本文主要是介绍MySQL 从一个表中查出数据并插入到另一个表处理方案(详细),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PS:来源表:t_source、目标表:t_target
第一种
来源表和目标表字段完全一致
insert into t_target select * from t_source;
第二种
来源表和目标表字段部分一致,只想导入来源表部分字段到目标表
insert into t_target(字段1,字段2,字段3, ...)
select 字段1,字段2,字段3, ... from t_source;
第三种
只需要导入目标表中不存在的数据
insert into t_target (字段1, 字段2, ...)
SELECT 字段1, 字段2, ... FROM t_source
WHERE not exists (select * from t_target
where t_target.比较字段 = t_source.比较字段);
下面是一个完整的示例,展示了如何将一张名为 source_table 的源表的数据更新到一张名为 target_table 的目标表:
-- 创建目标表
CREATE TABLE target_table (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT
);
-- 确定连接条件
ALTER TABLE target_table ADD COLUMN source_table_id INT;
UPDATE target_table
SET source_table_id = source_table.id
FROM target_table
INNER JOIN source_table
ON target_table.name = source_table.name;
-- 更新数据
UPDATE target_table
INNER JOIN source_table
ON target_table.source_table_id = source_table.id
SET target_table.age = source_table.age;
以上是一个简单的示例,你可以根据实际情况进行修改和扩展。
总结
通过以上步骤,我们可以将一张表的数据更新到另一张表。首先,我们需要创建一个目标表来接收数据,然后确定源表和目标表之间的连接条件,最后使用 UPDATE 语句将数据更新到目标表。
MySQL查询结果复制到新表的方法(更新、插入)
MySQL中可以将查询结果复制到另外的一张表中,复制的话通常有两种情况,一种是更新已有的数据,另一种是插入一条新记录。下面通过例子来说明。首先构建两个测试表。
表t1:
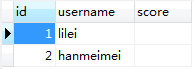
表t2:
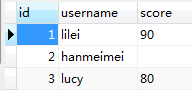
1、如果t2表中存在score值,将score更新到t1表中。方法如下:
UPDATE t1,t2
SET t1.score = t2.score
WHERE t1.id = t2.id AND t2.score IS NOT NULL
这就是将查询结果作为条件更新另一张表,当然,t2也可以是更为复杂的一个查询结果而不是一个具体的表。
2、将t1表的username更新至t2表,将t2表的score更新至t1表。方法如下:
UPDATE t1,t2
SET t1.score = t2.score,t2.username = t1.username
WHERE t1.id = t2.id
这个方法其实跟上面的方法类似,可以同时更新两个表的数据,即做表部分数据的互相复制、更新。
3、将t2表的查询结果插入到t1表中。方法如下:
INSERT INTO t1(id,username,score)
SELECT t2.id,t2.username,t2.score FROM t2 where t2.username = 'lucy'
前面两种方式是更新表的记录,这种方式是插入一条新的记录。其实,从脚本可以看出,这个方法就是将查询和插入两个步骤合二为一。
用一个表更新另一个表
1、更新一个字段
方法一
update table1 set field1=table2.field1 from table2
where table1.id=table2.id
方法二
将两张表以内连接的方式进行查询更新
UPDATE tableName1 t1
LEFT JOIN tableName2 t2 ON t2.id = t1.id
SET t1.lpEntityType2 = t2.lpEntityType2
方法三
update A m,B mp set m.job_type = mp.job_type where mp.mobile= m.mobile;
2、更新多个字段
方法一
update B, A
set
B.username = A.username,
B.phone = A.phone
where
B.userId = A.userId
方法二
将两张表以内连接的方式进行查询更新
update
B join A on B.userId=A.userId
set
B.username = A.username,
B.phone = A.phone
MYSQL 更新一个表字段为另外一张表字段
1、UPDATE m_node_device mnd SET mnd.enterprise_id = (SELECT md.enterprise_id FROM m_device md WHERE mnd.device_id = md.id)
2、-- 更新表字段为查询结果中的某一个字段
UPDATE m_device md,
(
SELECT
mi.img_url AS aa,
mi.device_id AS bb
FROM
m_device_img mi
INNER JOIN m_device_type_attr ma ON ma.id = mi.device_type_attr_id
WHERE
ma.attr_name = '设备铭牌'
) b
SET md.nameplate_img = b.aa
WHERE
md.id = b.bb
AND md.nameplate_img = '' and md.is_deleted = 0
这篇关于MySQL 从一个表中查出数据并插入到另一个表处理方案(详细)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






