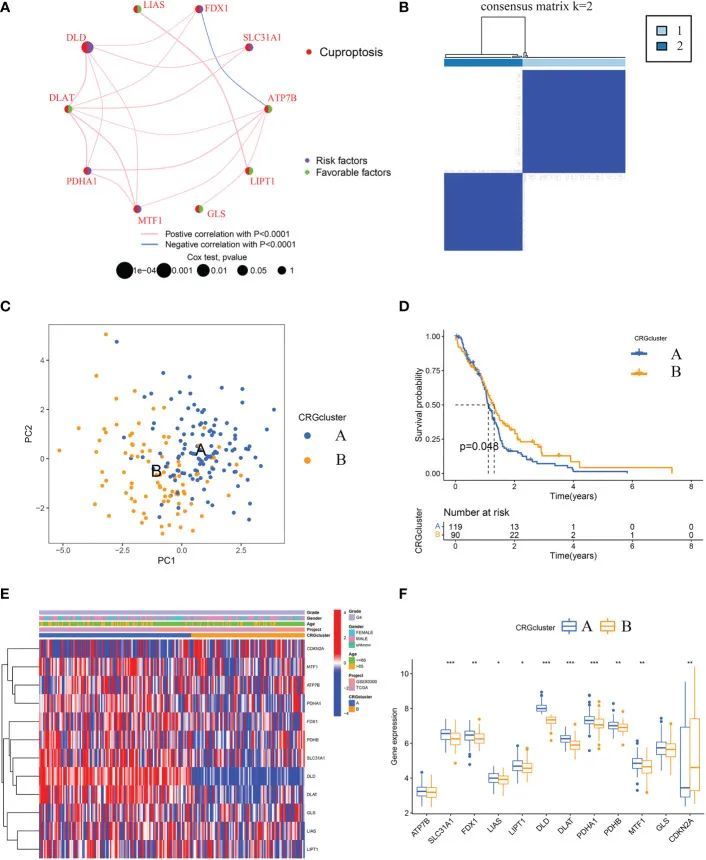
图3 鉴定铜死亡亚型并比较两个亚型之间的临床特征和CRGs表达水平
根据五个预后相关基因的表达谱,使用共识聚类算法对GBM样本进行分类。共识矩阵热图显示k = 2是最佳分类方法,GBM样本被分为CRGcluster A(样本数= 119)和CRGcluster B(样本数= 90)(图3B)。主成分分析显示两个亚型的铜死亡转录谱不同(图3C)。此外,Kaplan-Meier曲线显示CRGcluster B中的GBM样本的生存期较CRGcluster A中的样本更长(卡方检验,P = 0.048;图3D)。通过比较两个亚型的临床特征,未观察到年龄和性别方面的明显差异(图3E)。然而,CRGcluster A中大多数CRG的表达水平高于CRGcluster B(图3E,F)。
3. 不同的铜死亡亚型的TME特征
首先,基于ssGSEA算法,作者获得了每个GBM样本中23种免疫细胞的相对含量。而某些免疫细胞的相对含量,包括MDSCs、CD56自然杀伤细胞、巨噬细胞、嗜酸性粒细胞、2型T辅助细胞、肥大细胞、单核细胞和CD56自然杀伤细胞,在两个亚型之间存在显著差异(图4A)。至于免疫检查点,CRGcluster B中PD-L1的表达水平低于CRGcluster A,而CTLA4和PD-1的表达水平高于CRGcluster A(图4B)。此外,使用ESTIMATE算法,作者获得了每个GBM样本的TME得分,包括免疫得分、基质得分和ESTIMATE得分。免疫得分代表免疫成分的含量,基质得分代表基质成分的含量,而ESTIMATE得分是两者之和。差异分析显示,CRGcluster B中的TME得分略高,但没有显著差异(图4C)。

图4 肿瘤微环境与两种铜死亡亚型的相关性
4. 肿瘤微环境与两种铜死亡亚型的相关性
使用R软件包“limma”,作者鉴定出360个与铜热性细胞死亡亚型相关的差异表达基因(DEGs)。通过单变量Cox回归分析,作者确定了79个预后相关的DEGs。此外,根据这79个预后相关DEGs的表达谱,作者使用共识聚类算法对GBM样本进行了分类。共识矩阵热图显示k = 2是最佳的分类方法,GBM样本被分为基因亚型A(样本数=96)和基因亚型B(样本数=113)(图5A)。Kaplan-Meier曲线显示,基因亚型B中的GBM样本的总生存期比基因亚型A中的样本更长(卡方检验,P = 0.018;图5B)。通过比较两个亚型的临床特征,作者发现年龄和性别没有明显差异。然而,基因亚型A中大多数预后相关DEGs的表达水平高于基因亚型B(图5C)。图5D显示了基因亚型A和基因亚型B之间12个CRGs的差异表达分析结果。
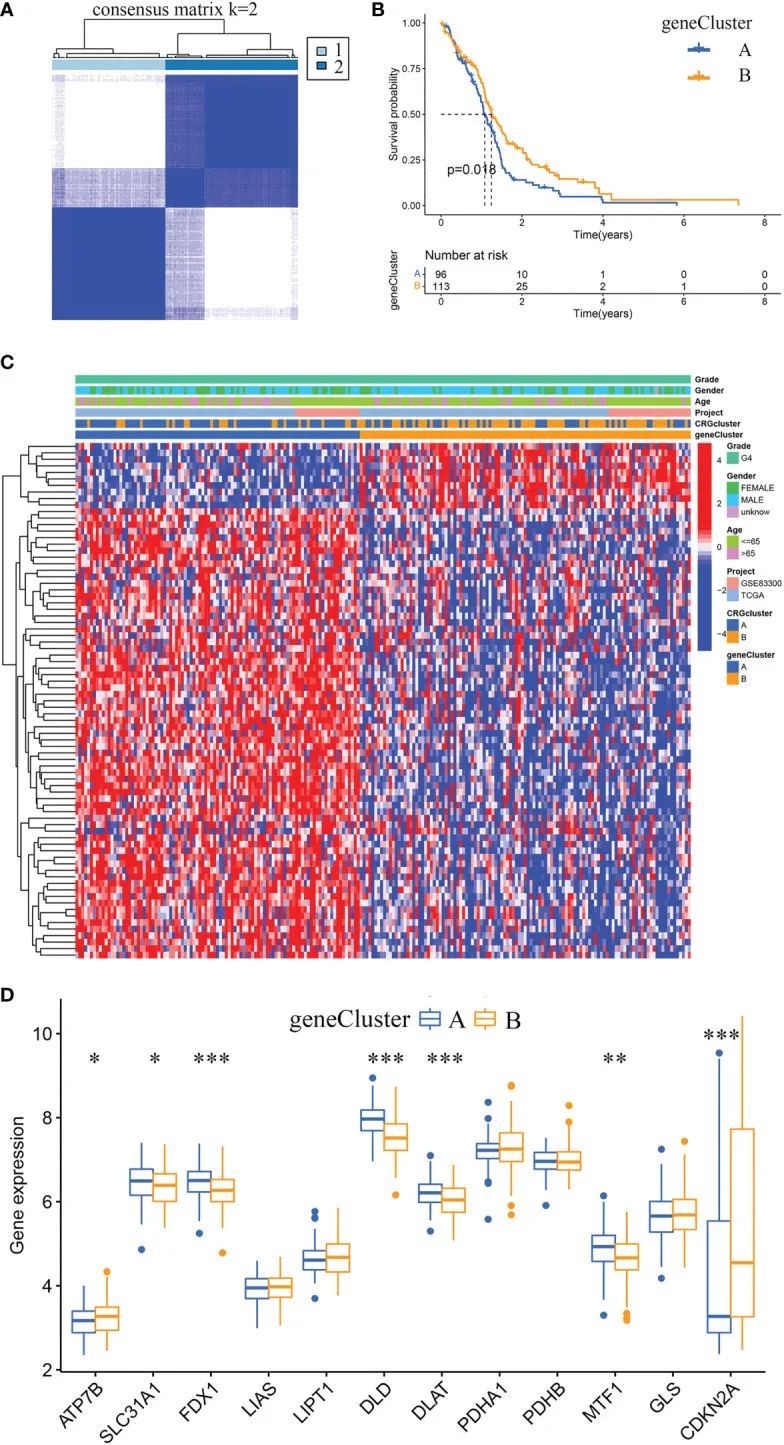
图5 基因亚型的鉴定以及两个基因亚型之间的临床特征和CRGs表达水平的比较
5. 建立并验证了一个风险评分模型
根据铜死亡亚型相关的差异表达基因(DEGs),作者建立了一个预后风险评分模型。图6A展示了不同分类方法下GBM样本的分布情况。首先,将GBM患者随机分为训练集和测试集。两个集合的样本量大致相同,训练集中有105个GBM样本,测试集中有104个GBM样本。其次,作者对这79个预后DEGs进行LASSO回归分析,得到了七个候选基因用于风险评分模型(图6B、C),然后对这七个候选基因进行多变量Cox分析,最终得到了五个目标基因(PDIA4、PILRB、DUSP6、CBLN1和PTPRN),其中包括四个高风险基因(PDIA4、PILRB、DUSP6和PTPRN)和一个低风险基因(CBLN1)。

图6 在训练集中构建了一个风险评分模型
差异分析表明,geneCluster A和CRGcluster A的风险得分高于geneCluster B和CRGcluster B(图6D、E)。在训练集中,根据中位数,GBM样本被分为低风险亚型(n = 53)和高风险亚型(n = 52)。随着风险得分的增加,GBM患者的生存期逐渐减少,死亡率稳步增加(图6F)。PCA清晰地区分了这两个风险亚型(图6G)。生存曲线显示,低风险亚型中的GBM样本的生存期比高风险组更长(卡方检验,p < 0.001;图6H)。此外,基于该模型的0.5年、1.0年和1.5年的AUC值分别为0.643、0.709和0.751(图6I)。
接下来,该模型在测试集GSE83300队列和GSE74187队列中进行了验证(图7)。根据中位风险评分,分别对测试集、GSE83300队列和GSE74187队列中的GBM样本进行分类。随着风险评分的增加,GBM患者的生存期逐渐缩短,死亡率稳步增加(图7A、E、I)。主成分分析清晰地区分了两个风险亚型(图7B、F、J)。在测试集中,Kaplan-Meier曲线显示低风险亚型的GBM患者生存期较高风险组更长(卡方检验,p = 0.018;图7C)。在GSE83300队列中,尽管生存分析的结果没有达到统计学意义,但低风险亚型的GBM样本倾向于延长生存期(卡方检验,p = 0.121;图7G)。在GSE74187队列中,Kaplan-Meier曲线显示低风险亚型的GBM患者生存期较高风险组更长(卡方检验,p = 0.007;图7K)。在测试集中,基于该模型的0.5年、1.0年和1.5年生存率的AUC值分别为0.610、0.671和0.708(图7D)。在GSE83300队列中,基于该模型的0.5年、1.0年和1.5年生存率的AUC值分别为...基于该模型,0年、1.5年的生存率分别为0.676、0.731和0.718(图7H)。在GSE74187队列中,基于该模型的0年、1.0年和1.5年生存率的AUC值分别为0.619、0.731和0.741(图7l)。
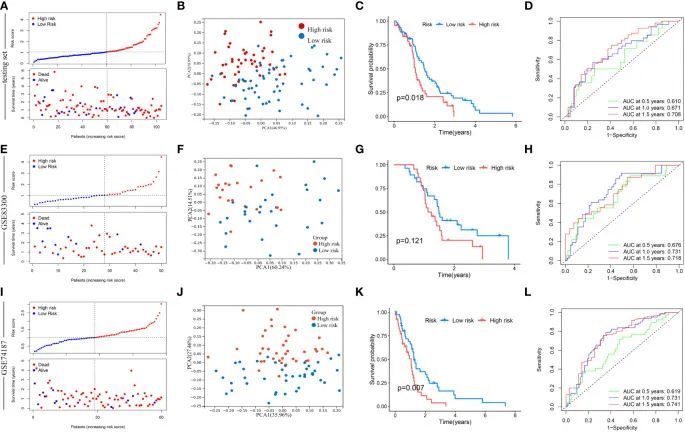
图7 在测试集、GSE83300队列和GSE74187队列中验证风险评分。
6. 验证了与模型相关的五个基因的表达
使用RT-qPCR检测了五对胶质母细胞瘤(GBM)和相邻组织中五个与模型相关基因的mRNA表达水平。与相邻标本相比,PDIA4、DUSP6和PTPRN的表达水平上调,而PILRB和CBLN1的表达水平在GBM标本中下调(图8A-E)。为了验证五个与模型相关基因的蛋白质表达水平,进行了WB检测。一致地,与相邻标本相比,PDIA4、DUSP6和PTPRN的蛋白质表达水平上调,而PILRB和CBLN1的蛋白质表达水平在GBM标本中下调(图8F,G)。
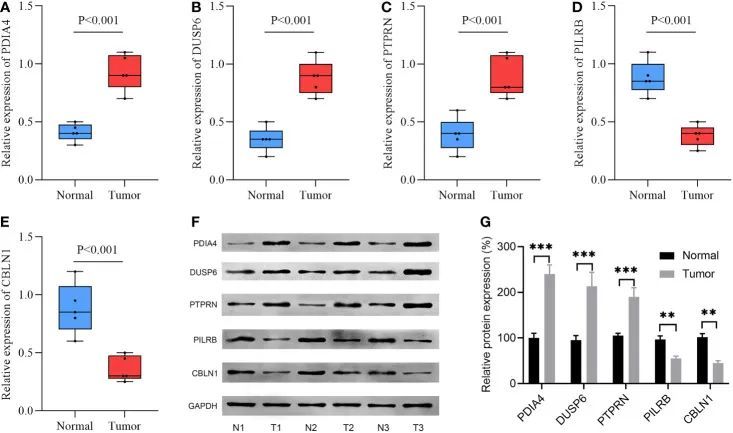
图8 通过RT-qPCR和WB验证了GBM组织和相应正常组织中5个与模型相关基因的表达水平
7. 预后风险评分的临床相关性分析
IDH1突变群中的风险评分低于IDH1野生型群(P < 0.0001;图9A)。单变量和多变量回归分析结果显示,预后风险评分和IDH1突变状态均为独立的预后因素(图9B、C)。此外,进行分层分析以评估该模型的广泛适用性。Kaplan-Meier曲线显示,低风险群的GBM总是比高风险群具有更长的生存期,在年龄小于60岁的亚群中p < 0.001,在年龄大于60岁的亚群中p = 0.005,在男性亚群中p < 0.001,在女性亚群中p = 0.015,在IDH1突变亚群中p < 0.001,在IDH1野生型亚群中p = 0.003(图9D-I)。
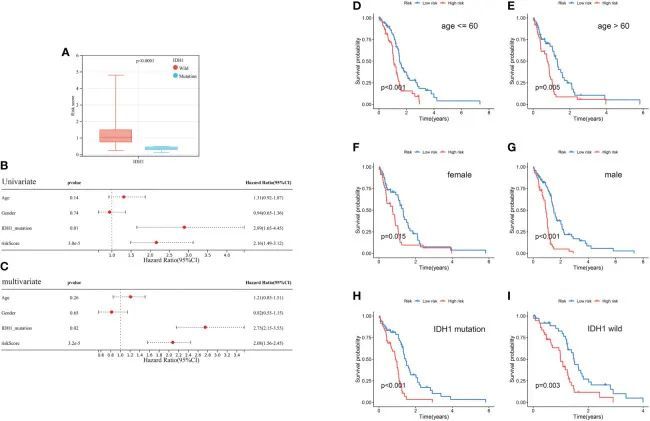
图9 预后风险评分的临床相关分析和分层分析
8. TME和两个风险评分组之间的检查点评估
风险评分与免疫细胞含量之间的相关分析结果表明,在调节性T细胞、滤泡辅助T细胞、中性粒细胞、静息NK细胞和M0巨噬细胞方面存在正相关,而在嗜酸性粒细胞、M2巨噬细胞、单核细胞和活化NK细胞方面存在负相关(图10A)。此外,免疫细胞含量与5个模型相关基因的表达水平之间的相关分析显示,某些类型的免疫细胞与特定基因之间存在明显的相关性(图10B)。此外,低风险亚型中的GBM样本的基质得分和ESTIMATE得分明显低于高风险组的样本(图10C)。最后,对高风险亚型和低风险亚型之间的免疫检查点进行了差异表达分析。结果显示,低风险亚型中15个免疫检查点的表达水平低于高风险亚型,例如PD-1和PD-L1(图10D)。
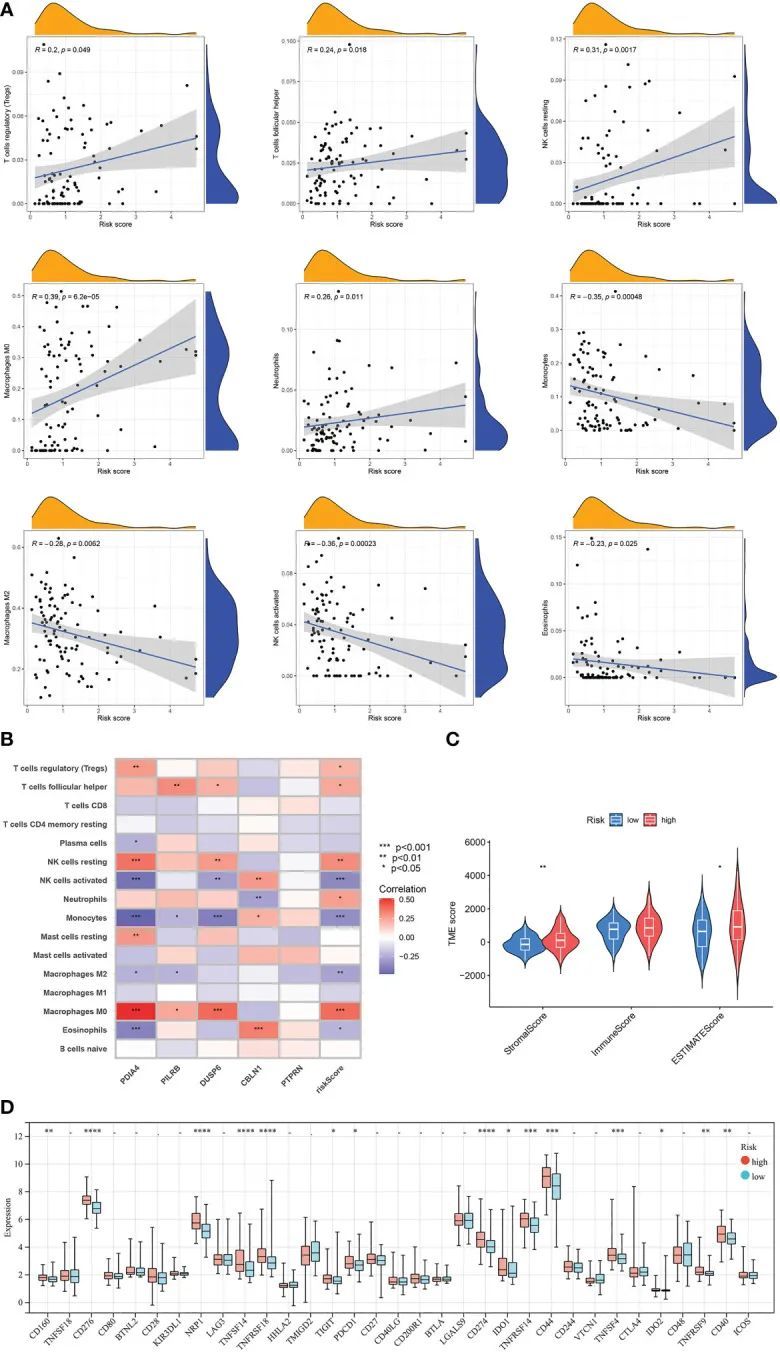
图10 TME和两个风险评分组之间的评估
9. 评估风险评分与CSC指数、TMB和药物敏感性的关联
CSC指数与风险评分之间的相关分析结果表明它们呈负相关(R = -0.35,P = 6.5e-06);也就是说,低风险评分的GBM患者的干细胞特征更为显著(图11A)。一般认为,具有高TMB的肿瘤对免疫治疗的反应更好,因此预后更佳。根据TCGA GBM队列的突变数据,差异分析显示高风险亚型的TMB低于低风险组(图11B)。接下来,TMB与风险评分之间的相关分析结果表明它们呈负相关(R = -0.048,p = 0.049;图11C)。有趣的是,在低风险组中没有显著相关性(R = 0.044,p = 0.12;图11D),而在高风险组中呈负相关(R = -0.012,p = 0.04;图11E)。为了确定体细胞突变的具体分布,作者构建了两个风险评分组的瀑布图,并且高风险亚型中最常见的十个突变基因是PTEN、EGFR、TP53、TTN、NF1、MUC16、PIK3CA、LRP2、RYR2和SPTA1(图11F),而低风险亚型中最常见的十个突变基因是TP53、PTEN、TTN、EGFR、MUC16、ATRX、SPTA1、FLG、IDH1和RYR2(图11G)。低风险亚型中PTEN、EGFR和NF1的突变频率低于高风险亚型,而低风险亚型中ATRX、IDH1、TP53、MUC16和PIK3R1的突变频率高于高风险亚型(图11F,G)。此外,选择常见的药物或化合物来检测药物敏感性与风险评分之间的关联。两个风险亚型之间IC50值的差异分析结果表明,高风险亚型中bryostatin、midostaurin、mirdametinib、ponatinib和tipifarnib的IC50值低于低风险亚型。相比之下,高风险亚型中afatinib和elesclomol的IC50值高于低风险亚型。结果表明,药物敏感性与风险评分有一定的关联(图11H-N)。
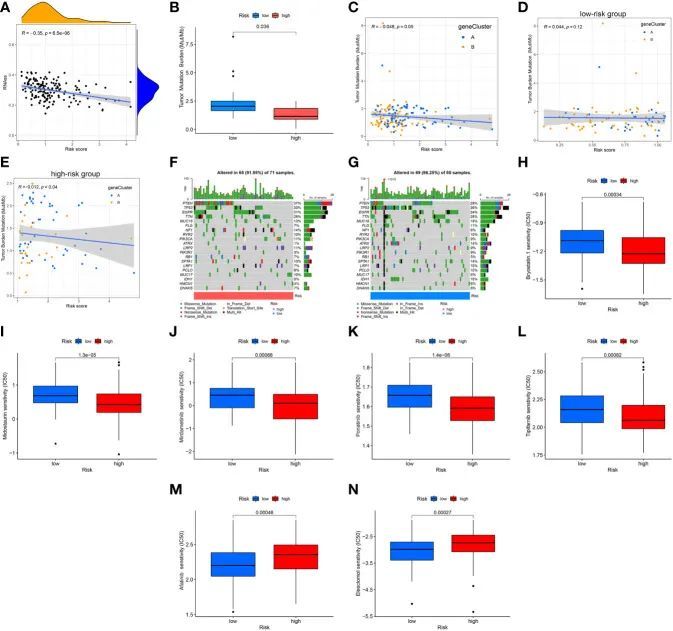
图11 风险评分与CSC指数、TMB和药物敏感性的关联分析
10. 构建了一个预测生存率的诺莫图
为了提高该模型在临床中的适用性,作者开发了一个包含临床参数(年龄、性别和IDH1突变状态)和风险评分的图表(图12A)。根据这个图表,在训练集中,用于预测总生存期(OS)的0.5年、1.0年和1.5年的ROC曲线下面积(AUC)值分别为0.716、0.727和0.763(图12B),在测试集中分别为0.741、0.775和0.734(图12C)。此外,校准曲线显示预测结果与理想结果非常接近(图12D、E)。接下来,作者检测了仅基于IDH1突变状态的预测性能。根据仅基于IDH1突变状态的预测,用于预测OS的0.5年、1.0年和1.5年的ROC曲线下面积(AUC)值分别为0.663、0.609和0.607(图12F),在测试集中分别为0.679、0.693和0.686(图12G)。结果表明,该图表具有出色的预测性能,比仅基于IDH1突变状态的预测更好。
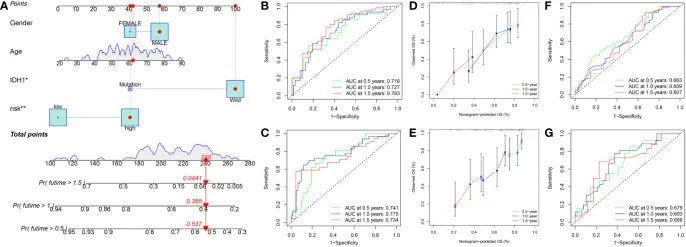
图12 在训练集中构建了一个刻度图
总结
在这项研究中,通过分析从数据库下载的GBM的表达谱和临床数据,基于CRGs构建并验证了一个风险评分模型。进一步开发了一个图表,以提高其适用性。作者还研究了分类与TME之间的关系,以及在免疫治疗或化疗中的指导意义。这项研究为GBM的预后预测和精确治疗提供了新的思路。
这篇关于分型+预后模型多层面验证,干湿结合直达7+的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





