本文主要是介绍Adversarial Training with Rectified Rejection 笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Adversarial Training with Rectified Rejection 笔记
- Abstract
- 1 Introduction
- 2 Related work
- 3 Classification with a rejection option
- 3.1 True confidence (T-Con) as a certainty oracle
- 4 Learning T-Con via rectifying confidence
- 4.1 Construction of rectified confidence (R-Con)
- 4.2 Certified separability using coupled rejectors
- 4.3 The difficulty of learning A φ ( x ) A_φ(x) Aφ(x)
- 7 Conclusion
Abstract
对抗训练是提高模型鲁棒性的最有效方法之一,目前最先进的对抗训练模型在没有额外数据的情况下对CIFAR-10难以超过60%的鲁棒性测试精度。解决此瓶颈的最自然的方法就是加入一个拒绝选项,其中置信度是一个常用的确定性代理。当输入被错误的分类,一般的置信度可能会高估模型的准确性。本文建议使用真实的置信度(T-Con 即真实类的预测概率)作为一个确定性的准则,并通过学习修正置信度来预测T-Con。并且证实在适宜条件下,一个修正的置信度R-Con拒绝器和一个置信拒绝器可以耦合来区分任何错分类的输入和正确分类的输入,包括自适应攻击情况下。
1 Introduction
通过将拒绝选项或检测模块与对抗训练模型相结合可以实现模型对异常输入的正确预测。然而,尽管之前通过基于边际的目标或置信度校准训练的拒绝器可以捕获预测确定性的某些层面,但他们尤其是在自适应攻击下往往会高估错误分类样本的准确性。此外,目前还不明确学习鲁棒拒绝器是否会遇到与学习鲁棒分类器类似的准确性瓶颈,这可能是由于数不足或泛化不良造成的。
在本文中,将采用T-Con f θ ( x ) [ y ] f_θ(x)[y] fθ(x)[y]即预测可能性分类器 f θ ( x ) f_θ(x) fθ(x)在真实标签y上的预测概率作为一个确定准则。T-Con不同与常用的置信度,在不知道真实标签y的情况下取最大值作为 m a x l f θ ( x ) [ l ] max_lf_θ(x)[l] maxlfθ(x)[l]。如果将T-con的阈值置信度设置为 1 2 \frac 12 21,那么T-con可以完美的区分正确的输入和错误的输入。此外整整的交叉熵损失 − l o g f θ ( x ) [ y ] -log f_θ(x)[y] −logfθ(x)[y]反映了分类器在新的输入x上的泛化程度。
T-Con的性质令人满意,但是由于没有真正的标签y,它的计算推理过程无法实现。于是通过辅助函数来修正T-Con构建修正置信度R-Con从而学习预测T-Con。
本文证实了如果R-Con被训练成在一某个错误程度与T-con对齐(即define 1 的ξ 误差),那么一个ξ 误差拒绝器和一个 1 2 − ξ \frac 1{2−ξ } 2−ξ1误差拒绝器可以耦合将任何错误分类的输入与正确分类的输入分开。在实践中,R-con可以作为单独用作拒绝器,这减轻了对错误分类样本的模型准确性的误判。
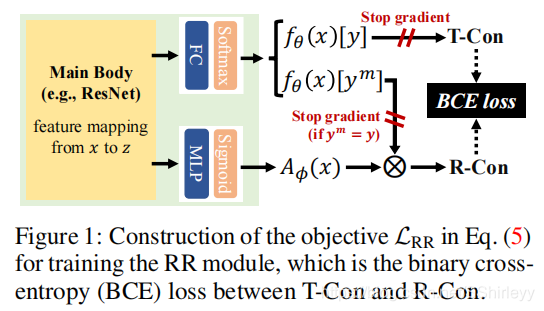
在Figure 1中,采取了双向结构来建立R-Con模型,并通过端到端方式尽量减少T-Con和R-con之间的额外损失,反向训练R-con的分类器和错误拒绝模块。修正拒绝模块(RR)中设计的共享主干网节省了计算和内存成本。当 y m = y y^m=y ym=y时停止梯度下降可以避免关注简单的例子。对R-Con的构建进行了消融研究,结果表明RR模块与不同的AT框架很好的兼容,并且可以始终如一地促进返回地预测,在多种攻击和威胁下实现更高地准确性。
2 Related work
Adversarial training:近年来,对抗性训练成为最最先先进地稳健模型地关键要素。最近地进展涉及重用计算、自适应对抗步骤和一步计算。
Adversarial detection:以往地检测方法主要是分为基于统计、基于统计和基于模型两个阵营。基于统计学地方法源于标准化训练地模型学习到地特征。
Jointly learned rejection:在标准培训地文献中提出地联合学习分类器和拒绝模块后来再扩展到深度网络。最近Laidlaw and Feizi 和 Kato等人发现通过基于边际地目标再AT期间共同学习拒绝选项,而他们放弃了现成的信息,这被证明是PGD-AT的拒绝解决方案。另一方面,Stutz等人提出了通过自适应标签平滑的置信度校准AT(CCAT),导致更精确的拒绝对看不见的攻击。
3 Classification with a rejection option
考虑一个数据对(x,y)以 x ∈ R d x∈R^d x∈Rd作为输入,y作为真实标签。将 f Θ ( x ) : R d → ∆ L f_Θ(x):ℝ^d→∆^L fΘ(x):Rd→∆L其中∆L是L类的概率单纯形。根据盖夫曼和El-Yaniv,具有拒绝模块M的分类器可以表示为:

其中t是一个阈值,而M(x)是由辅助模型或统计数据计算的确定性代理。M的设计主要是由我们打算拒绝说明类型的输入来决定的。再对抗性环境中,以前的方法大多都旨在拒绝对抗性的例子,它们通常被标准化训练的模型错误的分类。因此,根据输入是否会被错误分类而不是对抗性来执行拒绝更为合理。
3.1 True confidence (T-Con) as a certainty oracle
为了拒绝错误分类的输入,有许多现成的选择来计算 M ( x ) M(x) M(x)。 我们使用 f θ ( x ) [ l ] f_θ(x)[l] fθ(x)[l] 来表示第 l l l类的返回概率,并将预测标签表示为:

其中 f θ ( x ) [ y m ] f_θ(x)[y^m] fθ(x)[ym]通称为置信度。在标准设置中,置信度被证明是训练有素的网络的最佳确定性代理之一,从业者经常使用它。与将最大值作为 m a x l f θ ( x ) [ l ] max_lf_θ(x)[l] maxlfθ(x)[l]不同,本文引入了定义为 f θ ( x ) [ y ] f_θ(x)[y] fθ(x)[y]的真实置信度(T-Con),即真实标签y上的返回概率。当通过最小化交叉熵损失 E [ − l o g f θ ( x ) [ y ] ] E[-log f_θ(x)[y]] E[−logfθ(x)[y]]来训练分类器时 − l o g f θ ( x ) [ y ] -log f_θ(x)[y] −logfθ(x)[y]的值可以更好地反映模型在新输入 x 上的泛化程度,与其经验近似值 − l o g f θ ( x ) [ y m ] -log fθ(x)[ym] −logfθ(x)[ym] 相比,尤其是当 x 被错误分类时(即 y m ≠ y y^m ≠ y ym=y)
Lemma 1(T-Con 作为确定性预言机)给定分类器 f θ f_θ fθ, ∀x_1, x_2 的置信度大于 1 2 \frac 12 21 ,即 f θ ( x 1 ) [ y 1 m ] > 1 2 和 f θ ( x 2 ) [ y 2 m ] > 1 2 f_θ(x_1)[y_1^m] > \frac 12 和 f_θ(x_2)[y_2^m] > \frac 12 fθ(x1)[y1m]>21和fθ(x2)[y2m]>21。 如果 x 1 x_1 x1 正确分类为 y 1 m = y 1 y_1^m = y_1 y1m=y1,而 x 2 x_2 x2 错误分类为 y 2 m = y 2 y_2^m = y_2 y2m=y2,则有 T C o n ( x 1 ) > 1 2 > T − C o n ( x 2 ) T Con(x_1) > \frac 12 > T-Con(x_2) TCon(x1)>21>T−Con(x2)。
直观的说,lemma 1 表示如果我们的第一个阈值置信度大于 1 2 \frac 12 21,那么T-Con可以完美地区分错误分类的输入和正确分类的输入。
4 Learning T-Con via rectifying confidence
4.1 Construction of rectified confidence (R-Con)
当输入 x 被 f θ f_θ fθ 正确分类时,即 y m = y y^m = y ym=y,置信度和 T-Con 的值变得对齐。 这激发了我们通过修正置信度来学习 T-Con,而不是从头开始建模 T-Con,这有利于优化防止分类器和拒绝器争夺模型容量。 引入一个辅助函数 A φ ( x ) ∈ [ 0 , 1 ] A_φ(x) ∈ [0, 1] Aφ(x)∈[0,1],由 φ 参数化,并构造修正置信度 (R-Con) R − C o n ( x ) = f θ ( x ) [ y m ] ⋅ A φ ( x ) . R-Con(x) = f_θ(x)[y^m] · A_φ(x). R−Con(x)=fθ(x)[ym]⋅Aφ(x).
可以通过最小化二元交叉熵 (BCE) 损失来实现 R-Con 与 T-Con 保持一致,也可以通过如基于边际的目标或均方误差代替。 为了符号简单,通常将 BCE 目标表示为 B C E ( f ∣ ∣ g ) = g ∤ ⋅ l o g f + ( 1 − g ∤ ) ⋅ l o g ( 1 − f ) , BCE(f||g) = g_{\nmid} · log f + (1 − g_{\nmid}) · log (1 − f), BCE(f∣∣g)=g∤⋅logf+(1−g∤)⋅log(1−f),
其中下标 ∤ \nmid ∤ 表示停止梯度,通常用于稳定训练的操作过程。 我们纠正拒绝(RR)模块的训练目标可以写成: L R R ( x , y ; θ , φ ) = B C E ( f θ ( x ) [ y m ] ⋅ A φ ( x ) ∣ ∣ f θ ( x ) [ y ] ) \mathcal{L}_{RR}(x, y; θ, φ) = BCE (f_θ(x)[y^m] · A_φ(x) || f_θ(x)[y]) LRR(x,y;θ,φ)=BCE(fθ(x)[ym]⋅Aφ(x)∣∣fθ(x)[y])
其中,关于φ,最小化 L R R \mathcal{L}_{RR} LRR的最优解是:

辅助函数 A φ ( x ) A_φ(x) Aφ(x)可以与分类器 f θ ( x ) f_θ(x) fθ(x)联合学习,其中学习机制成为 这里这里 λ 是一个超参数,B(x) 是围绕 x 的一组允许点(例如,一个 ∣ ∣ x 0 − x ∣ ∣ p ||x_0 − x||_p ∣∣x0−x∣∣p ≤ ε的球), L T \mathcal{L}_T LT 和 L A \mathcal{L}_A LA 分别是某个 AT 方法的训练和对抗目标,其中 L T \mathcal{L}_T LT 和 L A \mathcal{L}_A LA 可以是相同的,也可以是不同的选择 。
这里这里 λ 是一个超参数,B(x) 是围绕 x 的一组允许点(例如,一个 ∣ ∣ x 0 − x ∣ ∣ p ||x_0 − x||_p ∣∣x0−x∣∣p ≤ ε的球), L T \mathcal{L}_T LT 和 L A \mathcal{L}_A LA 分别是某个 AT 方法的训练和对抗目标,其中 L T \mathcal{L}_T LT 和 L A \mathcal{L}_A LA 可以是相同的,也可以是不同的选择 。
Definition 1:(ξ-error)如果至少有一个边界有效:

其中ξ∈[0,1),然后$A_φ(x)称为输入 x 处的 ξ 误差。
4.2 Certified separability using coupled rejectors
Theorem(已证明的可分离性)给定分类器 fθ,对于置信度大于 1 2 − ξ \frac 1{2−ξ } 2−ξ1的任何一对输入 x 1 和 x 2 x_1 和 x_2 x1和x2,即 f θ ( x 1 ) [ y 1 m ] > 1 2 − ξ , a n d f θ ( x 2 ) [ y 2 6 m ] > 1 2 − ξ , f_θ(x_1)[y_1^m] > \frac 1{2−ξ }, and f_θ(x_2)[y_26m] > \frac 1{2−ξ } , fθ(x1)[y1m]>2−ξ1,andfθ(x2)[y26m]>2−ξ1,
其中 ξ ∈ [0, 1)。 如果 x 1 x_1 x1 正确分类为 y 1 m = y 1 y_1^m = y_1 y1m=y1,而 x 2 x_2 x2 错误分类为 y 2 m = y 2 y_2^m = y_2 y2m=y2,且 A φ 是 x 1 、 x 2 A_φ 是 x_1、x_2 Aφ是x1、x2 处的 ξ-误差,则必定有 R − C o n ( x 1 ) > 1 2 > R − C o n ( x 2 ) R-Con(x_1) > \frac 1{2} > R-Con(x_2) R−Con(x1)>21>R−Con(x2)
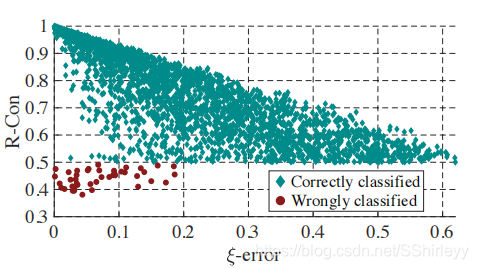
将 A φ A_φ Aφ 训练为 ξ 误差可能比学习稳健分类器更容易,这证明了错误分类但 ξ 误差点的存在.每个 ξ 的置信拒绝。 剩余的正确和错误分类的样本是可分离的 R-Con 度量,即使我们在不知道真实标签 y 的情况下无法在实践中计算 ξ-error.
4.3 The difficulty of learning A φ ( x ) A_φ(x) Aφ(x)
由于学习 A φ ( x ) A_φ(x) Aφ(x) 是一项回归任务,因此很难直接比较学习 A φ ( x ) 和 f θ ( x ) A_φ(x) 和 f_θ(x) Aφ(x)和fθ(x) 之间的难度。可以将学习 ξ − e r r o r A φ ( x ) ξ-error A_φ(x) ξ−errorAφ(x) 的回归任务转换为替代分类任务:
Theorem 2:( A φ ( x ) A_φ(x) Aφ(x) 的替代学习任务) 学习 ξ 误差 $A_φ(x) $的任务可以重构为 L s u b = m i n ( L 1 , L 2 ) L_{sub} = min(L_1, L_2) Lsub=min(L1,L2) 类的分类任务,其中

这里 · 是 舍入函数,ρ 是 A ∗ φ ( x ) A∗φ_(x) A∗φ(x) 较小值的预设舍入误差。
7 Conclusion
我们将 T-Con 作为确定性预言机引入,并通过训练使用 R-Con 模仿 T-Con。 有趣的是,可以将 ξ-error R-Con 拒绝器和 1 1 2 − ξ \frac 1{2−ξ} 2−ξ1 置信拒绝器耦合以提供经过认证的可分离性,这表明通过耦合拒绝器进行可靠预测的前景广阔。 本文还通过单独使用 R-Con 作为拒绝器来凭经验验证我们的 RR 模块的有效性,这减轻了对确定性的高估,并且与不同的 AT 框架很好地兼容。
这篇关于Adversarial Training with Rectified Rejection 笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







