本文主要是介绍用python爬取网站_用Python抓取携程网机票信息 过程纪实(上篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
现在有一个需求,想查询一下给定出发地和目的地的机票数目,然后得到所需要的航班信息。不知道哪个网站比较好,于是用bing查了一下,搜索结果中第一个是携程在bing打的广告。
秉承着对bing搜索一贯的信任(^__^),我点开了携程机票查询的链接。
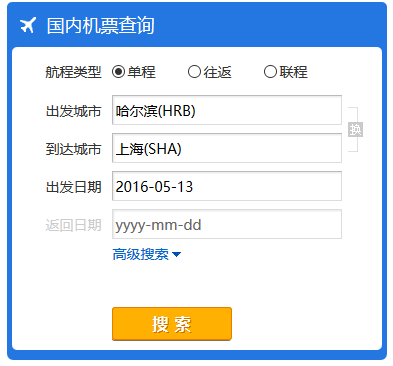
在上图的左侧查询版块选择出发城市和目的城市后点击搜索按钮,会跳转到另一个页面,如下图所示
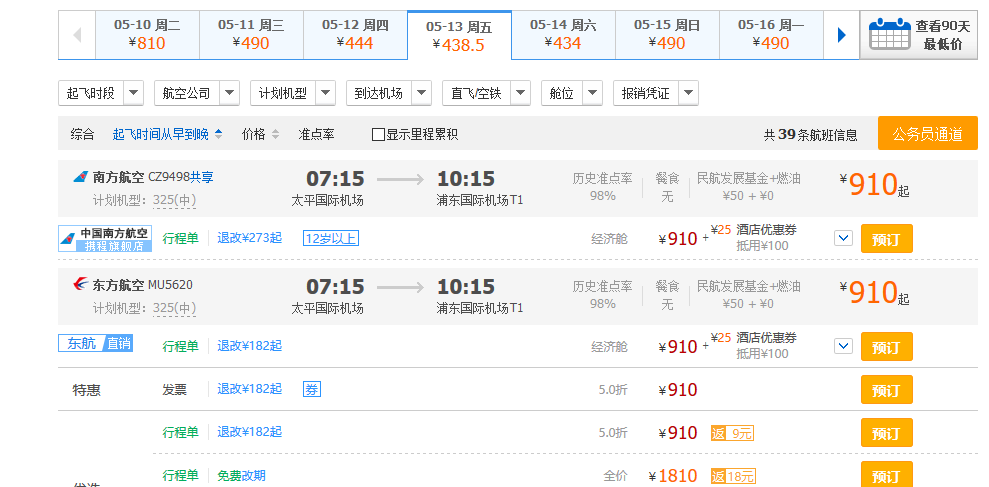
这个页面的显示结果正是我们所需要的,上面有航班的数目和相应的信息,那么如何获取呢?
页面分析
直接读取html文档吗?
显然不行,这个页面的显示用到了Ajax的异步调用,直接查询html文档是获取不到数据的。话说回来要是这么容易就获取到了还犯得着写个博客记录一下吗:-D
解析JavaScript代码?
没错,JavaScript代码是迟早要进行解析的,不过不是现在(事实上要留到下篇博客)。现在我们要做的是对后台处理过程有个大体的认识,例如数据的格式,信息访问,而且标题说了用Python,那么还要考虑到怎样用Python处理得到的数据,以上这些是本博客接下来要做的内容,至于其他内容将在下篇博客中讲到。
我用的PC机,firefox浏览器,直接F12打开开发工具,切换到网络选项卡,然后重新载入页面,接下来会看到如下图所示的结果
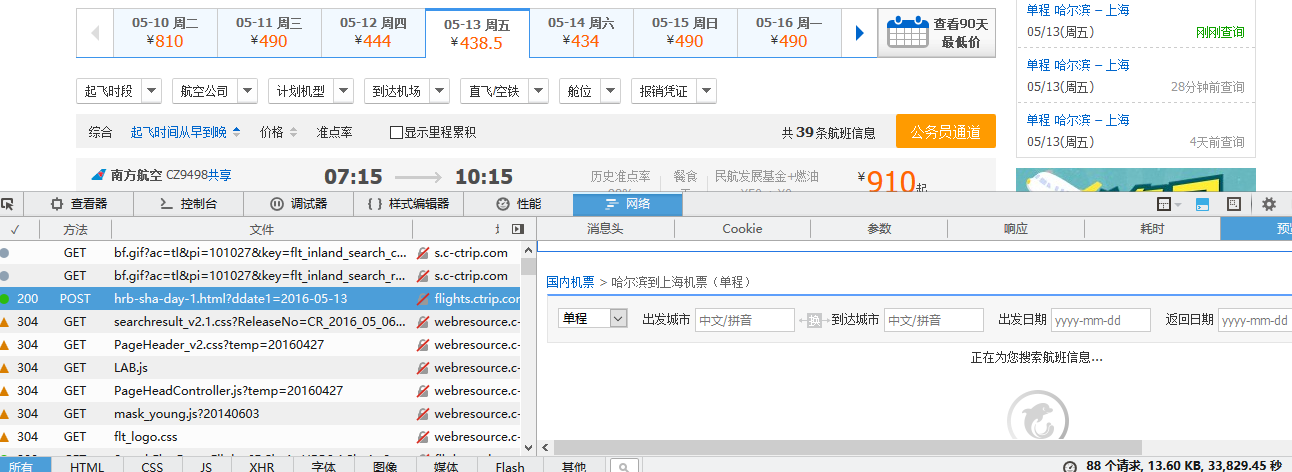
上面的图不用多介绍了,下面左侧显示的是网页加载过程中从服务器获取到的文件,右边是相应的内容信息。可以看到图中选中的文件是浏览器显示的主页面,然而这个主页面除了显示标题栏、菜单栏、页脚之外什么也没有,显然咱们要的信息不在这(想查看每个页面显示效果,在上图中先选中文件,然后在右侧选择“预览”选项,就可以看到页面的预览效果,上图右侧就是主页面的预览效果)。知道上面的技巧以后,就可以一边选择文件,一边预览页面,这样很快就可以定位到所需的网页文件。下图就是包含航班信息的网页文件
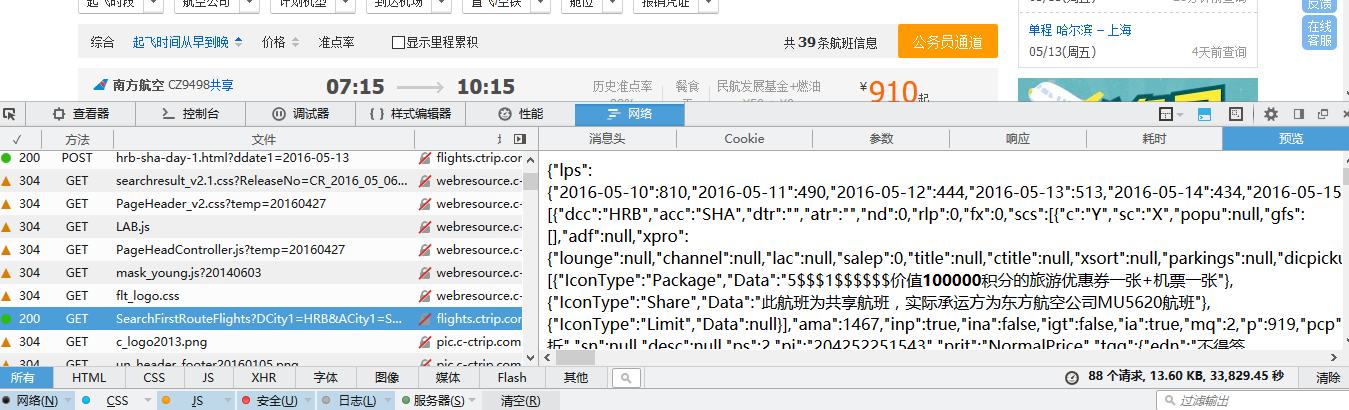
在右侧的预览中可以看到航班数据,不过格式不够直观,将其切换到“响应”选项卡,如下图,返回的数据是json格式。
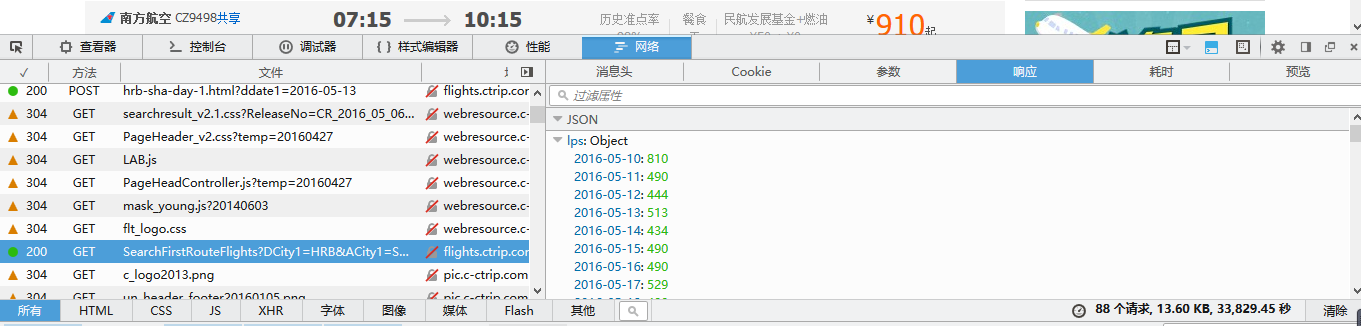
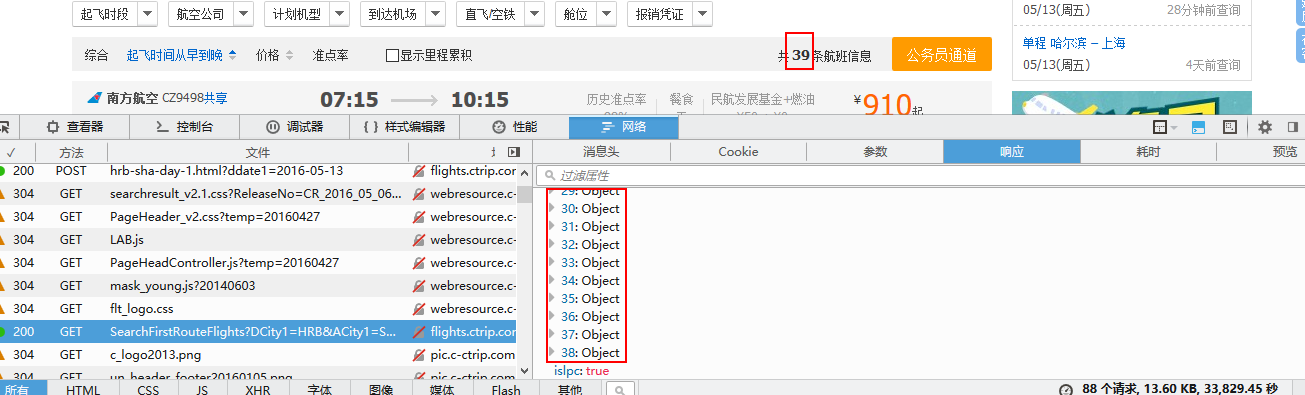
在json数据中有一个”fis”对应0~38共39个对象,对应网页中显示的39个航班信息,如下图所示
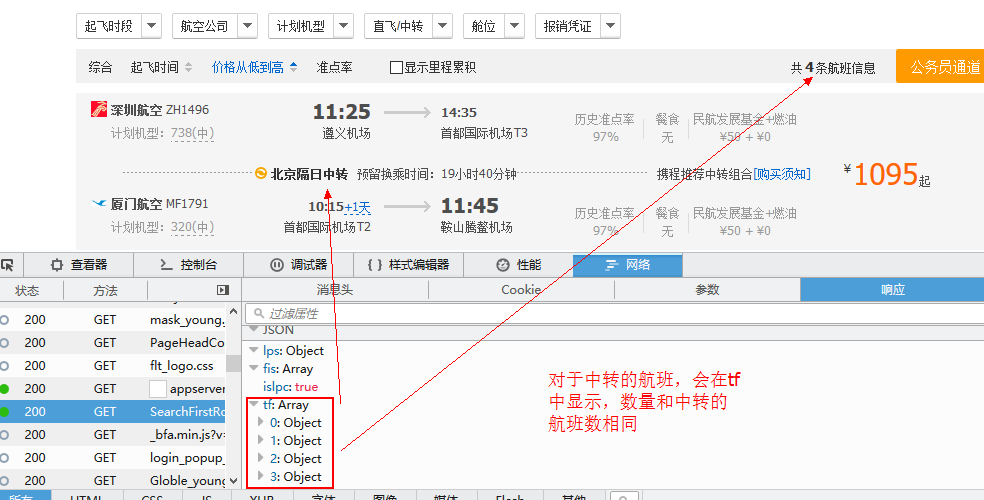
有些城市直接不存在直达的航班,而是需要中转换乘,这种航班信息显示在“tf”中,如下图所示
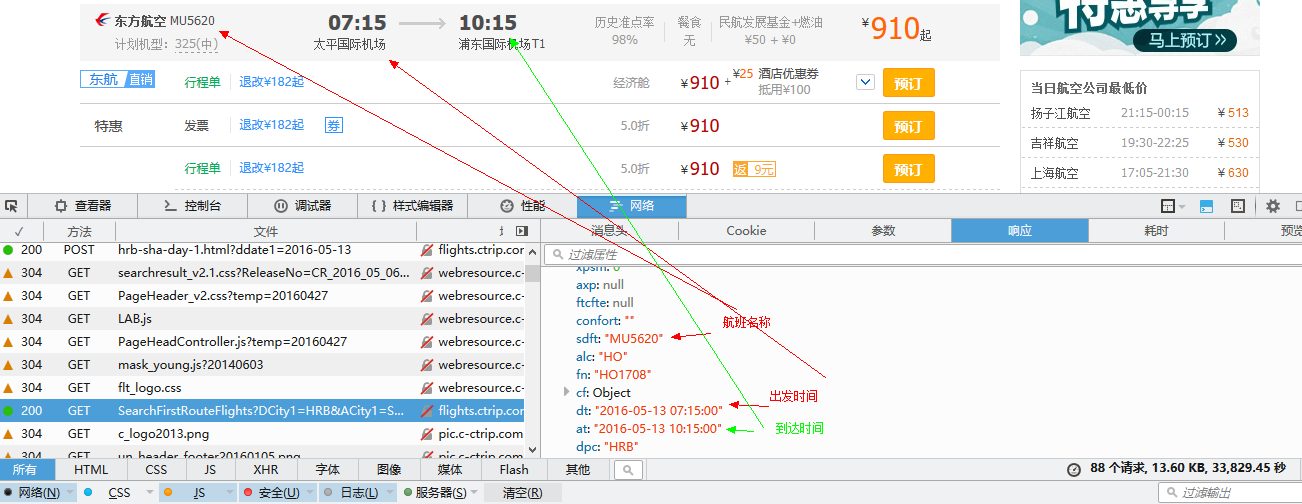
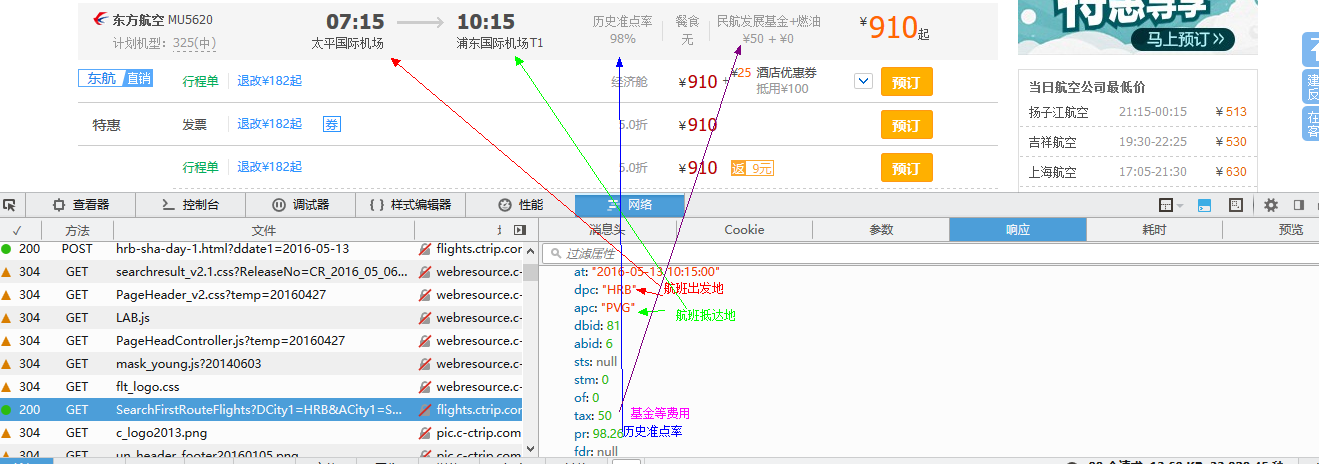
每个object里面包含该航班的具体信息,下图是打开第一个object看到的内容

里面包含了页面展示所涉及到的全部数据信息,下面是其中的一部分
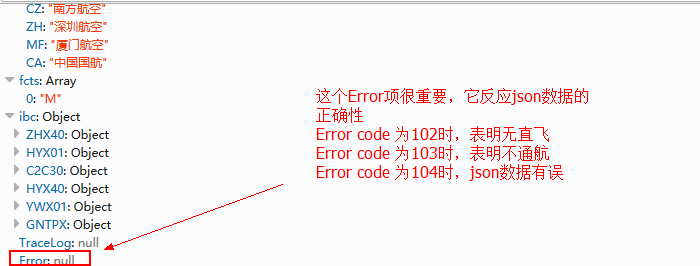
尤其需要留意的是json文件最下面的Error项,对于正常的json Eoor项是为null的,如果查询的城市之间无直飞航班,则Error 中会包含Code项,值为102;如果查询的两城市之间并不通航,则Error 中同样包含Code项,值为103;最糟糕的是Code值为104,它表明json数据是错的。如下图
编写爬虫
上面已经找到了包含数据的js代码,假如我们想要获取航班的数量信息(类似于上文的39)那么我们在Python中直接访问该url获取资源岂不美哉!然并卵,直接用是不行的。下面的示例代码完成对js对应url的访问,并对response页面进行了显示。
1
2
3
4
5
6
7
8
9
10
11import urllib2
def get_that():
url='http://flights.ctrip.com/domesticsearch/search/SearchFirstRouteFlights?DCity1=HRB&ACity1=SHA&SearchType=S&DDate1=2016-05-13&IsNearAirportRecommond=0&rk=5.189667156909168071745&CK=89D3A4A3A5F8A7F7E48ACDD1F451127A&r=0.1440474125154478474718'
response=urllib2.urlopen(url).read()
print response
if __name__=='__main__':
get_that()
运行结果
1{"lps":{},"fis":[],"islpc":true,"tf":null,"sf":null,"rflag":{"rn":false,"rt":false,"rht":false,"rtp":false,"fquery":true},"lp":0,"lcfp":0,"lr":0,"rpl":null,"icfnf":false,"al":[],"iaw":false,"atc":0,"abc":0,"hmat":false,"hmab":false,"pc":0,"latp":0,"latdt":"0001-01-01 00:00:00","gpl":null,"rlp":null,"rrc":0,"rtgt":null,"nnrr":0,"airfreq":null,"apb":{},"als":{},"fcts":[],"ibc":{},"TraceLog":null,"Error":{"Code":104,"Message":"","Data":""}}
没有得到我们想要的数据。error信息中错误代码为104,下篇博客会谈到这个104是怎么来的。从结果看携程的服务器对request的消息头进行了验证,贸然访问不行,那就需要伪装一下了。下面代码演示了用设置了请求头的request访问刚才的网址,然后将json格式转换成Python中的dict类型,并且将其中”fis”关键字对应的值的数目打印出来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14import urllib2
import json
def get_json():
url='http://flights.ctrip.com/domesticsearch/search/SearchFirstRouteFlights?DCity1=HRB&ACity1=SHA&SearchType=S&DDate1=2016-05-13&IsNearAirportRecommond=0&rk=5.189667156909168071745&CK=89D3A4A3A5F8A7F7E48ACDD1F451127A&r=0.1440474125154478474718'
headers={'Host':"flights.ctrip.com",'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0",'Referer':"http://flights.ctrip.com/booking/hrb-sha-day-1.html?ddate1=2016-05-13"}
req=urllib2.Request(url,headers=headers)
res=urllib2.urlopen(req)
content=res.read()
dict_content=json.loads(content,encoding="gb2312")
print len(dict_content['fis'])
if __name__=='__main__':
get_json()
上面代码中用到了urllib2模块和json模块,前者用于网络资源的访问,后者用于解析json格式。由于携程网网页的字符编码格式为gb-2312,所以掉用json的loads方法时需要指定字符集为gb-2312。下面是得到的结果
139
终于得到了我们想要的结果。这里就不对航班中的其他信息进行提取了,实际上提取的方式是一样的,通过将json格式转换为dict,访问其中的某个键值就变得很轻松了。
小结
至此,本文就告一段落了,本文主要谈到了如何快速定位到所需的js文件,以及构造headers,最后将json格式转换为dict格式方便对数据的操作。但问题到这里还没有结束,我们想要实现的是给定出发地、到达地和出发时间,得到航班数量,然而现在包含数据的js文件是手动设置的,作为一个爬虫,显然这里需要修改。观察url的格式,里面除了我们提供的出发城市(DCity)、目的城市(ACity)、单程(SearchType=S)、日期(DDate)和IsNearAirportRecommond之外,还有三个很重要的参数(rk、CK、r),想要构造出这三个参数,就需要看js代码了,下篇博客会详细介绍js代码中这三个参数的“前世今生”,一起探索吧!
这篇关于用python爬取网站_用Python抓取携程网机票信息 过程纪实(上篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







