本文主要是介绍Science | 大数据揭示野生动物肠道菌群的多样性与功能景观,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


写在前面
鉴于长文的阅读完成度较低,为节约彼此时间,尝试简短介绍文献(< 500字)。如需原文,请点击文末“阅读原文”,自行下载。本期分享的文章于2021年3月25日在Science网站在线发表。
肠道菌群的研究究竟有多火,已无需多言。但是相对于人类或者养殖动物的肠道菌群,学界对野生动物的肠道菌群关注较少、并且不够系统(对明星旗舰物种(例如大熊猫)的关注,当然是多的)。野生动物生活在自然环境中,其生存不可避免会受到各种病原菌或者有毒物质的威胁。研究认为,野生动物之所以能够在具有挑战性的自然环境中生存下来,可能与其体内/体表的微生物,尤其是肠道菌群具有重要关系。为了推动对野生动物肠道菌群多样性与功能的深入理解,本文在全球尺度上,采用统一方法进行大规模采样、统一处理,结合宏基因组测序技术,对184种动物、406份样品的肠道菌群进行了系统解析。详细内容如下。
正文
野生动物之所以能够耐受病原菌的感染和有毒食物的威胁以及抵御多种疾病,可能与其体内/体表生存的微生物密切关联,但是目前对动物微生物的多样性与功能仍然认识有限。本文采用一致的方法从四大洲采集了406份动物粪便样品,包括121份养殖样品和285份野生样品。共涉及184个动物物种,包括哺乳类、禽类、两栖类、硬骨鱼类等的物种。这些物种在分类单元、觅食/取食行为、地理分布、性状等方面具有较高的多样性。
本研究使用宏基因组学的方法,对肠道菌群进行分析。共组装出5080个基因组,分属于1209个细菌物种,其中75%的物种此前未知(一些基因组甚至无法归到已有的门)。进一步的分析发现,肠道菌群的组成、多样性、功能组分与动物的分类地位、饮食习惯、行为、社群结构以及寿命等都具有一定的相关性。尤其值得注意的是,在食腐动物的肠道菌群中,识别出一些能够代谢毒素的基因。与前人关于秃鹰的研究一致。这或许可以解释,为什么这些动物可以食腐尸,而自身不致病或死亡。由此可见,对于挖掘更多的医疗方案和改进生物技术,野生动物的肠道菌群是值得深入解析的资源库。而从动物保护的角度来看,深入解析相关内容,对于动物福利的维持以及提高放归动物的野化率都有较高的指导意义。
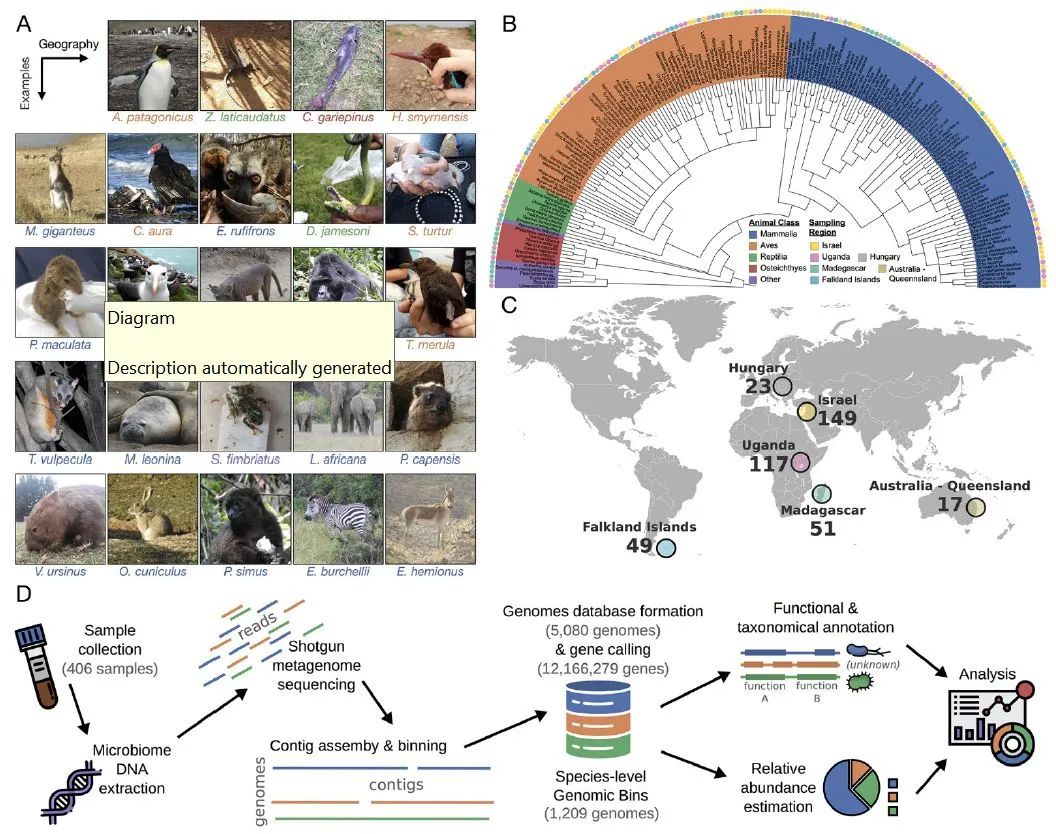
图1. 本文的取样与实验设计。
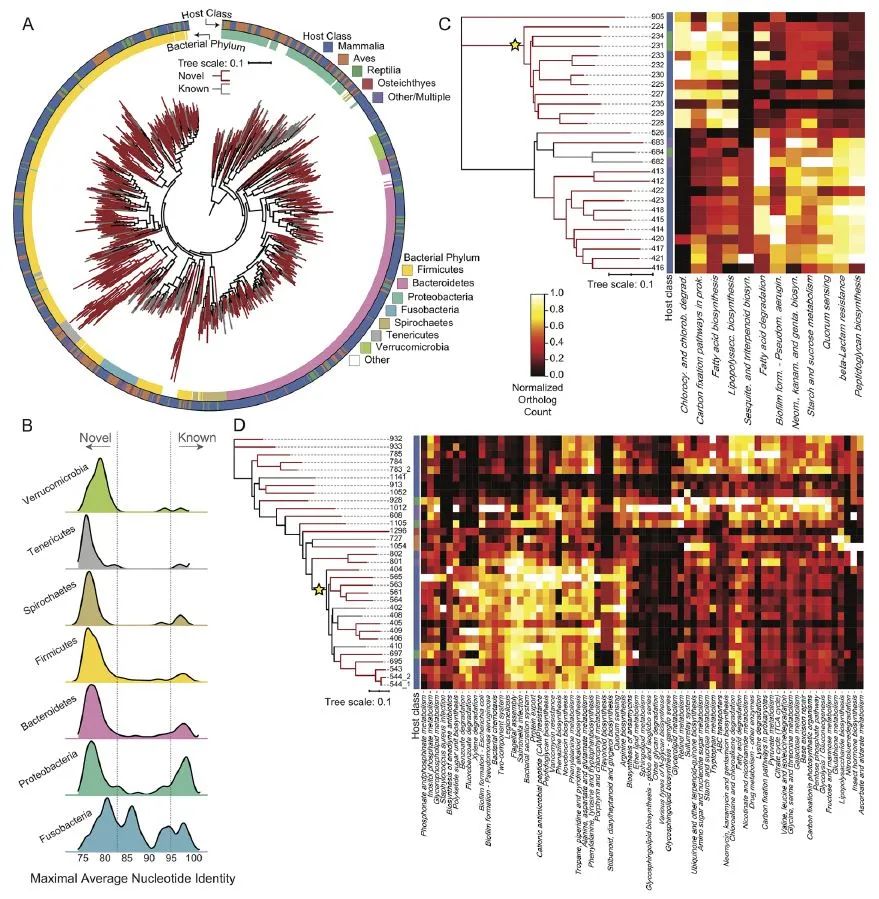
图2. 野生动物的肠道基因组拓展了已知的细菌遗传谱系多样性。
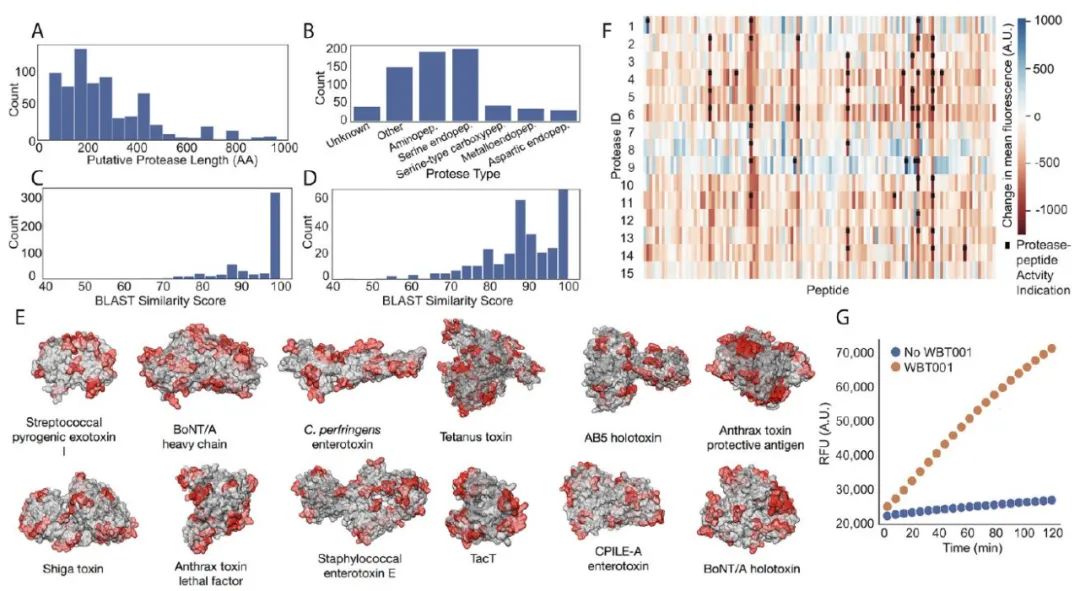
图3. 毒素代谢基因的发现与实验验证。

这篇关于Science | 大数据揭示野生动物肠道菌群的多样性与功能景观的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







