本文主要是介绍2022高校大数据挑战赛高质量思路保奖资料,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
首先来分析 A 题,工业机械设备故障预测
B 题 图像信息隐藏
首先是选题方面
A 题是工业设备的故障检测问题,本质上属于分类问题
B 题是图像的隐藏问题,本质上属于图像特征提取与评价问题
难度上来说,A 的难度系数相对小一些,这是因为 B 题需要有一定的图像处理 的知识,如算子、灰度矩阵等,但即使不知道这些信息也并不影响做题
首先来分析 A 题,工业机械设备故障预测
目前A题更新高质量全部问题的代码+第二版全部问题思路

任务 1:观察数据“train data.xlsx”,自主进行数据预处理,选择合适的指标用于机械设备故障的预测并说明原因。
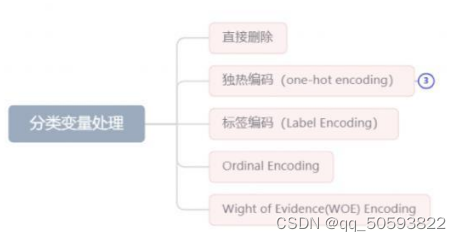
任务一主要是考察数据预处理的能力,其中原始数据所包括的指标比较多,有分 类指标(机器质量等级)并且指标的量纲也不一样,因此需要先进行数据的预处理工作,在这里给大家说一下:
需要对分类变量进行处理,使之转换为数值型变量。常见的分类变量处理方法 如下:
另外对于量纲不一致的指标一般进行标准化处理(归一化处理等) 标准化,又称规范化,目的是将原来的度量值转换为无量纲的值,使得不同量纲 的指标可以在同一水平线上进行比较,而且除了概率模型(树模型)之外,其
https://kdocs.cn/l/ctQsfOssQ0vD(打开链接,获取

B 题 图像信息隐藏
问题 1:图像信息隐藏算法的图像质量评价指标很多,其中影响视觉效果的指标具有不可见性,可用来衡量嵌入水印的图像与原始图像之间的差异性。现请 你根据附件 1 中的数据,使用多种图像质量评价指标说明原始图像与嵌入水印之后图像之间的差别,并使用合适的统计方法说明差别图像之间至少 3 种共同的特征。
首先针对问题一,主要是选择图像质量的评价指标有哪些,一般图像质量评估主要包括主观评估和客观评估两种,其中主观评估意义不大在这里不做说明,客观 评估的话主要分为全参考评估、半参考评估和无参考评估等;一般我们常见的就是全参考评估

https://kdocs.cn/l/ctQsfOssQ0vD(打开链接,获取
1 PSNR 即峰值信噪比(Peak Signal to Noise Ratio)
借助均方误差来计算图像失真情况,PSNR 值越大代表失真图像与参考图像 越接近,即画质越好。其计算公式大家一定不陌生:
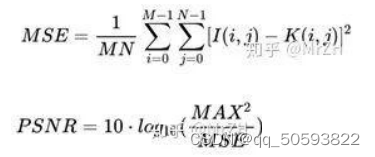
其中 I 和 K 代表参考图像与失真图像,均为 MxN 的图片(这里仅给出了一个通道的情况,对于 RGB 格式的图像需对三个通道均进行相应计算后取平 均值);MSE 为均方误差(Mean Square Error),代表了两张图片逐像素差异比较的结果;MAX 为像素可线束的颜色数目数(以像素采用 8bit 为例, 该情况下 MAX=2^8-1=255)。
PSNR 是最常见的指标之一,其他的还包括:
2 结 构 相 似 度 SSIM ( Structural Similarity Index )论 文链 接: https://www.cns.nyu.edu/pub/lcv/wang03-preprint.pdf
3 多尺度结构相似度(Multi Scale Structural Similarity Index,MS-SSIM) 论文链接: https://ece.uwaterloo.ca/~z70wang/publications/msssim.pdf
4 基于信息量加权的结构相似度方案 IW-SSIM(Evaluation of Information Content-Weighted SSIM) 论文链接: https://sse.tongji.edu.cn/linzhang/iqa/evalution_iw
这篇关于2022高校大数据挑战赛高质量思路保奖资料的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




