本文主要是介绍GitHub 操作:同步 Fork 来的仓库(上游仓库),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GitHub 操作:同步 Fork 来的仓库
Fork 是 Github 上的常用操作之一,不同于 Star,Fork 会将进行 Fork 操作那一刻的仓库代码完全复制到自己的仓库下。Fork 之后,我们可能会为原仓库添加一个 Feature,之后发起 Pull Request。
往往在 Fork 之后,原仓库的作者也会进行代码更新,与我们自身的更新在 Git Commit 树中会分叉,如下图所示:
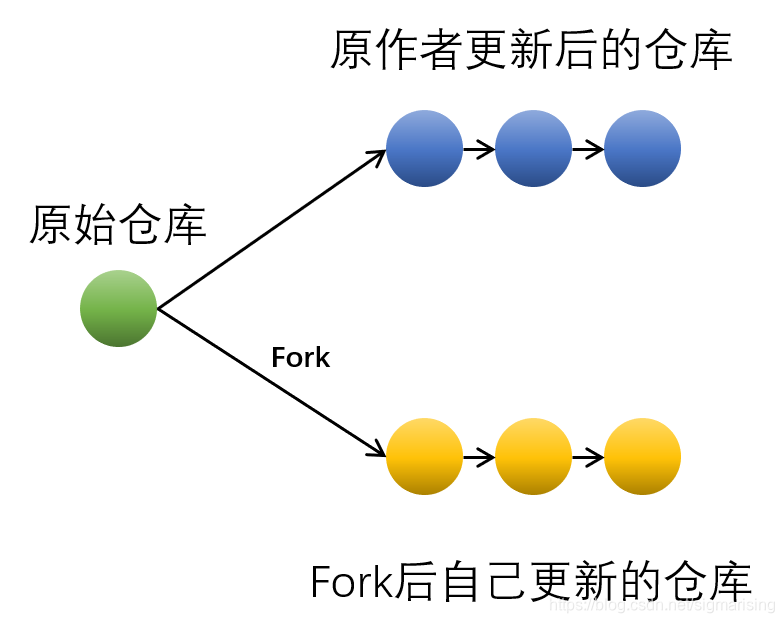
在某些这样的时候,我们发起的 Pull Request 是有冲突的。就算没有冲突,及时在发送 Pull Request 之前同步原仓库的代码也是十分必要的。本文将会介绍同步 Fork 原仓库代码的方法。
Step 1. 添加 upstream
我们首先要在 Git 中配置指向上游仓库(即 Fork 前的原本仓库)的远程仓库。
查看当前的 remote 情况:
$ git remote -v # 列出当前的 remote 情况
> origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (fetch)
> origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (push)
添加上游仓库的地址:
$ git remote add upstream https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY.git
验证:
$ git remote -v
> origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (fetch)
> origin https://github.com/YOUR_USERNAME/YOUR_FORK.git (push)
> upstream https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY.git (fetch)
> upstream https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY.git (push)
Step 2. 同步上游仓库代码
我们可以直接使用 git pull 命令同步 upstream 的指定分支即可。
为了更加保险,可使用 git pull --rebase 在本地解决可能发生的冲突。
Step 3. 上传到自己的仓库,发起PR
同步代码并解决冲突完成之后,可以将代码上传到自己的仓库中,并发起 Pull Request。
参考链接
- 为复刻配置远程仓库
- 同步复刻
这篇关于GitHub 操作:同步 Fork 来的仓库(上游仓库)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






