本文主要是介绍⚽ 使用 KNIME 分析足球比赛数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视觉分析足球比赛数据的成功传球可以提供有价值的信息,帮助教练和球队经理制定明智的改进决策,以提升球队表现。
如何通过使用 KNIME 分析传球数据来提升足球球队的表现?
原始数据
我们拥有一组记录曼联和曼城足球比赛期间各种类型传球数据的原始数据。数据示例如下:
id minute second teamId h_a type outcomeType x y endX endY
2.390970831E9 16 50.0 ManchesterUnited a Pass Unsuccessful 28.5 10.3 28.5 13.5
2.390970839E9 16 51.0 ManchesterCity h BallRecovery Successful 67.2 86.6 ? ?
2.390970881E9 16 52.0 ManchesterCity h Pass Successful 65.9 84.7 74.1 71.7
2.390970893E9 16 54.0 ManchesterUnited a Challenge Unsuccessful 22.4 27.4 ? ?
2.390970935E9 16 54.0 ManchesterCity h TakeOn Successful 77.6 72.6 ? ?
2.390970939E9 16 56.0 ManchesterCity h SavedShot Successful 92.7 67.6 ? ?
2.390970929E9 16 56.0 ManchesterUnited a Save Successful 2.0 46.4 ? ?
2.390971023E9 16 58.0 ManchesterUnited a Foul Successful 8.1 46.8 ? ?
字段说明:
-
id:每个事件的唯一标识符。可能是通过自动视频分析获得的编号。 -
minute, second:该足球事件发生的时间。 -
teamId:比赛双方的名字,分别是曼城和曼联队。 -
h_a:表示事件是在主场还是客场发生。使用主场或客场信息,可以了解球队的表现是否因比赛场地而异。 -
type:描述事件类型的列,例如传球、射门、进球等。type 列告诉我们比赛过程中发生了什么。 -
outcomeType:表示 type 列中提到的特定事件的结果是成功还是失败。 -
x, y:提供事件开始时在球场上的位置的坐标。 -
endX, endY:表示事件发生后球所去位置的坐标。例如,如果事件是传球 pass,该字段将提供接球者的位置坐标。
分析师可以通过检查比赛的类型、结果和位置,深入了解球队的整体战略和球员的个人表现。从该数据集中可以提取的一些见解包括:识别主要带球向前的球员、跨场地不同部分移动球的速度以及每支球队更倾向于在比赛中注重哪一侧的球场。此外,我们还可以将单个比赛的数据堆叠到更大的数据集中,并使用它来深入了解球队在一段时间内的表现。为了达到这个目的,需要对数据进行细致的整理和分析,以揭示隐藏在其中的价值。
足球数据事件类型 type
虽然我们最终只分析了传球数据,但我们可以先大致浏览一下原始数据中还包括哪些事件类型,以便于以后可能的进一步探讨。总共有近三十种不同类型的足球数据事件类型,下面列举其中几种以供参考:
Pass 传球
传球是足球比赛中最为基础和常见的动作之一。它是指球员通过踢球将球传给队友,从而实现进攻和控制比赛的方式。传球类型用于记录球员在比赛中完成传球的次数。在足球比赛中,传球的精准度和速度对球队的进攻质量和比赛节奏有着重要的影响。
Punch 拳击球
拳击球是守门员在比赛中使用拳头进行的一种扑救方式,用于将球从危险区域解救出来。出拳类型用于跟踪守门员在比赛中使用这种扑救方式的次数。在足球比赛中,守门员的拳击球技术和判断能力对于保护球门和防止进球是至关重要的。
Aerial 空中球
空中球是一种用于衡量球员赢得高空球或空中球次数的足球数据。无论是在比赛中的角球、任意球、球门球期间还是在常规的比赛中,赢得空中对抗的能力都是现代足球的重要技能之一。特别是在中后卫或防守型中场等防守位置上,头球技术和空中占领力是球员必备的技能之一。球员的空中占领力和头球技术对于反击和防守定位球都有着重要的影响。
BallTouch 触球
触球数据用于分析球员在比赛中参与进攻和控制比赛的效率。球员越是经常触球,通常就越是球队进攻的组织者和核心。触球数据记录每位球员在比赛中触球的次数和频率,它可以帮助教练和分析师更好地理解球员的角色和贡献。
BlockedPass 封堵传球
成功的封堵传球是防守球员阻止对方进攻的关键。BlockedPass 数据用于记录防守球员在比赛中成功封堵对方传球的次数。这个数据特征对于分析防守球员的表现和情况非常有价值,并且可以帮助教练和球队制定更好的防守策略。
Card 红牌或黄牌警告
Card是记录球员在比赛中得到的罚牌(红牌或黄牌)的数据特征。黄牌或红牌的数量可以反映球员的纪律和体育精神等方面的情况。大量的黄牌或红牌通常会影响球队的比赛表现和成绩,因此需要教练和球员合理管理情绪和比赛状态。
Tackle 抢断
Tackle是指球员从对手手中夺回球权的一种方式。足球数据中的Tackle类型记录球员尝试通过滑铲或站立铲球等方式从对手手中夺回球权的次数。成功的Tackle可以扰乱对手的进攻并且开启球队的反击,同时也可以提高球队的防守效率。需要注意的是,Tackle的危险性较高,如果时间不当或用力过大可能会导致违规,进而吃到黄牌或红牌。因此,球员需要在比赛中合理运用 Tackle 技巧。
好了,动手吧
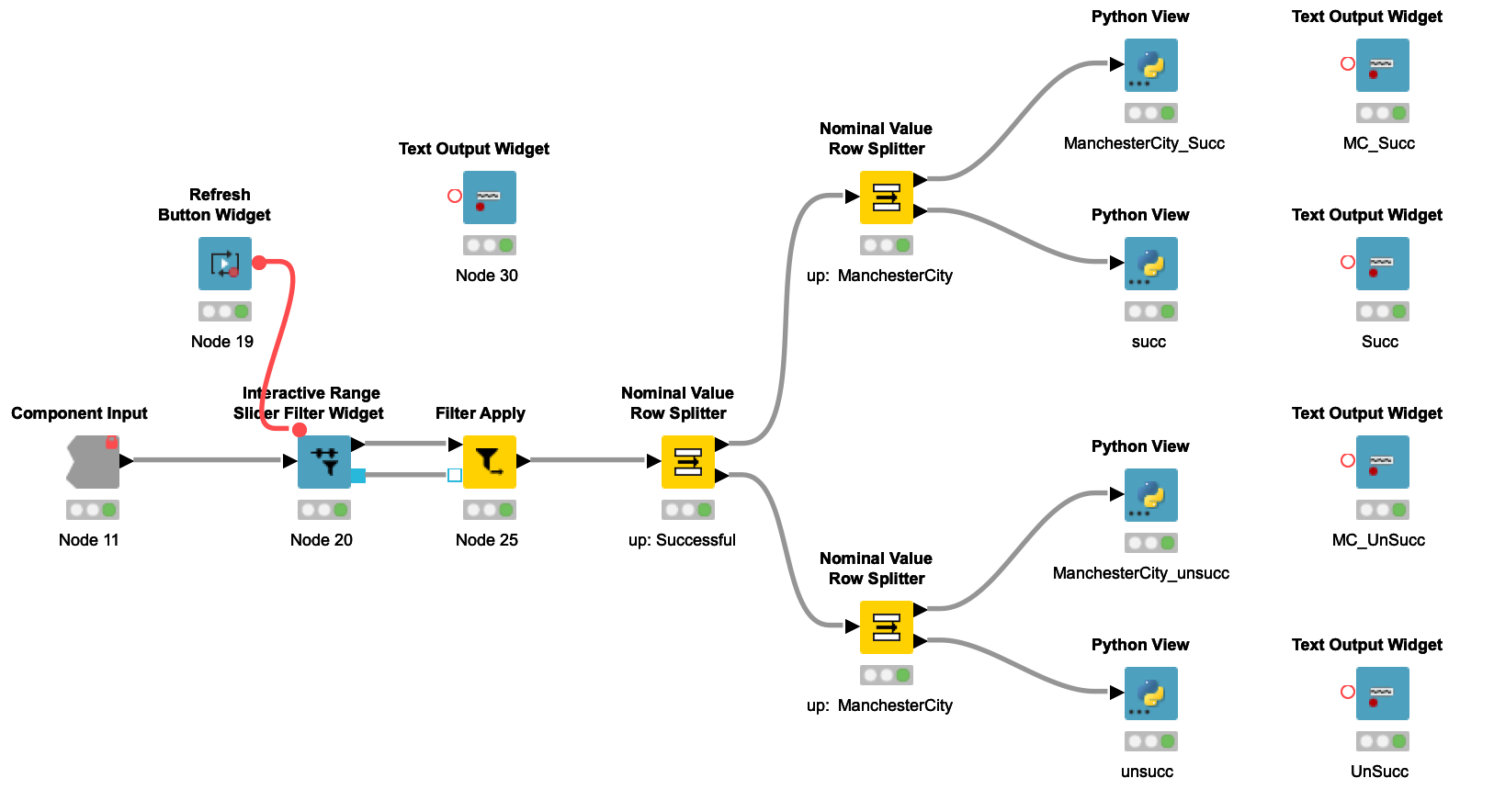
我们只分析传球数据,即 pass 类型。具体步骤如下:
-
读取数据并过滤出 pass 类型的数据。 -
通过使用 slider 控件,可选择时间段进行分析。 -
将成功和失败的传球数据分开以便进行比较。 -
将两个队伍的传球数据分开,以便于分析和对比。 -
使用 Matplotlib 可视化数据。

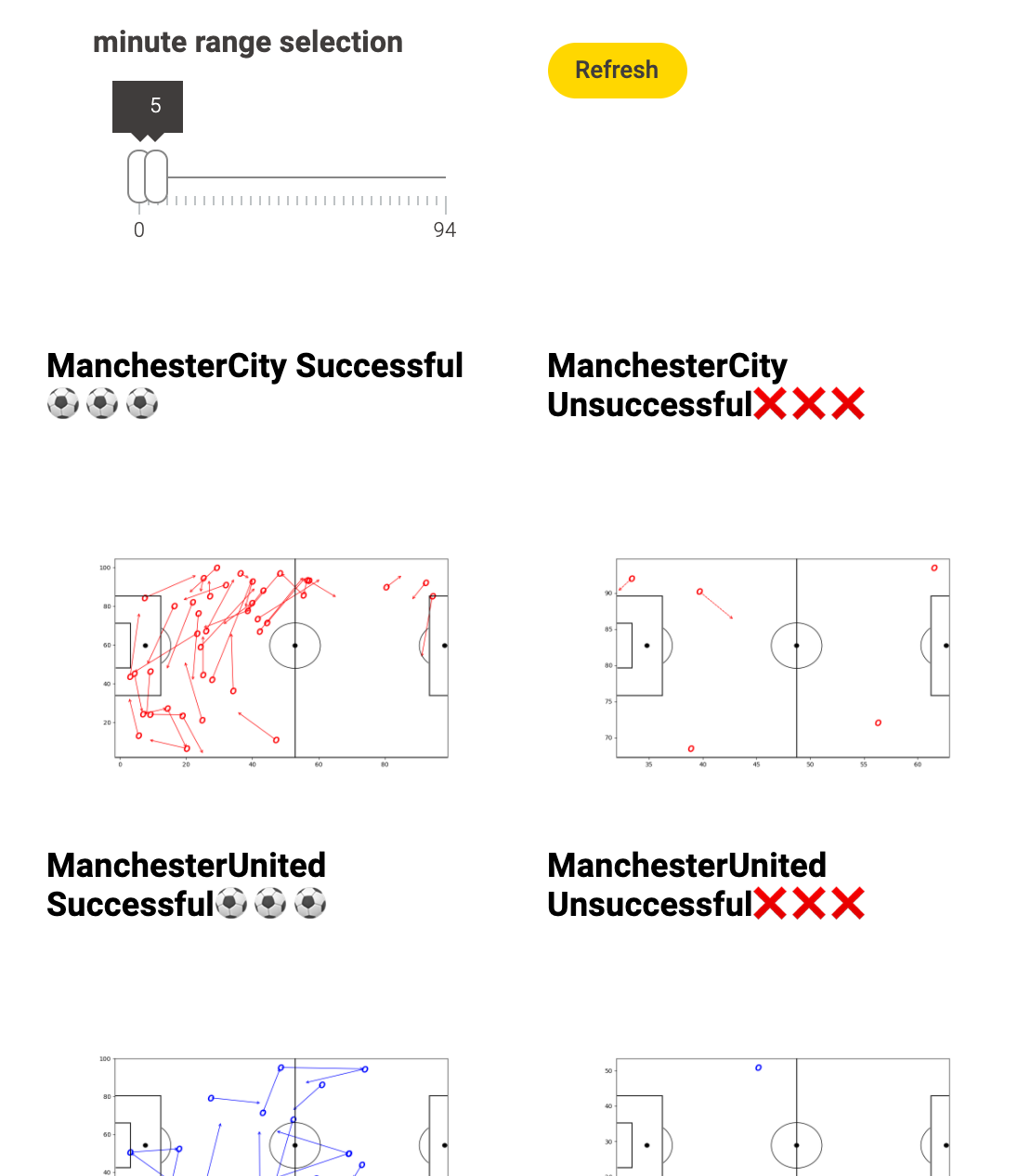
在可视化数据中,我们可以看出曼城队在比赛开始的5分钟内只在后场传球。同时,通过曼联的传球数据我们也可以看出他们采取了一种压迫性的打法,导致曼城队不得不在后场倒脚。
除此之外,我们还可以看出一些传球失败,并非完全是传球技巧问题,而是由于解围等原因导致的。例如,在比赛进行的前 5分钟,在底线附近的一次传球失败,很可能是在解围时出现的。
这里只是展示了 5 分钟的可视化数据,显然我们可以在不同的时间范围内,使用更多种类的足球数据进行详细分析。
其他的一些想法
-
Matplotlib 可以提供丰富的绘图工具,但相对较耗时。 -
在此情境下,二维密度图和旭日图是不错的可视化选择。 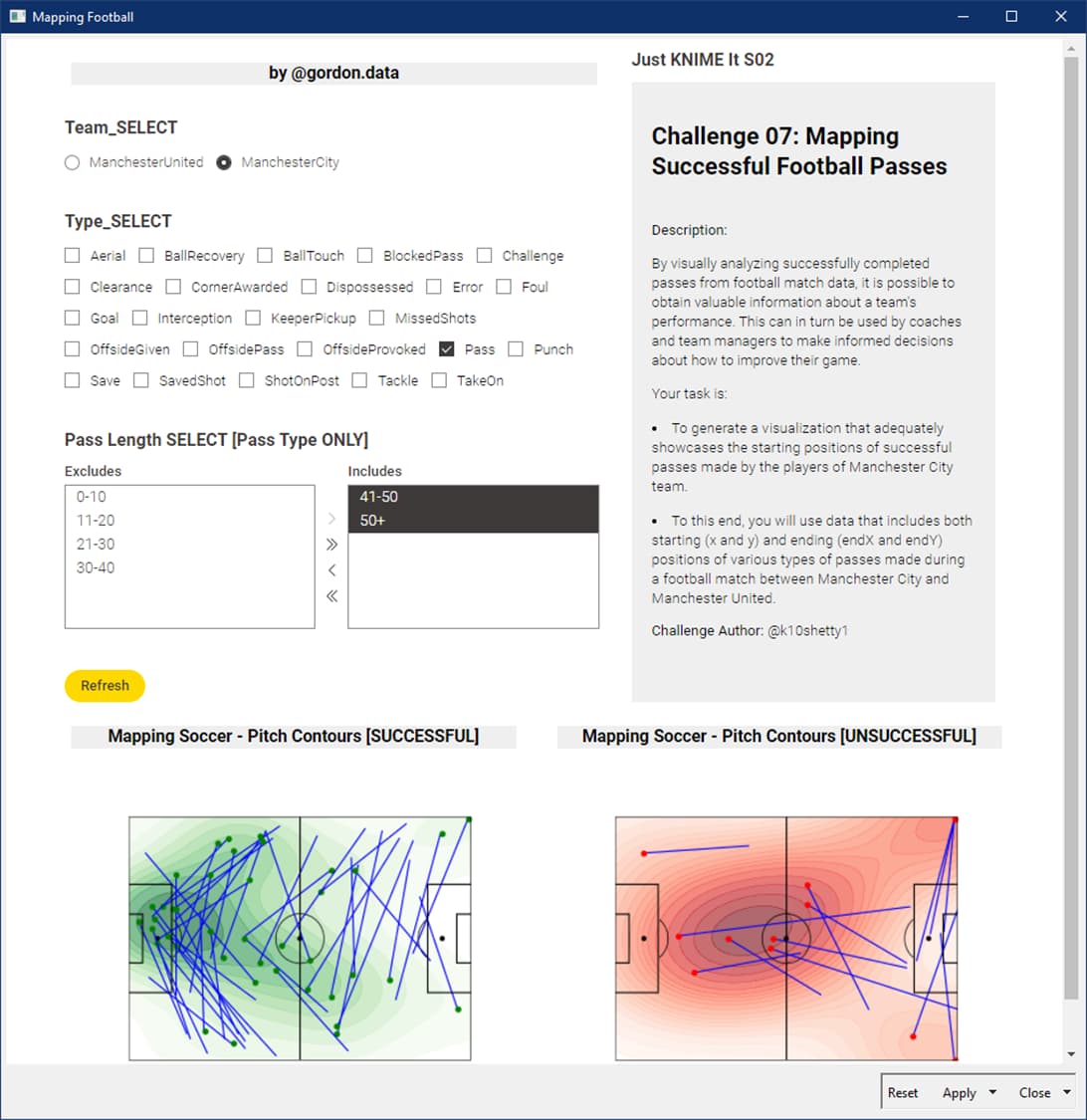
-
传球成功的因素众多,除了通行证,还有其他类型的数据需要进行分析,但时间有限。 -
这是 Just KNIME It 第2季第7集的问题,有兴趣可以去论坛看下其他人的方案 -
Just KNIME It: https://www.knime.com/just-knime-it -
第2季第7集论坛讨论: https://forum.knime.com/t/solutions-to-just-knime-it-challenge-07-season-2/66844
-
广告: 指北君出版了一本书, <<KNIME 视觉化数据分析>>, 纸质版、电子版各大平台均有销售,欢迎阅读。[2023/05/16: 微信读书的版本错别字问题出版社还未解决,请耐心等待]
本文由 mdnice 多平台发布
这篇关于⚽ 使用 KNIME 分析足球比赛数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




