本文主要是介绍CoST, STM, E3D-LSTM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
好久没看视频相关的文章了,刚好最近看到几篇还不错的,写个笔记总结下:
- CoST[1]: 海康CVPR19的文章,个人感觉非常不错,主要是将传统LBP-TOP那套XY-YT-XT视角分解的思想用到视频分类里,而不必使用以XYT为视角的3x3x3卷积,减少了很多冗余参数。
2. STM[2]:商汤ICCV19的文章。第一次看名字,以为是比较早期挂出来的 TSM[4]。。。 基于TSN的2DCNN框架,也不需要提前计算好的光流,通过channel-wise的时空模块和运动模块直接在RGB采样帧中提取特征,轻量效果不错。
Fisher Yu余梓彤:时空建模新文解读:用于高效视频理解的TSMzhuanlan.zhihu.com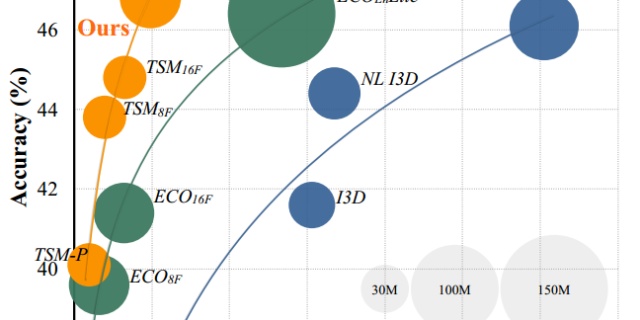
3. E3D-LSTM[3]:挂上李飞飞的ICLR2019文章。在 PredRNN[5] 的基础上,融入了3DCNN的输入作为short-term features,且加上了NLP中的attention机制,来获取更整体Long-term的记忆。
它们之间的关联:
对于 CoST 和 STM,都是基于3DCNN的一些轻量化优化,毕竟3DCNN真的是太庞大太冗余了,都是不需要额外光流计算且能融到当前主流的2DCNN框架里。个人认为CoST更优雅些且insight很足,而STM有点像是组合TSM和OFF[6], MFN[7]的一个unified版本;而E3D-LSTM更多是填坑组合式工作,把3DCNN和transformer的东西引入到RNN,成了the first。不管怎么说,都是很优秀的工作,用了看完了绝对有收获有价值。
--------------------------------------------
一、CoST [1],CVPR19
主要贡献有两点:
1.构造了Collaborative SpatioTemporal (CoST) operation,仅仅用2D conv即可捕获时空信息。
2.可视化了不同数据集及不同层间spatial和temporal的重要性程度,为future的网络设计有极大的参考作用。
Motivation:
我们首先来回顾下经典的动态纹理方法 LBP-TOP[8],将sequence分成三个正交平面,然后分别提取LBP特征,最后特征concat:

LBP-TOP
而该文的图一也同样展示了视频的三个view,明显从HT的视角来看,运动员的动作变化非常显著。基于这三个view,作者设计了 1x3x3, 3x3x1,3x1x3 卷积。哈哈,细心观察这三个图的话,你会发现不同的view对该视频内容的贡献不同,即作者后面提到的attention机制。

视频分解成三个view
具体算法:
首先来看看经典的3DCNN操作子:
(a)经典的3x3x3卷积,参数多,运算量大
(b)伪3D卷积,参数量少,运算量较小
(c)文章提出的CoST卷积,由于三个view中的卷积共享权值,故参数量等于传统的2D卷积。

OK,那么问题来了,可能你会问,为什么三个view的卷积能共享参数?那几个attention的weights又该怎么计算呢?
第一个问题看Motivation的三个子图可以大概理解,都看成一个2D image,都看成提取Image里的特征,理论上来说是可以设计成共享的。(当然啦,主要还是后面的消融实验证明了shared的性能更好)
第二个问题一般有两种方案来解决:
A、如下图所示,直接生成softmax weights来分配贡献,简单粗暴。
B、如下图所示,建立content-aware的self-attention来分配权重,中间又额外插入了类SE module来增强channel间的关联。

OK,主要内容到这里已经完了,是不是特别清爽。把这个CoST操作替换掉 ResNet50/101中residual block的 3x3 卷积即可。
实验结果:
实验都在大数据集Kinectics和Moments上进行,这文章的方法是 won the 1st place in the Moments in Time Challenge 2018.
首先来看看消融实验,Table 2中的CoST(a)和CoST(b)分别代表前面提到的两种attention weight生成方式,很明显self-attention的性能更优。Table 3中则验证了1x3x3, 3x1x3, 3x3x1间 share weight 的性能更好。

最后列下在Kinetics400下只用RGB模态的SOTA结果:

在只采样8帧or32帧的情况下,性能已经接近SOTA;算力足的话,128frame超过NL_I3D应该是没啥问题的。
Discussion:
在文章的最后,作者讨论了不同view HW, TH, TW间的attention weights的分布(HW更多是表征空间外观的特征,TH和TW更多表征temporal特征)。
分析1:On Moments in Time, the mean coefficients of the H-W, T-W and T-H views are 0.67, 0.14 and 0.19 respectively. While on Kinetics they are 0.77, 0.08 and 0.15.
说明spatial appearance特征在两个数据集都起最重要的作用。而相比Kinetics来说,Moments数据集的动作尺度更丰富,对应的TW、TH权值也较大。
分析2:如下图所示,可视化了不同层之间的三个view的权值关系。可见一般在浅的层,空间外观特征会占绝对主导;而随着层渐渐变深,temporal在semantic的特征中起得作用越来越大。这比起之前S3D那文章手动验证啥Top-heavy啥的优雅得多,而我觉得这图对未来很多3D网络设计会起到一定的引导作用。

----------------------------------------------------
二、STM [2] (SpatioTemporal and Motion Encoding),ICCV19
主要贡献:
提出了Channel-wise Spatiotemporal Module (CSTM) 和 Channel-wise Motion Module (CMM)来分别提取时空特征和motion特征,轻量且仅额外引进很少计算量。
PS:这里的时空特征和motion特征更多的是对标传统的3DCNN特征和motion stream的2DCNN特征。

STM block
具体算法:
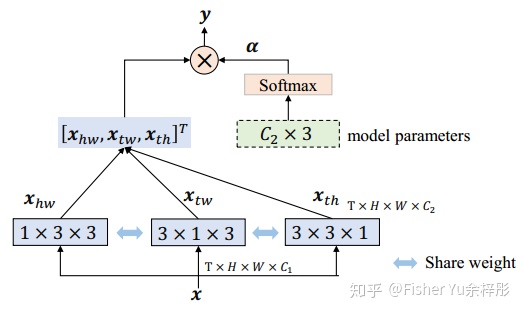
如上图所示,STM block能直接替换Backbone ResNet中的residual Block,其中在1x1卷积通道压缩后,分别进行CSTM和CMM的特征提取,然后进行 add (消融实验里验证了'add' 比 'concat+1x1卷积' 效果要好)特征融合,最后上扩通道数并与原输入特征相加。
接着来看看CSTM和CMM是怎么实现的:

比较亮点的地方是使用了channel-wise卷积,更精确学习特定channel语义特征基础上,减少了计算量,且消融实验验证了这样性能更好。(a)和(b)中黄色高亮字体的几个卷积是用了channel-wise的,CSTM是沿着temporal dimension来做,而CMM算伪光流的时候是沿着spatial做。总感觉文章怪怪的,是个精简版的TSM和OFF。
实验结果:
由于temporal-related 数据集(Something-something, Jester) 对上下文motion要求更苛刻,而scene-related 数据集(Kinetics-400, UCF-101, HMDB-51)对单帧场景需求更大,故我们来直接看看在temporal-related 数据集上的表现吧:
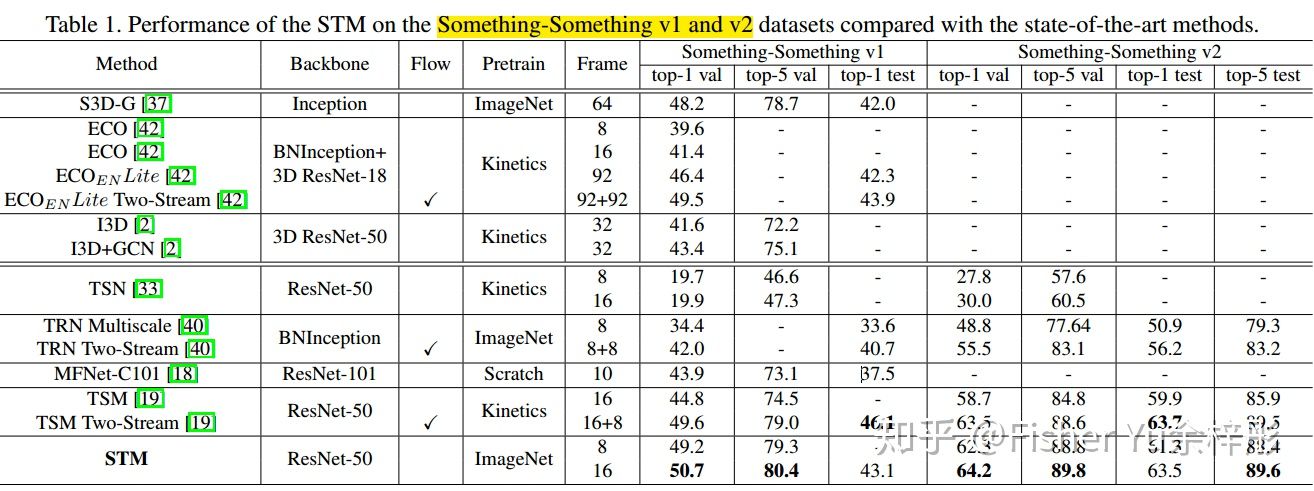
可见仅需RGB视频作为输入,且使用ResNet-50的backbone,也能获得丰富的temporal信息,来取得SOTA效果。
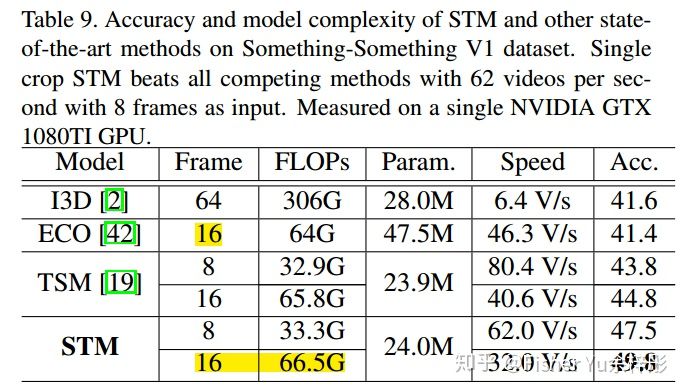
最后来看看实时性,相比前面几个方法,确实更适合落地使用。
----------------------------------------------------
三、E3D-LSTM [3] (EIDETIC 3D LSTM),ICLR19
主要贡献:
1.把3DCNN和RNN结合起来用了,针对于frame-level features的RNN,文中以short-time clip的3DCNN的特征作为RNN的输入,故在输入层面已经是有short-term frame dependency.
2. 为了更好地捕捉long-term relation,在RNN内部构造了gate-controlled self-attention module,故可以有针对性地记忆历史的任何特征。

几种将3DCNN融入RNN的方案
具体算法:
对该文感兴趣的,可以去看下PredRNN[5] 中的Spatiotemporal LSTM 和 Attention is all you need。如下图所示,核心模块E3D-LSTM就是将attention机制(图中蓝色箭头部分)用在Spatiotemporal LSTM里:

核心的公式就是下面这条,高亮的部分就是attention:

实验结果:
最后我们来看看它在video prediction下的效果:
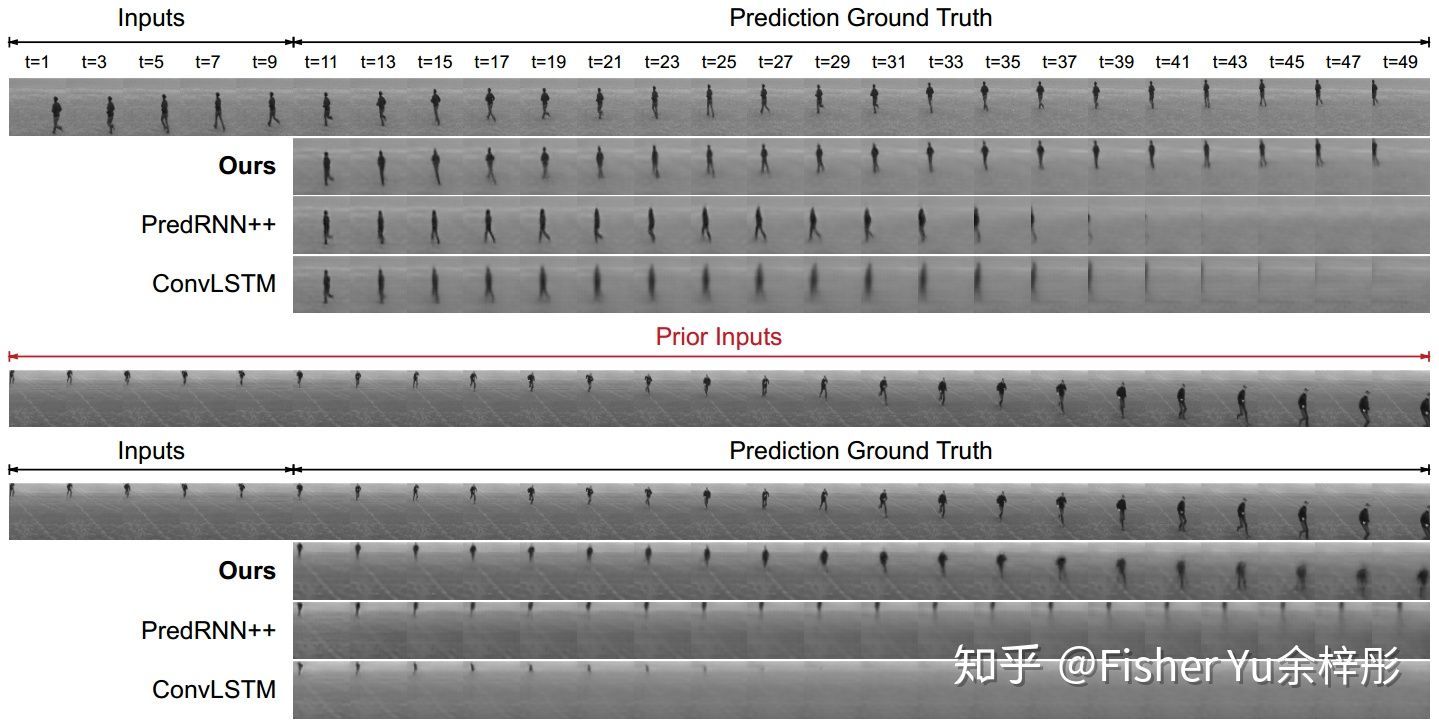
Generated frames on KTH
-------------------------------------------------------
总结与展望:
单RGB模态的视频理解肯定是未来主流方向,总觉得提前算个意义模糊的光流图出来怪怪的。当然啦,往落地方向又好又快地套2DCNN框架是比较实在;但从research角度来说,现在对3DCNN及ST-RNN的认知还是很浅,未来还有很多有趣的东西可以摸索~~
Reference:
[1] Chao Li et al., Collaborative Spatiotemporal Feature Learning for Video Action Recognition, CVPR2019
[2] Boyuan Jiang et al., STM: SpatioTemporal and Motion Encoding for Action Recognition, ICCV2019
[3] Yunbo Wang et al., EIDETIC 3D LSTM: A MODEL FOR VIDEO PREDICTION AND BEYOND, ICLR2019
[4] Ji Lin et al., Temporal Shift Module for Efficient Video Understanding, ICCV2019
[5] Yunbo Wang et al., PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs, CVPR2019
[6] Shuyang Sun et al., Optical flow guided feature: a fast and robust motion representation for video action recognitio, CVPR2018
[7] Myunggi Lee et al., Motion Feature Network: Fixed Motion Filter for Action Recognition, ECCV2018
[8] Guoying Zhao et al., Dynamic texture recognition using local binary patterns with an application to facial expressions, TPAMI 2007
这篇关于CoST, STM, E3D-LSTM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








