本文主要是介绍A Performance Modelling Approach for SLA-Aware Resource Recommendation in Cloud Native Network,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:
网络功能虚拟化(NFV)成为5G网络演进的主要驱动力,近年来,网络功能云化(NFC)被证明是这一演进的必然组成部分。微服务架构也成为设计现代云原生网络功能(CNF)的事实上的选择,因为它能够将每个CNF的组件解耦成多个独立可管理的微服务。尽管在设计cnf时利用微服务架构可以解决特定问题,但这种额外的粒度使得估计生产环境(PE)的资源需求成为一项复杂的任务,有时还会导致PE供应过剩。传统上,性能工程师在较小的性能测试环境(PTE)中通过一系列性能基准对服务功能链(SFC)中的每个CNF进行维度分析。然后,考虑服务水平协议(SLA)中保证的服务提供者(SP)的服务质量(QoS)约束,他们估计建立PE所需的资源。在本文中,我们使用机器学习方法来建模每个微服务的资源配置(即CPU和内存)对PTE中每个服务功能链(SFC)的QoS指标(即服务吞吐量和延迟)的影响,然后,考虑服务提供者的服务水平目标(SLO),我们提出了一种算法来预测生产环境中每个微服务的资源容量。我们在云原生5G家庭用户服务器(HSS)的原型上评估了我们预测的准确性。我们的模型显示,在计算资源比PTE多2-5倍的PE中,准确率为95%-78%。
#### 微服务架构下,为每个微服务分配最优CPU、内存满足QoS。
创新点:
1)提出一种选择和执行最小基准集的算法,这些基准集用于训练微服务性能建模的回归模型(算法1+算法2)
2)建模:模拟NFC系统的关键QoS指标(如吞吐量)与每个微服务的CPU和内存配置之间的相关性
3)资源分配:对于每个微服务,基于提取的模型和提供的服务水平协议(SLA)约束,实例化最佳资源配置
系统架构:
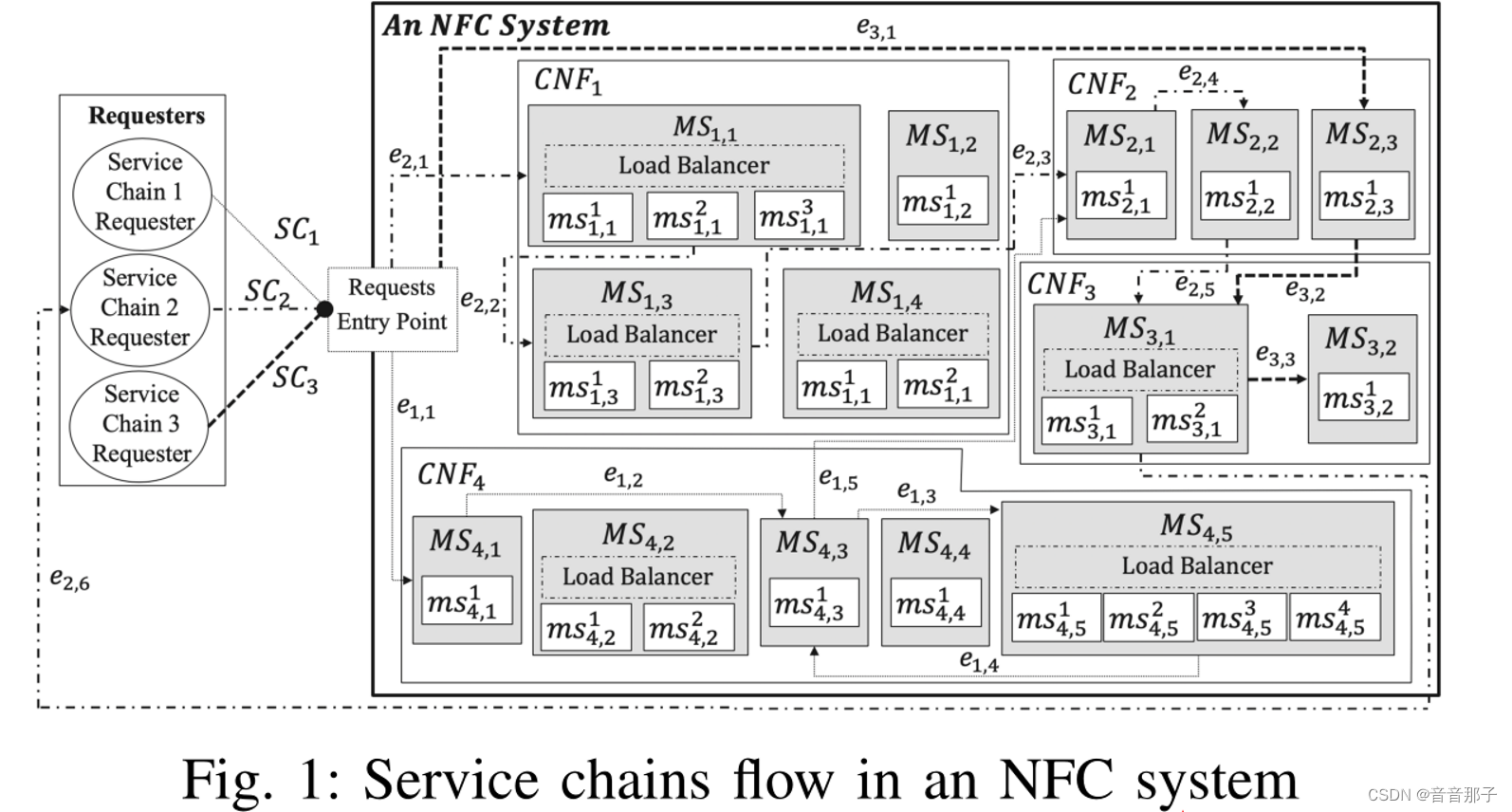
一个NFC由多个CNF组成
一个CNF包含多个MS(微服务),
一个MS包含多个ms(微服务实例),
MS服务于SC(服务链请求)。
微服务MS i,j中资源类型rd上分配的资源容量总量如下:
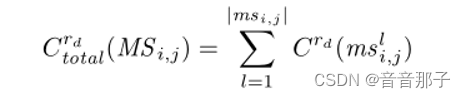
文章中的符号说明:

CNFi:第i个CNF
MSij:第i个CNF中第j个微服务
Mslij:第i个CNF中第j个微服务的第l个微服务实例
M:工作节点集合,mo工作节点实例
rd:第d种资源类型,R资源类型集合
Crd:rd资源类型的容量
E1:可变步长值
E2:可变阈值
SCk:第k条服务链
MSk:属于服务链SCk的所有微服务
Ek:服务链SCk上所有的边
a:一个虚拟用户
Q:质量指标集合,qc:一个质量指标
SLAka(qc):服务链SCk上QoS度量qc的保证值与用户α在SLA中达成一致
Tp:资源分配配置。每个tp(rd)表示分配给微服务之前的资源容量Crdtotal。

Vk:服务链SCk中当前qc值
Vkij:当所有微服务的资源容量设为Tp={Crdmax}rd∈R时,除微服务msi j的资源容量设为Tp外,服务链SC k中qc的V值
H(.):为微服务建模的一组可能的假设
h(Msij):为微服务MS选择一个假设
Vkij(qc):提取了微服务MSij对质量度量qc和服务链SCk的性能影响模型
Tkij(qc):T的子集作为训练回归模型Vkij(qc)的输入;
Nkij(qc):训练数据集Tkij(qc)的期望大小
Pkqc(a):基于质量度量qc和服务链SC k的用户α支持sla的资源推荐矩阵
Pk(a):考虑所有QoS约束{SLAkα(qc)}qc∈Q,服务链SC k上用户α的最终资源推荐矩阵
微服务MS i,j∈MS k的资源分配配置,此时的质量度量值vk (qc)开始饱和
基准测试:

图3:(a)所有可能的CPU和内存配置的吞吐量模型。显然,生成这样的图需要对多个CPU和内存配置进行大量的实验,因此并不可取。因此,我们提出了一种配置选择算法(算法1),该算法可以最大限度地减少模拟每个微服务资源分配配置对系统QoS度量值的影响所需的实验数量。
b:找到饱和点并将测试空间划分为四个部分(对应算法1,二分查找运行基准测试,找到饱和点
c:仅选择一组随机的CPU和内存配置来执行每个部门的基准测试(可取):非饱和点随机选取n个点运行基准测试
算法1

算法1:
首先通过执行二进制搜索来查找一种资源类型(例如,内存容量)的饱和点,然后对其他资源类型(例如,CPU容量)重复相同的搜索。找到关键饱和点,以便在该点之后增加资源容量不会对系统性能产生显着影响,从而导致QoS指标开始饱和。该算法对每个微服务的复杂度为0 (logn),适用于大型系统。图3 (b)表示在上述LDAP Server原型中寻找饱和点的所有尝试。然后,在找到这个关键饱和点后,我们将我们的测试空间划分为多个分区,排除饱和区域内的所有点。对于其余的点,我们只在我们的测试空间中随机选择一组点,并保持测试点的数量与每个划分的大小成正比,以避免机器学习模型在下一步过度拟合。
输入:- SC k:服务链,- {MS i,j}∈MS k:服务链中的所有微服务,- {rd}∈R:所有资源维度- {qc}∈Q:度量指标, - ?1, ?2:两个常量
输出:- ∀qc ∈ Q, MS i,j ∈ MS k → ψki,j(qc) ∈ T:微服务MS i,j∈MS k的资源分配配置---饱和点的资源配置
算法步骤:
- 循环遍历资源R,对于每个资源维度rd,初始化tleft[rd]和tright[rd]为MS i,j的最小和最大容量,分别代表该资源维度的可用范围。
- 循环遍历度量指标集合Q,对于每个微服务MS i,j和每个度量qc,将MS i,j的最大容量设置为其初始容量。
- 对于每个资源维度rd,不断执行以下步骤直到tleft[rd] > tright[rd]:
- 计算当前资源维度rd的中间点tmid[rd]。
- 构建三个容量集合T[1]、T[2]和T[3],分别对应于tmid[rd]、tmid[rd]+?1和tmid[rd]-?1。
- 对于每个容量集合T[l](其中l=1,2,3),将MS i,j的容量设置为T[l],并检查是否已经测试过该配置。
- 如果该配置没有被测试过,就运行服务链SC k的基准测试,并将结果存储在V ki,j(qc0, T[l])中(其中qc0是请求的初始类别)。
- 如果V ki,j(qc, T[1]) + ?2 ≥ V ki,j(qc, T[2])且V ki,j(qc, T[1]) - ?2 < V ki,j(qc, T[3]),则说明T[1]是饱和点,将其记录在ψki,j(qc)中。
- 如果V ki,j(qc, T[1]) + ?2 < V ki,j(qc, T[2])且V ki,j(qc, T[1]) - ?2 > V ki,j(qc, T[3]),则说明T[1]不是饱和点,需要将tleft[rd]更新为tmid[rd]+?1或tright[rd]更新为tmid[rd]-?1。
- 如果上述两个条件都不满足,则说明T[1]可能是饱和点,但需要继续收缩T[1]的范围,因此将tright[rd]更新为tleft[rd]-?1。
- 最终,所有中间服务MS i,j在请求qc下的饱和点都存储在ψki,j(qc)中。
这个算法使用了迭代二分搜索的思想,可以高效地找到饱和点。还使用了基准测试来评估服务链SC k在不同配置下的性能,从而确定哪些配置是饱和点。
算法2

算法2:基于ψki,j(qc)在SC k中选择一个最小配置集进行基准测试
输入:SC ,一组MS(主机),一组rd(资源分配),一组qc,每个MS的最小和最大容量
##??每个qc在每个MS上的资源利用率指标和每个qc需要运行的测试次数n。
输出:每个qc在每个MS上的估计运行时间以及每个qc在每个MS上运行的配置。
Vkij(qc):当所有微服务的资源容量设为Tp={Crdmax}rd∈R时,除微服务msi j的资源容量设为Tp外,服务链SC k中qc的V值(运行数据)
算法的步骤如下:
1. 对于每个MS,将其最大容量设置为其初始容量。
2. 对于每个qc,运行N次测试,每次测试都要随机分配资源rd。
3. 对于每个资源rd,从其最小容量到qc在MS上的资源利用率ψki,j(qc)之间随机选择一个容量。
4. 将所有资源的容量组合成一个配置集合,并将其分配给MS i,j。
5. 检查此配置是否之前已经测试过,如果没有,则运行基准测试。
6. 记录每个qc在每个MS上的估计运行时间和运行的配置。
该算法的目的是减少在SC上运行基准测试所需的配置数量,从而降低测试成本。它通过随机选择资源分配和检查之前是否测试过来确保测试的准确性。
(1)基于算法1执行最小的性能基准集;(2)基于算法2训练并找到适合当前数据的最佳回归模型;
(3)基于给定的样本SLA需求,根据提取的机器学习模型为每个微服务推荐资源。
建模:回归建模微服务资源配置对服务链QoS性能的影响
针对给定的微服务MS i,j和QoS指标qc,以及服务链SC k,我们训练一个单独的回归模型ˆV ki,j(qc),以预测当MS i,j的资源分配大小为Tp时qc的值。为了训练每个回归模型ˆV ki,j(qc),我们使用算法1构建的训练输入集{Tp}∈ˆT ki,j(qc),以及相应的目标{V ki,j(qc, Tp)}Tp∈ˆT ki,j(qc)。在训练输入集中,每个Tp是一个多维矩阵,表示所有资源类型的一组资源分配大小。为了学习一个逼近回归模型,目的是对以前未见过的模板Tp进行准确的QoS指标值V k(qc)预测,我们的算法训练一个假设函数。当然,每个微服务的行为可能不同,因此可能需要测试不同的假设。
假设有两种资源类型r1和r2(即CPU和内存)和质量度量qc(即服务吞吐量),并假设所有微服务遵循单调增加的性能模型,从而通过增加每种资源类型的容量(达到限制)QoS度量将增加或保持不变,我们定义假设{hi (Cr1total, Cr2total)}|h| i=1如下: ----多项式一阶+二阶+常数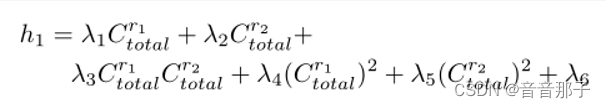
资源配置算法:
在SLA协商期间,用户可能会要求某些QoS要求(即,特定数量的吞吐量或延迟),服务提供商需要保证这些要求,以防止潜在的SLA违反处罚。此外,用户和服务提供者都希望对所需基础设施的价格/成本有一个粗略的估计。因此,给定用户SLA中同意的QoS需求SLA α(qc),并使用我们在较小的PTE建模阶段提取的估计模型_ V ki,j(qc),我们建议为每个微服务MS i,j提供满足用户SLA中同意的所有QoS约束的资源分配配置。
目标:目标:基于给定的QoS要求,在SLAkα(qc)中找到每个MS i,j的最小资源容量

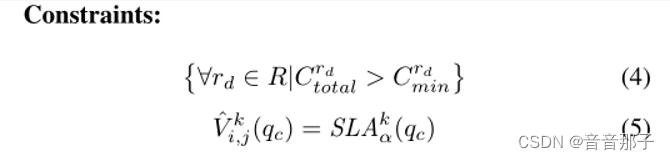
为了解决这个优化问题,我们将其分为两类。如果φ V ki,j(qc)是一个线性方程(基于假设h1),那么考虑这两个准则,最优资源配置是距原点(0,0)最近的点,这种情况很少;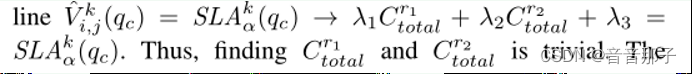
第二类是提取的回归模型_ V ki,j(qc)的一般形式为: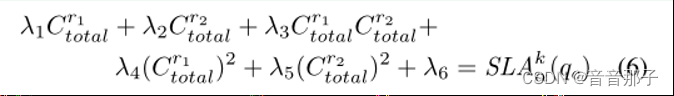
一系列假设推导后得到资源推荐矩阵:
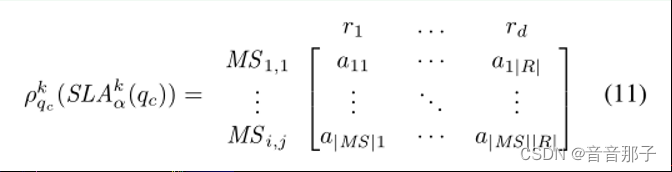
实验:5vm,4c8G

资源:CPU [500,1000],内存:[1000,64000]
指标:吞吐量
服务链请求:http请求
总结:
提出了一个基于模型的解决方案,用于在将NFC部署到PE中之前,为所有cnf中的每个微服务推荐初始资源配置策略,并与每个客户的SLA中保证的QoS约束保持一致。我们在5G vEPC系统的HSS组件的早期原型上评估了我们的方法。我们获得了78%-96%的PE预测精度,PE的计算资源比我们生成回归模型的PTE多5到2倍。
这篇关于A Performance Modelling Approach for SLA-Aware Resource Recommendation in Cloud Native Network的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









