本文主要是介绍如何下载SRA存放在AWS的原始数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通常,我们都是利用prefetch从NCBI上获取数据,然后用fasterp-dump/fastq-dump 转成fastq。但遗憾的SRA的数据是原数据的有损压缩,比如说我19年参与发表的文章里单细胞数据上传的是3个文件,但是当时的faster-dump/fastq-dump只能拆出2份(目前可以顺利拆出三份)。
但在https://trace.ncbi.nlm.nih.gov/Traces/index.html?view=run_browser&display=metadata 搜索SRR8485805是可以看到我上传的三个原始数据。
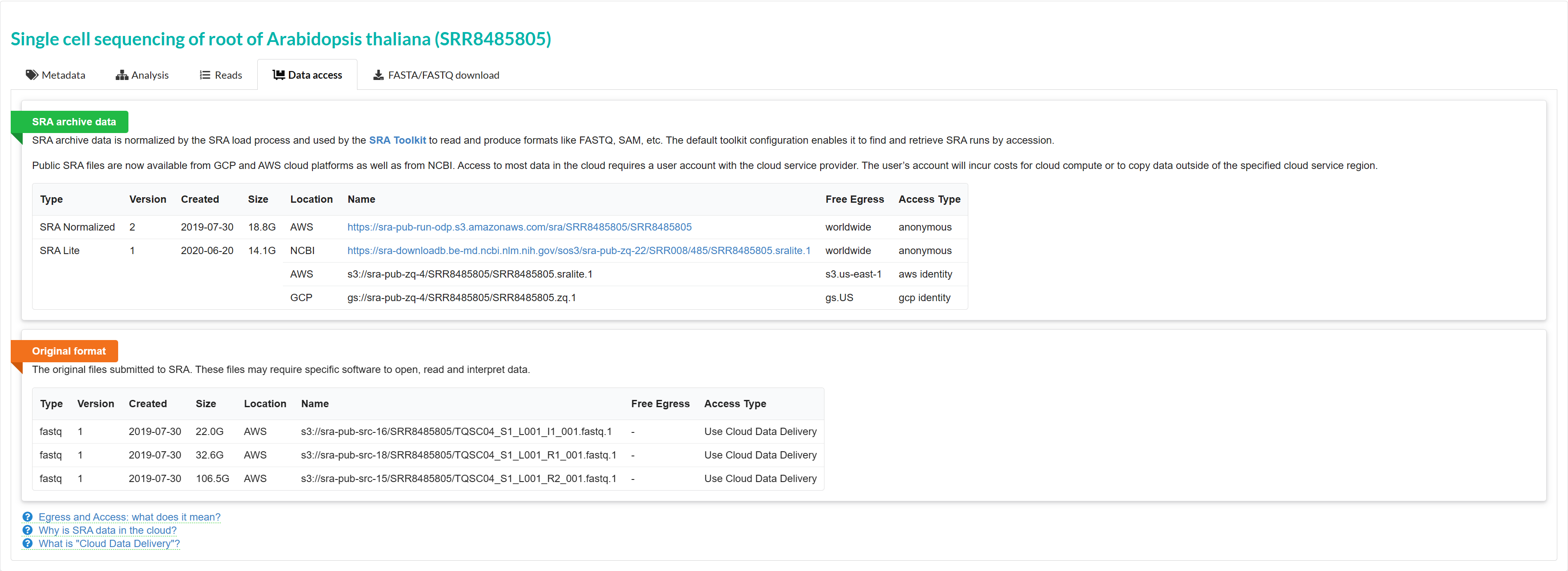
然而这些数据存放位置以S3开头,无法直接下载,必须需要通过Cloud Data Delivery的方式进行获取。
为什么,我们需要下载原始数据呢?
- 一些比对后的BAM,转成SRA后,可能就只能得到单端测序,而不是原来的双端
- PacBio HiFi测序输出的bam包含的编号信息,是纠错是必须的,不能损失
- 一些10x数据可能从sra解压缩成fastq后会出现问题
因此,有些时候,我们就需要获取最原始的作者的上传文件了。
创建Amazon的AWS账号
为了使用Cloud Data Deliver,我们你需要创建一个账号:https://aws.amazon.com/cn/cli/ 【需要一张信用卡用于支付账单】。在注册时候时候选择语音播报,我发现短信发送太慢了。
注:Amazon 的AWS如果90天不用,账号就会被停用,然后你就得重新创建账号。
最后一步,选择基本支持-免费(能省就省)

在AWS的控制台中(console.aws.amazon.com),选择存储的S3服务。
之后,我们创建一个存储桶。
大部分参数都保持默认,只需要修改两个配置,存桶的名称必须唯一,地区必须是美国的N. Virginia 。
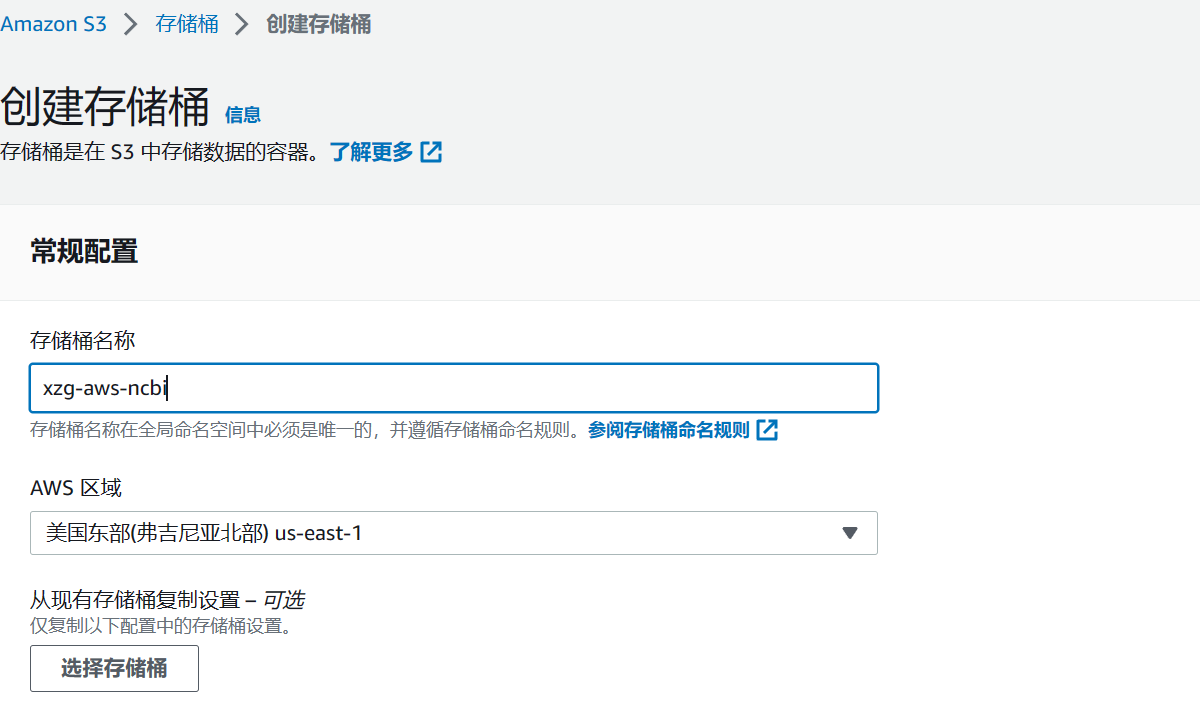
创建成功后,就可以回到NCBI这一边。
NCBI创建数据传输请求
通过https://www.ncbi.nlm.nih.gov/Traces/cloud-delivery/访问NCBI的云数据传递服务(这个服务是需要你登录NCBI)。
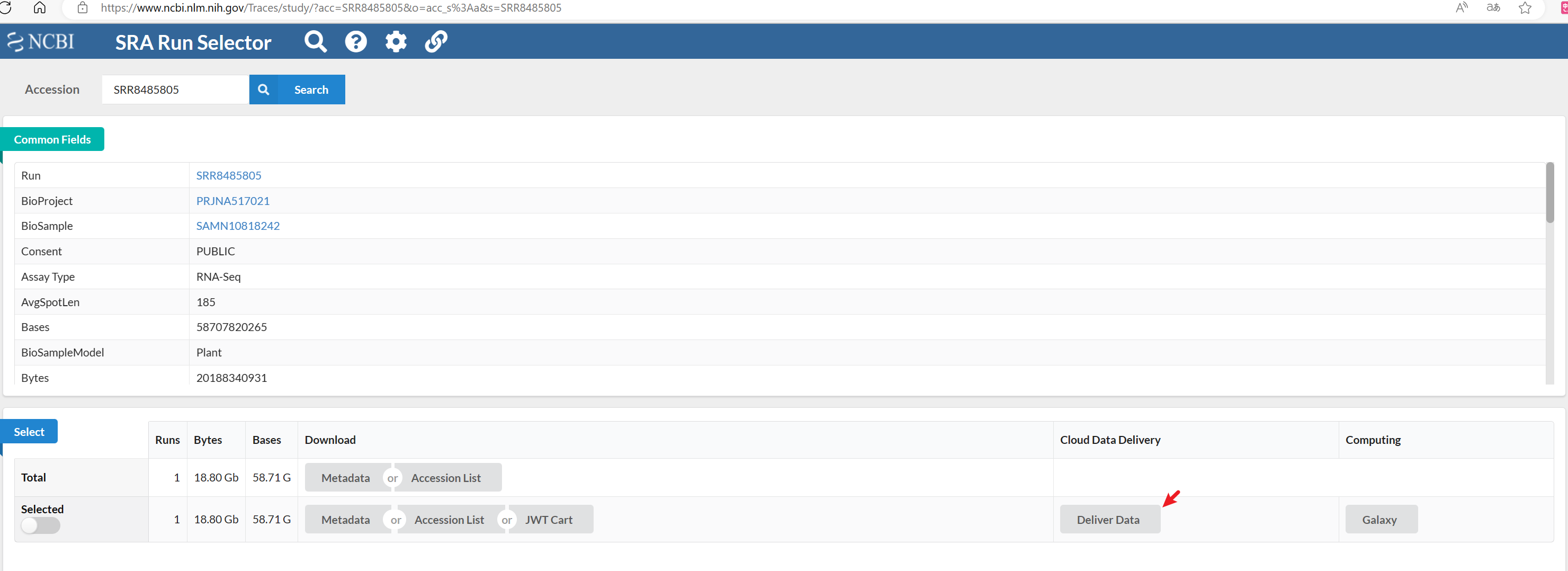
然后,我们需要选择我们需要获取的数据,通过https://www.ncbi.nlm.nih.gov/Traces/study/ 可以检索你需要的数据,例如SRR8485805。勾选需要传输的数据后,点击Deliver Data。
接着是关键的第二部,我们需要输入Bucket name,让NCBI给我们生成一个策略。
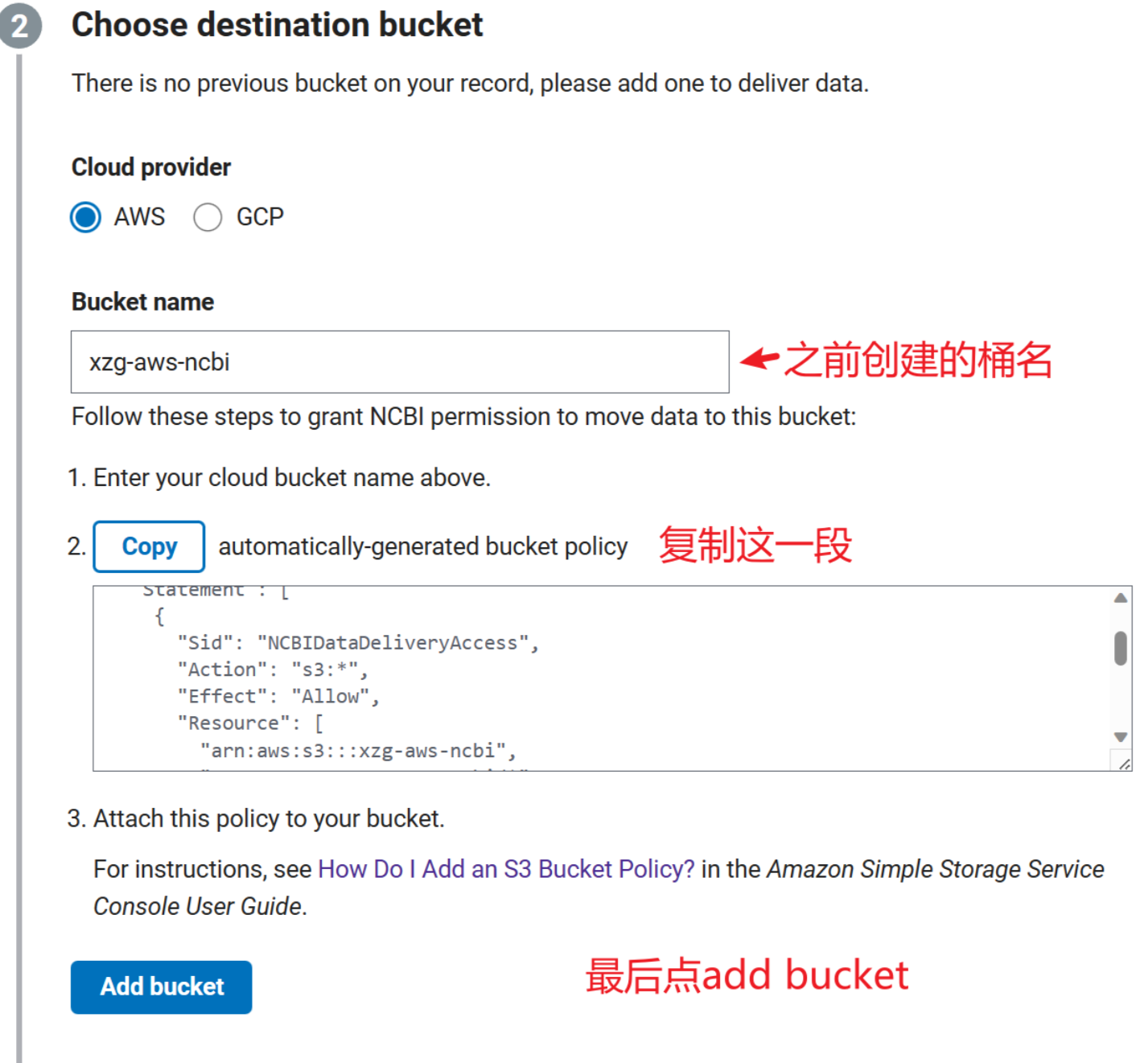
拿到这个策略后,我们需要访问https://s3.console.aws.amazon.com/s3/buckets,选择我们之前创建的桶

选择权限,并点击存储桶策略的编辑。
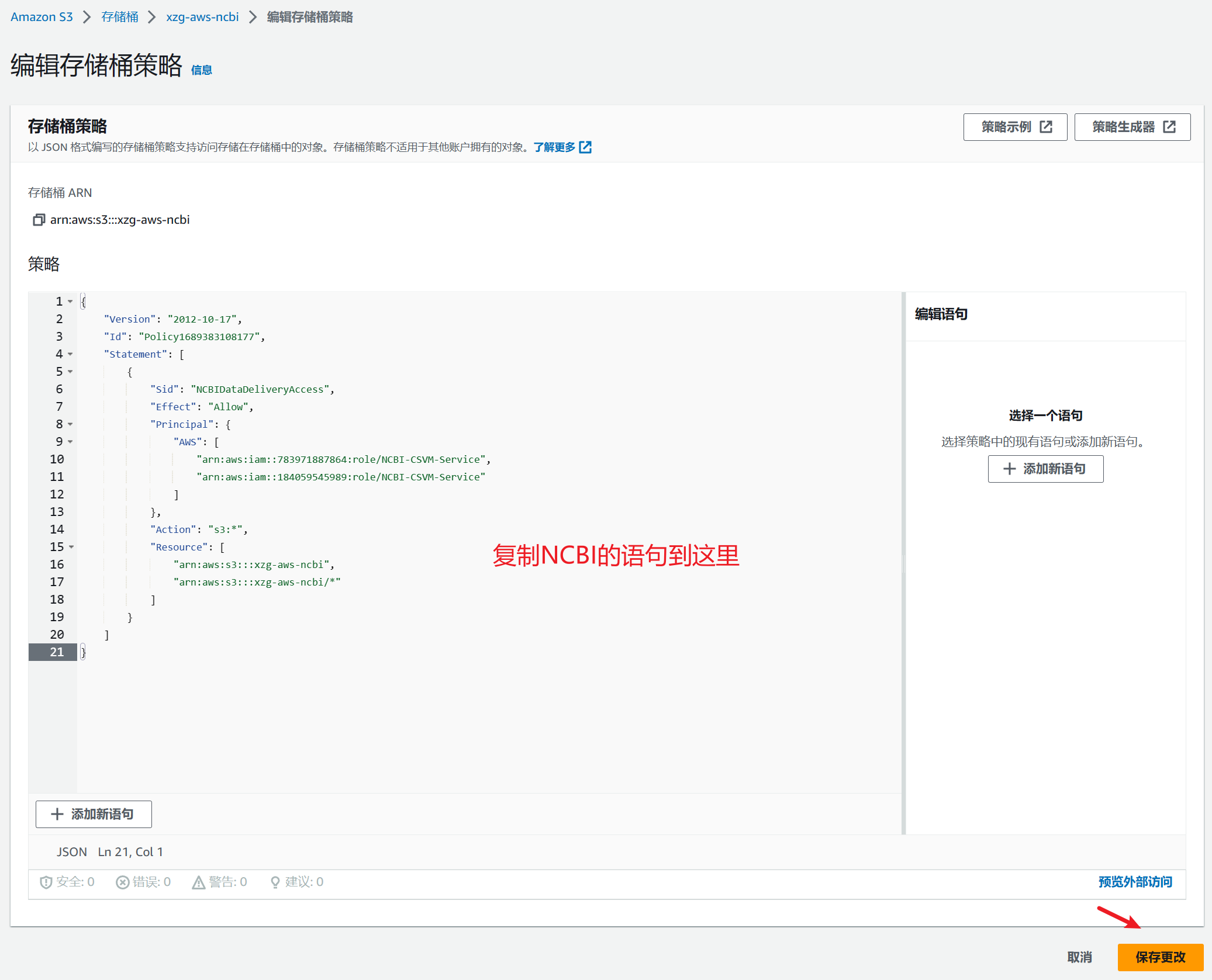
然后将粘贴NCBI上复制的语句,并保存更改即可。
最后勾选,你需要获取的数据,点击Deliver data。
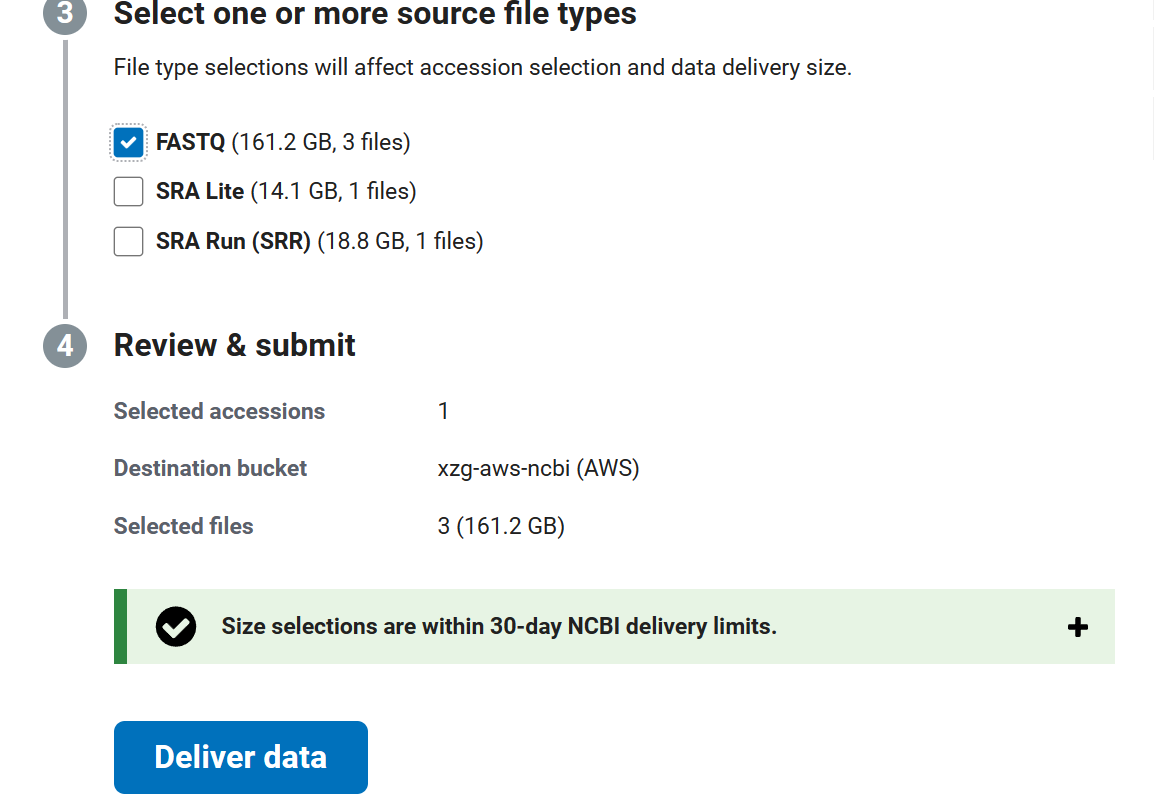
需要注意的是AWS的存储服务时收费的,它的定价页面见https://aws.amazon.com/cn/s3/pricing/
数据发起请求和请求完成,你都会在你登录账号对应的邮箱中收到邮件。
数据下载
获取数据之后,就可以从S3上下载数据了。
在此之前,我们需要先创建一个安全凭证。
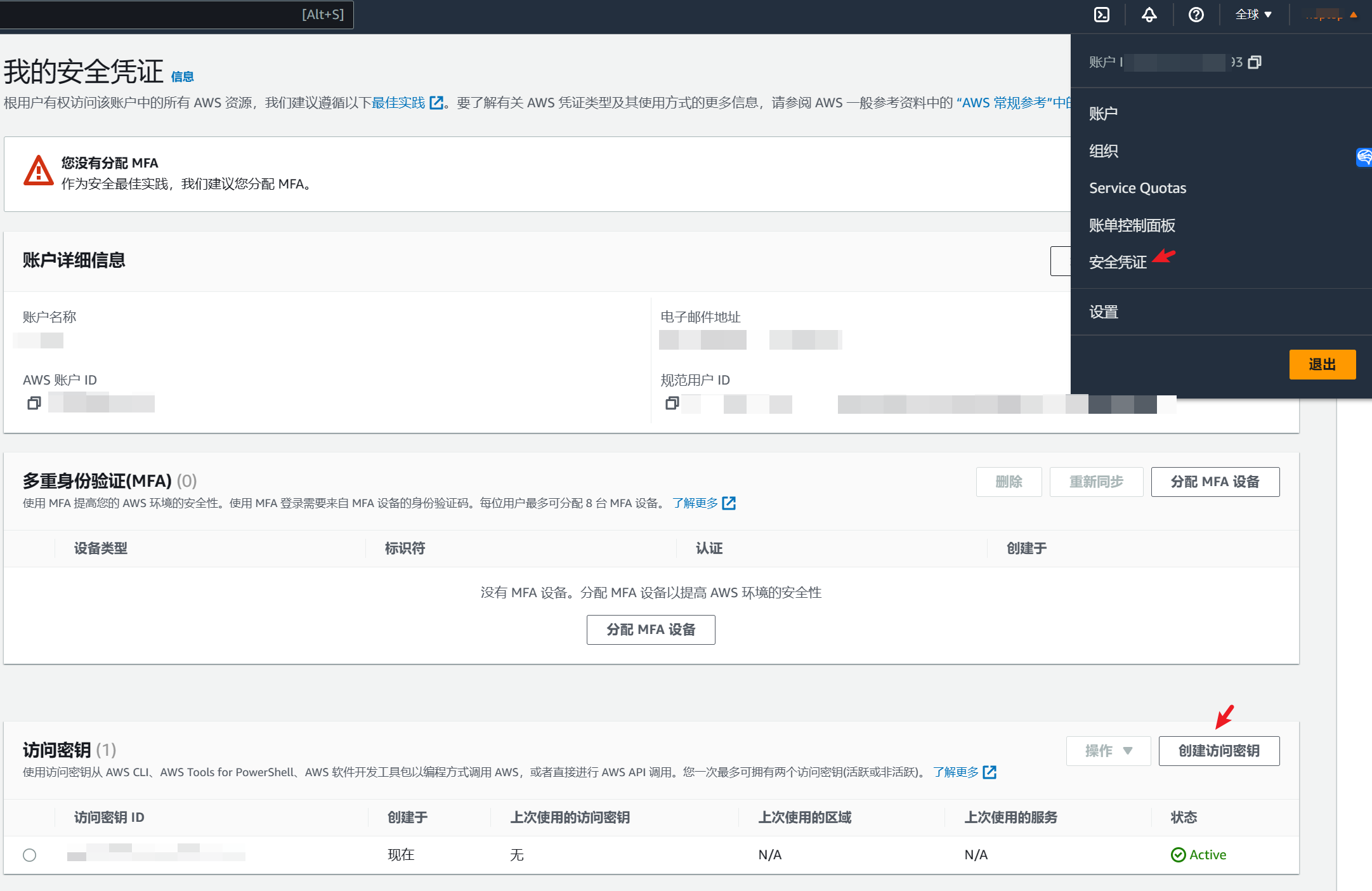
之后从https://docs.amazonaws.cn/cli/latest/userguide/getting-started-install.html获取你对应平台的软件
例如Linux的安装方式如下(以非root权限安装)
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
./aws/install -u -i ~/.local -b ~/.local/bin
# 安装成功的提示信息
You can now run: /home/xzg/.local/bin/aws --version
用密钥配置aws,
aws configure
后续,就可以上传和下载数据了,例如把数据传到aws
aws s3 cp app.R s3://xzg-aws-ncbi
# upload: ./app.R to s3://xzg-aws-ncbi/app.R
# 查看档期数据
aws s3 ls s3://xzg-aws-ncbi
2023-07-15 10:39:29 521416 app.R运行数据获取命令
# 命令形式如下
aws s3 cp --recursive s3://<bucket>/<folder> <local_folder>
# copy我从NCBI后去数据
aws s3 cp --recursive s3://xzg-aws-ncbi/SRR17027125 SRR17027125当然,你也可以选择在AWS的S3网页端进行下载。
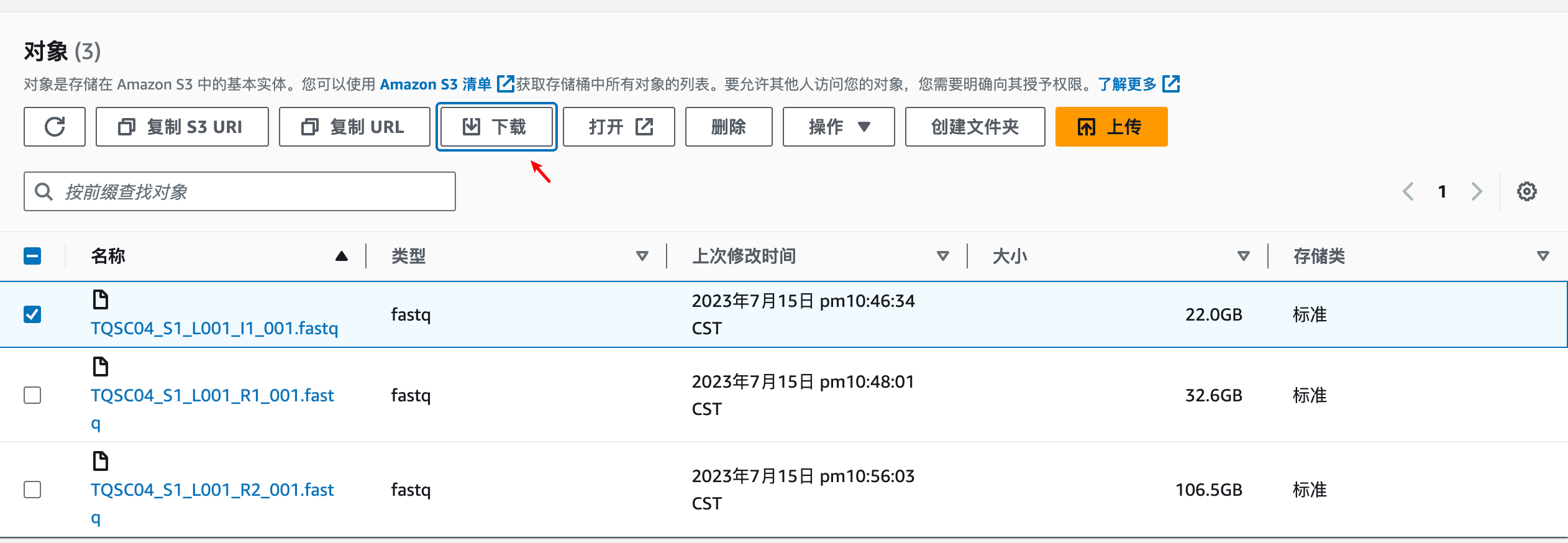
下载速度基本上不受限,只跟你家里的带宽有关。
可能的问题: An error occurred (RequestTimeTooSkewed) when calling the PutObject operation: The difference between the request time and the current time is too large
这可能是服务器的上时间偏差太大了 ,用chronyd矫正下(root权限)
chronyd -q 'server 0.pool.ntp.org iburst'
费用
分为两个部分:
- 存储上,标准的S3是每个月,前50T每 GB 0.023 USD,差不多是2毛钱1G
传输上:
- 传入不要钱
- 每月前 100GB 传出至互联网的数据,所有 AWS 服务和区域加总计算(中国和 GovCloud 区域除外)。
- 前10TB 每 GB 0.09 USD, 差不多是7毛钱1G
假设,你传了200G,不考虑免费额度,在带宽上花费140,然后存储是每天一块多(不需要的数据赶紧删,省钱)。
这篇关于如何下载SRA存放在AWS的原始数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




