fork专题

Linux进程初识:OS基础、fork函数创建进程、进程排队和进程状态讲解
目录 1、冯诺伊曼体系结构 问题一:为什么在体系结构中存在存储器(内存)? 存储单元总结: 问题二:为什么程序在运行的时候,必须把程序先加载到内存? 问题三:请解释,从你登录上qq开始和某位朋友聊天开始,数据的流动过程。 2、操作系统 2.1操作系统的概念: 我们首先要明白什么是管理: 2.2为什么要有操作系统? 2.3操作系统如何保证稳定和安全呢?(利用系统调用函数解决)

Linux的进程,线程以及调度(fork与僵尸,内存泄漏,task结构体,停止状态与作业控制)
1.Linux进程生命周期(就绪、运行、睡眠、停止、僵死) 2.僵尸是个什么鬼? 3.停止状态与作业控制,cpulimit 4.内存泄漏的真实含义 5.task_struct以及task_

程序员面试之nginx和apache的区别,nginx在开启时,会生成一个master进程,然后,master进程会fork多个worker子进程,最后每个用户的请求由worker的子线程处理。
Apache和Nginx最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程;而 nginx 是异步的,多个连接(万级别)可以对应一个进程。下面本篇文章就来给大家介绍一下Apache和Nginx的区别有那些,选择哪个好?希望对你们有所帮助。 AI:please wait...Nginx和Apache都是常用的Web服务器软件,它们在以下几个方面有一些区别:1. 架构和性能:N

java Fork/Join 框架的理解以及简单运用
Fork/Join 是一种并行计算模式,主要用于将任务分解为更小的子任务(Fork),递归地解决这些子任务,然后将结果合并(Join)以获得最终结果。这种模式非常适合于可以并行处理的任务,特别是那些可以分解为多个独立子问题的任务。 ### Fork/Join 框架的关键概念: 1. **任务(Task)**:表示可以执行的工作单元。在 Java 中,可以通过实现 `Callable` 接口来创
linux bash shell之递归函数:fork炸弹
所谓fork炸弹是一种恶意程序,它的内部是一个不断在fork进程的无限循环,fork炸弹并不需要有特别的权限即可对系统造成破坏。fork炸弹实质是一个简单的递归程序。由于程序是递归的,如果没有任何限制,这会导致这个简单的程序迅速耗尽系统里面的所有资源。下面是Jaromil设计的最简单的fork炸弹: :() { :|:& };: 或者是 .() { .|.& };. 这么一行只有13个字符

多个fork线程与主线程或其他的pthread线程通信的例子
最近在做一个项目,需要建立两个server,一个循环检测收到的数据发送到另一个server,但是由于fork新建的线程里面的全局变量都是副本,同时fork里面还有个阻塞的循环用于处理event,所以也不能用select的方式,同时用pthread出现了前后全局变量相互覆盖的情况,所以采取多线程相互fifo通信的方式解决问题:

进程创建:fork函数
fork函数 在Linux系统中,fork函数是用于创建一个新的进程的函数。调用fork函数会创建一个新的进程。 fork函数的原型如下: #include <unistd.h>pid_t fork(void); fork函数没有参数,返回值是一个pid_t类型的值。在成功创建新的进程后,fork函数会在父进程中返回子进程的PID,而在子进程中返回0。如果fork函数调用失败,则会返

Linux的进程详解(进程创建函数fork和vfork的区别,资源回收函数wait,进程的状态(孤儿进程,僵尸进程),加载进程函数popen)
目录 什么是进程 Linux下操作进程的相关命令 进程的状态(生老病死) 创建进程系统api介绍: fork() 父进程和子进程的区别 vfork() 进程的状态补充: 孤儿进程 僵尸进程 回收进程资源api介绍: wait() waitpid() exit() popen 什么是进程 一个程序是由源代码在编译后产生的,格式为ELF的,

Android 开源的真相: 无法fork
虽然是名义上的开源系统,但如果微软的手机采用 Android 系统,那将是个巨大的错误,诺基亚都不行,因为 Google 把 Android 做得无人可改。不止一次了,总有人跳出来「建议」微软采用 Android,替换掉市场乏力的 Windows Phone 系统。这种口水文章估计将来也不会停。 说这话的人到底是人笨呢,还是心眼坏。Google 这么多年来,已经把 Android 做成
![[8 进程控制]使用fork函数创建子进程](https://i-blog.csdnimg.cn/blog_migrate/d8cfb77b90c75cf7d0d59da7eba05e87.png)
[8 进程控制]使用fork函数创建子进程
1 C程序典型存储空间 先来看下进程的典型存储空间。 C程序一直由下列几部分组成: (1)正文段 这是由CPU执行的机器指令部分。通常,正文段是可共享的,在存储器中只需有一个副本。正文段也是只读的,以防止程序由于意外被修改。 (2)初始化数据段 如C程序中函数之外的声明: int maxcount = 99; (3)未初始化数据段 通常将此段称为bss段,即"由符号开始的段"(bloc
关于for循环中调用fork()系统调用的执行原理解析
关于for循环中调用fork()系统调用的执行原理解析_fan1570285527的博客-CSDN博客 关于for循环中调用fork()系统调用的执行原理解析 该问题来源于操作系统概念(第九版)一书中的第三章的习题3.5,分析for循环中fork的执行原理 1、预备知识 2、题目解析 3、剖析原理 4、结论和意外发现 4.1、结论: 4.2、意外发现 该问题来源于操作系统概念(第九版)一书中

Fork-Join框架的简单使用
一、Fork-Join框架作用 Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。Fork/Join框架要完成两件事情: 1.任务分割:首先Fork/Join框架需要把大的任务分割成足够小的子任务,如果子任务比较大的话还要对子任务进行继续分割 2.执行任务并合并结果:分割的子任务分别

如何用好GitHub中的Watch、Star和Fork
原文:http://www.jianshu.com/p/6c366b53ea41 在每个 github 项目的右上角,都有三个按钮,分别是 watch、star、fork,但是有些刚开始使用 github 的同学,可能对这三个按钮的使用却不怎么了解,包括一开始使用 github 的我也是如此,这篇博客,结合自己的理解和使用,说说这三个按钮的用法以及一些个人见解。 如下图所示这是我们经常看到的三
github的fork功能
http://help.github.com/fork-a-repo/ 概要: 克隆别人的代码库到自己的项目中,可以作为子模块的形式使用,或二次开发 操作流程: 在开源项目中点击fork按钮,稍等一会儿,该项目便会拷贝一份到你的respositories中, 克隆一份代码到本地:git clone git@github.com:username/Spoon-Knife.git 配
linux c 多进程fork基本用法及阻塞和非阻塞方式回收
一、基本用法 #include <stdio.h>#include <string.h>#include <errno.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>#include <iostream>using namespace std;/* 多进程的基本用法 */int ma
![[转]从一道面试题谈linux下fork的运行机制](https://pic.xiahunao.cn/getimgs/?img=http://pic002.cnblogs.com/img/leoo2sk/200912/2009121122511552.png)
[转]从一道面试题谈linux下fork的运行机制
原文:http://www.cnblogs.com/leoo2sk/archive/2009/12/11/talk-about-fork-in-linux.html 今天一位朋友去一个不错的外企面试linux开发职位,面试官出了一个如下的题目: 给出如下C程序,在linux下使用gcc编译: 1 2 3 4 5 6 7 8 9 10

fork()写时复制原理
fork()系统调用创建一个子进程,是父进程的一个副本,父子进程仅有pid的区别。 子进程拥有与父进程相同的进程虚拟地址空间,但如果在fork()时复制父进程的整个地址空间,虽然实现了创建副本的目的,但这种做法不太聪明,因为直接复制父进程的所有内存页是非常耗费资源的,特别是当父进程占用了大量内存时。 为了解决这个问题,操作系统使用了一种叫做 Copy-On-Write(写时复制) 的技术。
52.Fork Join线程池
介绍 jdk1.7之后加入的新的线程池的实现。 实现一种分治的思想。 适用于能够进行任务拆分的cpu密集型运算。 任务拆分 将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。例如跟递归相关的一些计算,如归并排序、斐波那契数列都可以利用分治的思想。 Fork/Join是在分治的思想上加了多线程。可以把每个任务的分解和合并交给不同的线程来完成。进一步提升了运算效率。 For
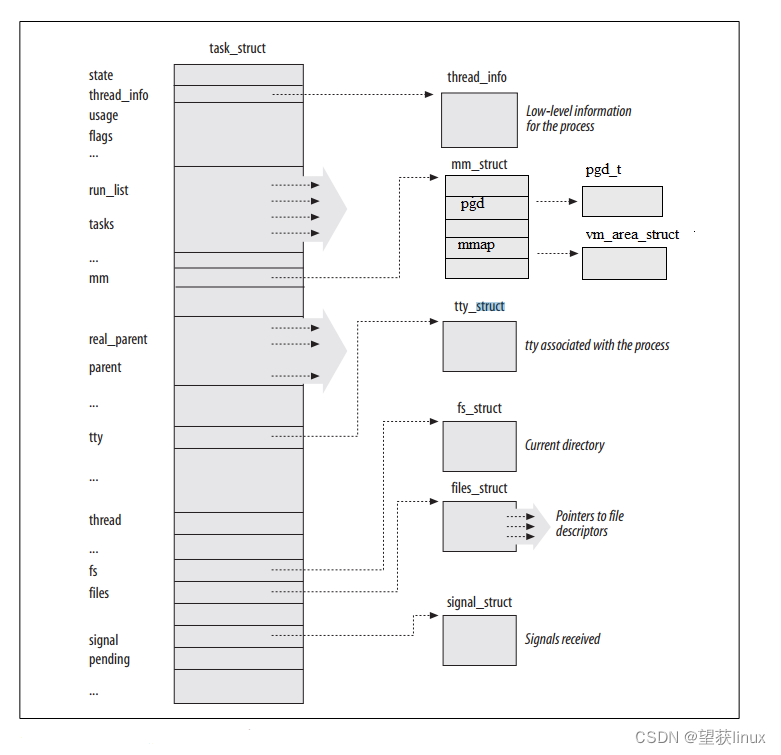
深度解析Linux内核中fork工作原理和实现
Linux内核中的fork()系统调用是用来创建新进程的核心机制。它的主要工作是为新创建的子进程复制当前进程(父进程)的数据结构和内存空间,从而产生一个几乎完全相同的副本。fork()的实现涉及到操作系统内核中许多重要部分的交互和协作,过程比较复杂。 fork()的基本原理 当一个进程调用fork()时,内核会为新创建的子进程分配必要的资源,如进程控制块(task_st
如何在gitlab上与fork的源代码保持同步(命令行)
如何在gitlab上与fork的源代码保持同步(命令行) 1.配置上游地址(只需要一次) git remote add upstream 你上游项目的地址 git remote add upstream https://gitlab.com/Brioal/QixiuProject.git 2.获取上游更新 git fetch upstream 3.合并到本地分支 git merg

《linux 内核完全剖析》 fork.c 代码分析笔记
fork.c 代码分析笔记 verifiy_area long last_pid=0; //全局变量,用来记录目前最大的pid数值void verify_area(void * addr,int size) // addr 是虚拟地址 ,size是需要写入的字节大小{unsigned long start;start = (unsigned long) addr; //把
Java-Fork/Join的简单例子
内容:借助网上的解释: 第一步分割任务。首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。 第二步执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。 public class