本文主要是介绍史上最全,万字吃透python正则匹配,让你在网络爬虫中自由翱翔,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们已经可以使用 Requests 库对网站内容进行抓取了,对于一般的图片数据, 音频数据,视频数据等数据我们可以直接通过 Requests 库对其资源的 URL 进行直接请求,但是通常情况下这些数据的 URL 都是存在于 HTML 页面当中,如何从这些 HTML 页面中提取出我们想要的数据呢,这时候就需要使用一些工具了,这里我们先介绍第一种从网页中解析数据的方法, 使用正则表达式提取。
需要注意的是 , 正则表达式并不是 Python 的一部分。正则表达式是用于处理字符串的强大工 具,拥有自己独特的语法以及一个独立的处理弓擎,效率上可能不如 str 自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果巳经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。就个人而言, 主要用它来做一些复杂字符串分析,提取想要的信息,学习原则:够用就行,需要的时候在深入!
1 正则表达式
正则表达式就是用某种模式去匹配一类字符串的公式,主要用来描述字符串匹配的工具。一 句话正则表达式( Regular expression )是一组由字母和符号组成的特殊文本 , 它可以用来从文中找出满足你想要的格式的句子。
在正则表达式中,匹配是最常用的一个词语,它描述了正则表达式动作结果。给定一段文本 或字符串,使用正则表达式从文本或字符串中查找出符合正则表达式的字符串。有可能文本或字符存在不止一个部分满足给定的正则表达式,这时每一个这样的部分被称为一个匹配。
1.1 正则表达式可以做什么?
正则表达式在程序设计语言中存在着广泛的应用,特别是用来处理字符串。如匹配字符串、 查找字符串、替换字符串等。可以说,正则表达式是一段文本或一个公式,它是用来描述用某种模式去匹配一类字符串的公式,并且该公式具有一定的模式。正则表达式就是用某种模式去匹配一类字符串的公式,主要用来描述字符串匹配的工具。
❖ 验证字符串 ,即验证给定的字符串或子字符串是否符合指定特征,譬如验证是否是合法的 邮件地址、验证是否为合法的 HTTP 地址等
❖ 查找字符串 ,从给定的文本中查找符合指定特征的字符串,比查找回定字符串更加灵活方 便
❖ 替换字符串 ,即把给定的字符串中的符合指定特征的子字符串替换为其他字符串,比普通 的替换更强大
❖ 提取字符串 ,即从给定的字符串中提取符合指定特征的子字符串
1.2 正则表达式基础 * 元字符
学习正则表达式语法,主要就是学习元字符以及它们在正则表达式上下文中的行为。元字符
包括:普通字符、标准字符、特殊字符、限定字符 ( 又叫量词 ) 、定位字符 ( 也叫边界字符 ) 。下面
分别介绍不同元字符的用法。
元字符是正则表达式最核心和基本的概念,我们必须要记住的是下面这些个元字符,下表是
相关元字符的写法和说明:
表 5.1: 常见元字符

表 5.2: 常用的反义代码 
表 5.3: 常见空白元字符
笔记: 注意用来匹配退格字符的 [\b] 元字符是一个特例:它不在类元字符 \s 的覆盖范围内,当然也就没有被排除在类元字符\S 的最盖范围外。一般很少用 ! 量词符用来设定某个模式出现的次数。属于必须要会的内容
表 5.4: 量词 ( 常用限定符 )

1.3 正则表达式 * 贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b ,它将会匹配最长的以 a 开始,以 b 结束的字符串。如果用它来搜索 aabab 的话,它会匹配整个字符串 aabab 。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号? 。这样 .*? 就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b 匹配最短的,以 a 开始,以 b 结束的字符串。如果把它应用于 aabab 的话,它会匹配 aab(第一到第三个字符)和 ab (第四到第五个字符)。
表 5.5: 贪婪与懒惰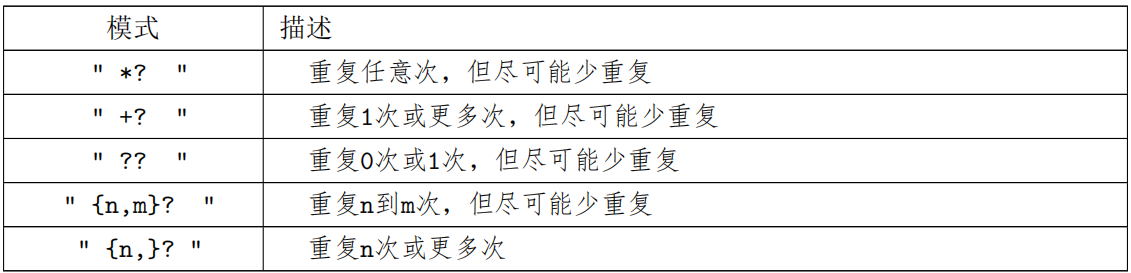
1.4 正则表达式 * 分支条件与分组
正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配, 具体方法是用 | 把不同的规则分隔开。听不明白?没关系,看例子:
0\d{2}-\d{8} 03-7| 这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号, 8 位本地号 ( 如 010-12345678) ,一种是 4 位区号, 7 位本地号 (0376-2233445) 。
分组是正则表达式的一项功能 , 我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?你可以用小括号来指定子表达式 ( 也叫做分组) ,然后你就可以指定这个子表达式的重复次数了 . 可以理解为被小括号包含的子表达式就是一 个分组, 当然也可以进行其他操作。
分组语法:
❖ (exp) :匹配 exp, 并 捕获 文本到自动命名的组里
❖ (?<name>exp) : 匹配 exp, 并捕获文本到名称为 name 的组里 , 也可以写成 (?’name’exp)
❖ (?:exp) : 匹配 exp, 不捕获匹配的文本
❖ (?#comment) : 这种类型的组不对正则表达式的处理产生任何影响,只是为了提供让人阅读注释
1.5 正则表达式 * 后项引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为 1 ,第二个为 2 ,以此类推。
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1 代表分组 1 匹配的文本。难以理解?请看示例:\b(\w+)\b\s+\1\b 可以用来匹配重复的单词,像 go go, kitty kitty 。首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b) ,然后是 1 个或几个空白符(\s+) ,最后是前面匹配的那个单词 (\1) 。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:
(?<Word>\w+)( 或者把尖括号换成 ’ 也行: (?’Word’\w+)) , 这样就把 \w+ 的组名指定为 Word 了。要反向引用这个分组捕获的内容,你可以使用\k<Word> , 所以上一个例子也可以写成这样: \b(?<Word>\w+)\b\s+\k<Word>\b。
1.6 正则表达式 * 零宽断言
零宽断言是正则表达式的一种方法,用于查找在某些内容 ( 但并不包括这些内容 ) 之前或者之后的东西,也就是说他们像\b ( 匹配一个单词边界,也就是单词和空格间的位置,正则表达式的匹配有两种概念,一种是匹配字符,一种是匹配位置,这里的\b 就是匹配位置,例如, " er\b " 可以匹配"never" 中的 "er" ,但不能匹配 "verb" 中的 "er") , ˆ( 匹配输入字行首 ) , $ ( 匹配输入字行尾 ) 那样用于指定一个位置,这个位置应该满足一定的条件 ( 即断言 ) ,因此它们也被称为零宽断言。断言用来声明一个应该为真的事实,正则表达式中只有当断言为真时才会继续进行匹配。
位置指定:
❖ 零宽先行断言 (?=exp) :匹配文本中的某些位置 , 这些位置的后面能匹配给定的后缀 exp 。
比如\b\w+(?=ing\b) ,匹配以 ing 结尾的单词的前面部分 ( 除了 ing 以外的部分 ) ,
如果在查找 I’m singing while you’re dancing. 时,它会匹配 sing 和 danc 。
❖ 零宽后行断言 (?<=exp) :匹配某些位置 , 该位置的前面能给定的前缀匹配 exp
比如(?<=\bre)\w+\b 会匹配以 re 开头的单词的后半部分 ( 除了 re 以外的部分 ) ,
例如在查找 reading a book 时,它匹配 ading。
❖ 零宽负向先行断言 (?!exp) : 匹配后面跟的不是 exp 的位置
\d{3}(?!\d) 匹配三位数字,而且这三位数字的后面不能是数字。
❖ 零宽负向后行断言 (?<!exp) : 匹配前面不是 exp 的位置
(?<![a-z])\d{7} 匹配前面不是小写字母的七位数字
2 Python 中的 Re 模块
使用 re 的步骤为:先将正则表达式的字符串形式编译为 Pattern 实例;然后使用 Pattern 实例处理文本并获得匹配结果(一个 Match 实例);最后使用 Match 实例获得信息,进行其他的操作。
re 模块中常用的方法及其说明如下。
re 模块常用方法:
❖ compile 将正则表达式的字符串转化为 Pattern 匹配对象
❖ match 将输入的字符串从头开始对输入的正则表达式进行匹配,一直向后直至遇到无法
匹配的字符或到达字符串末尾,将立即返回 None ,否则获取匹配结果
❖ search 将输入的字符串整个扫描,对输入的正则表达式进行匹配,获取匹配结果,否则输 出 None
❖ spilt 按照能够匹配的字符串作为分隔符,将字符串分割后返回一个列表
❖ fifindall 搜索整个字符串,返回一个列表包含全部能匹配的子串
❖ fifinditer 与 fifindall 方法作用类似,以迭代器的形式返回结果
❖ sub 使用指定内容替换字符串中匹配的每一个子串内容
2.1 re.compile 方法
re 模块中使用 compile 方法将正则表达式的字符串转化为 Pattern 匹配对象, compile 方法的语法格式如下。
re . compile ( string [ , flag ] )compile 方 法 常 用 的 参 数 及 其 说 明 如 下 。 :string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 ,如 re.I | re.M 。 默 认 为 None
flflag 参数的可选值如下
re.I 忽略大小写re.M 多行模式,改变“ˆ”和“ $ ”的行为re.S “ .”任意匹配模式,改变“.”的行为re.L 使预定字符类 \w\W\b\B\s\S 取决与当前区域设定re.U 使预定字符类 \w\W\b\B\s\S\d\D 取决于 unicode 定义的字符属性re.X 详细模式,该模式下正则表达式可为多行,忽略空白字符并可加入注释
关于 re 模块的常量、函数、异常我们都讲解完毕,但是完全有必要再讲讲正则对象 Pattern 。在 re 模块的函数中有一个重要的函数 compile 函数,这个函数可以预编译返回一个正则对象,此正则对象拥有与 re 模块相同的函数 . 既然是一致的,那到底该用 re 模块还是正则对象 Pattern ? 其实 compile 函数与其他 re 函数 (search 、 split 、 sub 等等 ) 内部调用的是同一个函数,最终还是调用正则对象的函数!也就是说下面两种代码写法底层实现其实是一致的:
笔记 re 函数 re.search(pattern, text)
正则对象函数 compile = re.compile(pattern) compile.search(text)
那还有必要使用 compile 函数得到正则对象再去调用 search 函数吗?直接调用 re.search 是不是就可以?
官方文档推荐:在多次使用某个正则表达式时推荐使用正则对象 Pattern 以增加复用性,因 为通过 re.compile(pattern) 编译后的模块级函数会被缓存!
这是超链接,点击跳转 Python 正则表达式 , 这一篇就够了 !- 慕课网的文章-知乎
2.2 re.search 方法
Search 方法将输入的字符串整个扫描,对输入的正则表达式进行匹配,若无可匹配字符,将立即返回 None ,否则获取匹配结果, search 方法的语法格式如下。
re . search ( pattern , string [ , flags ] )pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 ,如 re.I | re.M 。 默 认 为 None
2.3 re.match & re.fullmatch
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话, match() 就返回 None 。
re . match ( pattern , string , flags = 0)pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 ,如 re.I | re.M 。 默 认 为 None
re.fullmatch 方法将输入的字符串整个扫描,对输入的正则表达式进行匹配,如果整个字符串与此正则表达式匹配,将立即返回 None ,则获取匹配结果 , 否则返回 None , re.fullmatch 方法的语法格式如下。
re . fullmatch ( pattern , string [ , flags ] )pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值 flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 ,如 re.I|re.M 。 默 认 为 None
2.4 search,match,fullmatch 区别
#Python Code:
import re
strs = 'sHello World Hello World'
print(f"search方法: {re.search('Hello',strs)}")
print(f"match方法: {re.match('Hello',strs)}")
print(f"match方法: {re.match('sHello',strs)}")
print(f"fullmatch方法: {re.fullmatch(’Hello’,strs)}")
print(f"fullmatch方法: {re.fullmatch('sHello World Hello World',strs)}")笔记 search 函数是在字符串中任意位置匹配,只要有符合正则表达式的字符串就匹配成功,其实有两个匹配项,但 search 函数值返回一个。而 match 函数是要从头开始匹配,而字符串开头多了个字母 s ,所以无法匹配 fullmatch 函数需要完全相同,故也不匹配!
2.5 re.fifindall 方法
fifindall 方法搜索整个 string ,返回一个列表包含全部能匹配的子串,其语法格式如下。
re . findall ( pattern , string [ , flags ] )pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值flags : 接收 string。表示匹配模式,取值为运算符 “ | ” 时表示同时生效 ,如 re.I | re.M 。默认为 None
2.6 re.fifinditer 方法
fifinditer 返回 string 中所有与 pattern 相匹配的全部字串,返回形式为迭代器。其语法格式如 下。
re . finditer ( pattern , string [ , flags ] )pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 ,如 re .I | re . M 。 默 认 为 None
fifindall 与 fifinditer 区别:
fifindall :从字符串任意位置查找,返回一个列表
fifinditer :从字符串任意位置查找,返回一个迭代器
两个方法基本类似,只不过一个是返回列表,一个是返回迭代器。我们知道列表是一次性生成在内存中,而迭代器是需要使用时一点一点生成出来的,内存使用更优。
如果可能存在大量的匹配项的话,建议使用 fifinditer 函数,一般情况使用 fifindall 函数基本没啥影响。
2.7 re.split 方法
re.split 方法用 pattern 分开 string,maxsplit 表示最多进行分割次数, flflags 表示模式,就是上面我们讲解的常量!
re . split ( pattern , string , maxsplit = 0 , flags = 0)pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 ,如 re .I | re . M 。 默 认 为 None
str 模块也有一个 split 函数,那这两个函数该怎么选呢? str.split 函数功能简单,不支持正则分割,而 re.split 支持正则。在不需要正则支持且数据量和数次不多的情况下使用 str.split 函数更合适,反之则使用 re.split 函数。
2.8 re.sub 方法 & re.subn() 方法
re.sub() 方法 :repl 替换掉 string 中被 pattern 匹配的字符, count 表示最大替换次数, flflags 表示正则表达式的常量。
re . sub ( pattern , repl , string , count = 0 , flags = 0)pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值count 表 示 最 大 替 换 次 数flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 ,如 re .I | re . M 。 默 认 为 None
re.subn() 方法 : 函数与 re.sub 函数功能一致,只不过返回一个元组 ( 字符串 , 替换次数 ).
re . subn ( pattern , repl , string , count = 0 , flags = 0)pattern : 接 收 Pattern 实 例 。 表 示 转 换 后 的 正 则 表 达 式 。 无 默 认 值string : 接 收 string 。 表 示 输 入 的 需 要 匹 配 的 字 符 串 。 无 默 认 值count 表 示 最 大 替 换 次 数flags : 接 收 string 。 表 示 匹 配 模 式 , 取 值 为 运 算 符 “ | ” 时 表 示 同 时 生 效 , 如 re .I | re . M 。 默 认 为 None
2.9 其他方法
❖ re.escape(pattern) 可以转义正则表达式中具有特殊含义的字符
re.escape(pattern) 看似非常好用省去了我们自己加转义,但是使用它很容易出现转义错误的 问题,所以并不建议使用它转义,而建议大家自己手动转义!
❖ re.purge() 正则表达式缓存,
❖ group() :要么返回整个匹配对象,要么根据要求返回特定子组;如果 group() 没有子组要求, 返回整个匹配。
❖ groups() :以 tuple 格式返回所有匹配子组。
#Python Code:
import re
s = "123dyalnABC"
print(re.search("([0-9]*)([a-z]*)([A-Z]*)",s).group())
#返回123dyalnABC
print(re.search("([0-9]*)([a-z]*)([A-Z]*)",s).group(0)) #返回123dyalnABC
print(re.search("([0-9]*)([a-z]*)([A-Z]*)",s).group(1)) #返回123
print(re.search("([0-9]*)([a-z]*)([A-Z]*)",s).group(2)) #返回dylan
print(re.search("([0-9]*)([a-z]*)([A-Z]*)",s).group(3)) #返回ABC由此可以看出,group() 是按照特定子组数字---小写字母---大写字母来获取字符串的, 对应关系是 group(1) 对应正则表达式对象的特定子组 1,group(2) 对应特定子组 2,group(3) 对应特定子组 3...... 一般地,s.group(N) 返回正则表达式对象的第 N 组特定子组。group(0) 同 group() 一样,对应整个正则表达式对象。
Python Code:
import re
s = "123dyalnABC"
print(re.search("([0-9]*)([a-z]*)([A-Z]*)",s).groups())
#返回('123', 'dyaln', 'ABC')3 正则表达式爬取猫眼电影
点赞过百更新正则匹配实践,爬取猫眼电影,冲啊,奥利给!!!
这篇关于史上最全,万字吃透python正则匹配,让你在网络爬虫中自由翱翔的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






