本文主要是介绍DGL的图数据结构的创建、图的特征、dgl.batch及一些理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
dgl是图神经网络构建的工具。官方文档:https://docs.dgl.ai/guide_cn/graph-basic.html#guide-cn-graph-basic有中文的文档,很贴心。
一、创建图
1.dgl.graph((u, v))
我只说一下我目前用过的方式,还有许多方式可以看官方文档。
import torch as th
import dgl
u, v = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
g = dgl.graph((u, v))
print(g)
输出:

图已经创建完成了,相信你第一眼肯定会觉得很抽象,这图是什么样子呢?
我们可以可视化一下:(我这里用的是jupyter文件格式.ipynb
import networkx as nx
%matplotlib inline
nx_G = g.to_networkx()
pos = nx.kamada_kawai_layout(nx_G)
nx.draw(nx_G, pos, with_labels=True, node_color=[[.7, .7, .7]])
输出:
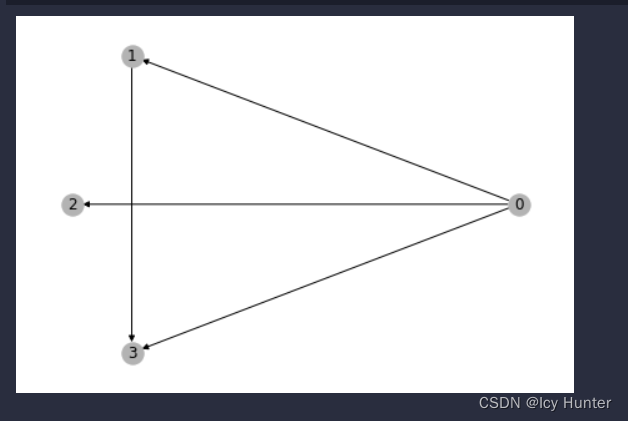
可视化出来应该就很好理解了
u, v = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
u和v都是图的节点,分别是一一对应创建边的关系。因为树就是特殊的图,其实用这个数据结构构建树也十分容易。
2.dgl.graph((tuple)…)
这个方法我感觉还是比较实用的,尤其是创建树结构的时候。
import torch as th
import dgl
u = [0, 0, 0, 1]
v = [1, 2, 3, 3]
u_v = []
for u, v in zip(u, v):u_v.append((u,v))
g = dgl.graph(u_v)
print(g)

结果是一样的。
还有其他一些方法可以参考一下官方文档,或者别人写的这篇博客也蛮好的跟着官方文档学DGL框架第二天——DGLGraph和节点/边特征
二、理解图
还是用刚刚造的那张图。
import torch as th
import dgl
u, v = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
g = dgl.graph((u, v))
1.边和节点的特征赋值与查看
dgl的图中,每个边和节点都能够赋值特征,从而实现图神经网络的计算。
import torch as th
import dgl
u, v = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
g = dgl.graph((u, v))# 每个节点赋值特征
g.ndata['x'] = th.randn(g.num_nodes(), 3) # 长度为3的节点特征
g.ndata['mask'] = th.randn(g.num_nodes(), 3) # 节点可以同时拥有不同方面的特征
g.edata['x'] = th.ones(g.num_edges(), dtype=th.int32) # 每个边赋值特征
print(g)print(g.ndata["x"][0])
print(g.edata["x"][0])
输出:

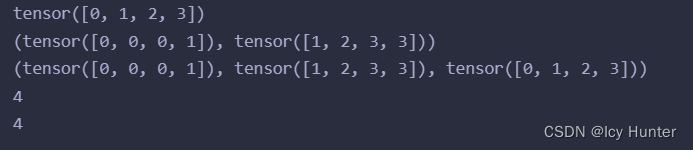
2.图的一些属性或方法
import torch as th
import dgl
u, v = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
g = dgl.graph((u, v))print(g.nodes()) # 获取节点的ID
print(g.edges()) # 获取边的对应端点
print(g.edges(form='all')) # 获取边的对应端点和边ID
print(g.number_of_nodes()) # 获取所有节点的数量
print(g.number_of_edges()) # 获取所有边的数量
3.DGL中的Batch
当我们训练深度学习模型时,都会打包成一个batch去更新模型的参数,图神经网络也不例外。但是当许多子图打包之后,每个子图的节点会重新标号。
举个例子就懂了:
import torch as th
import dgl
u, v = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
u1, v1 = th.tensor([0, 1, 2, 3]), th.tensor([2, 3, 4, 4])
u2, v2 = th.tensor([0, 0, 2, 3]), th.tensor([2, 3, 3, 1])
g = dgl.graph((u, v))
g1 = dgl.graph((u1, v1))
g2 = dgl.graph((u2, v2))
import networkx as nx
%matplotlib inline
然后运行(画第一张图)
nx_G = g.to_networkx()
pos = nx.kamada_kawai_layout(nx_G)
nx.draw(nx_G, pos, with_labels=True, node_color=[[.6, .7, .7]])
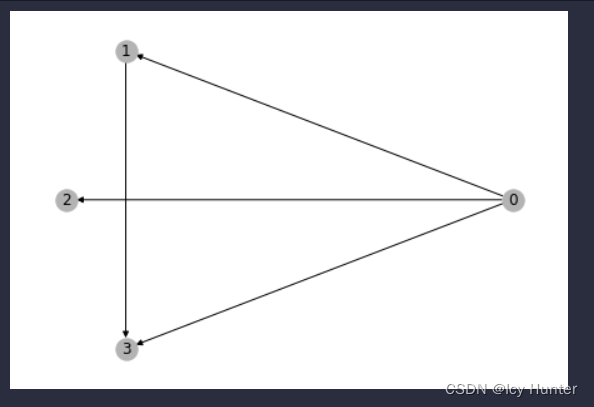
再运行(画第二张图)
nx_G = g1.to_networkx()
pos = nx.kamada_kawai_layout(nx_G)
nx.draw(nx_G, pos, with_labels=True, node_color=[[.6, .7, .7]])
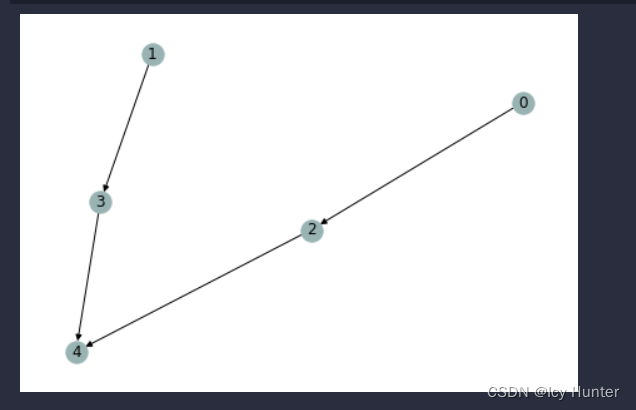
最后运行(画第三章图)
nx_G = g2.to_networkx()
pos = nx.kamada_kawai_layout(nx_G)
nx.draw(nx_G, pos, with_labels=True, node_color=[[.6, .7, .7]])
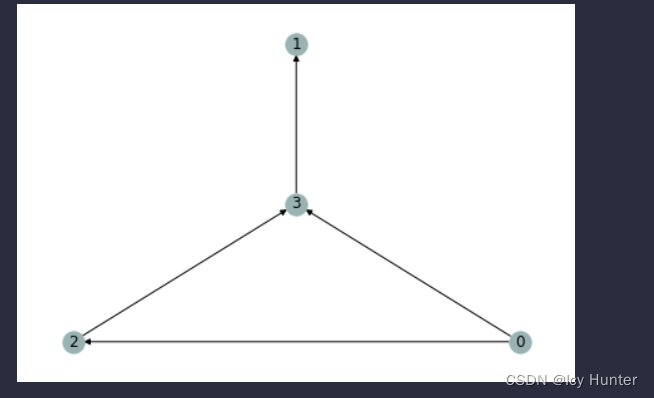
然后我们再将这三个子图,打包成一个Batch然后可视化出来
graphs = [g, g1, g2] # 图的列表
graph = dgl.batch(graphs) # 打包成一个batch的大图nx_G = graph.to_networkx()
pos = nx.kamada_kawai_layout(nx_G)
nx.draw(nx_G, pos, with_labels=True, node_color=[[.6, .7, .7]])
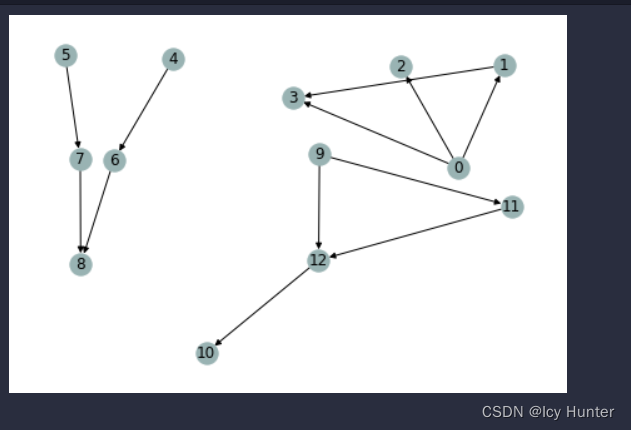
可以发现变成大图之后,子图的节点序号重新标号了。且顺序就是按照图列表的顺序来的。
这篇关于DGL的图数据结构的创建、图的特征、dgl.batch及一些理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







