本文主要是介绍Apache Hadoop 的 HDFS federation 前世今生,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
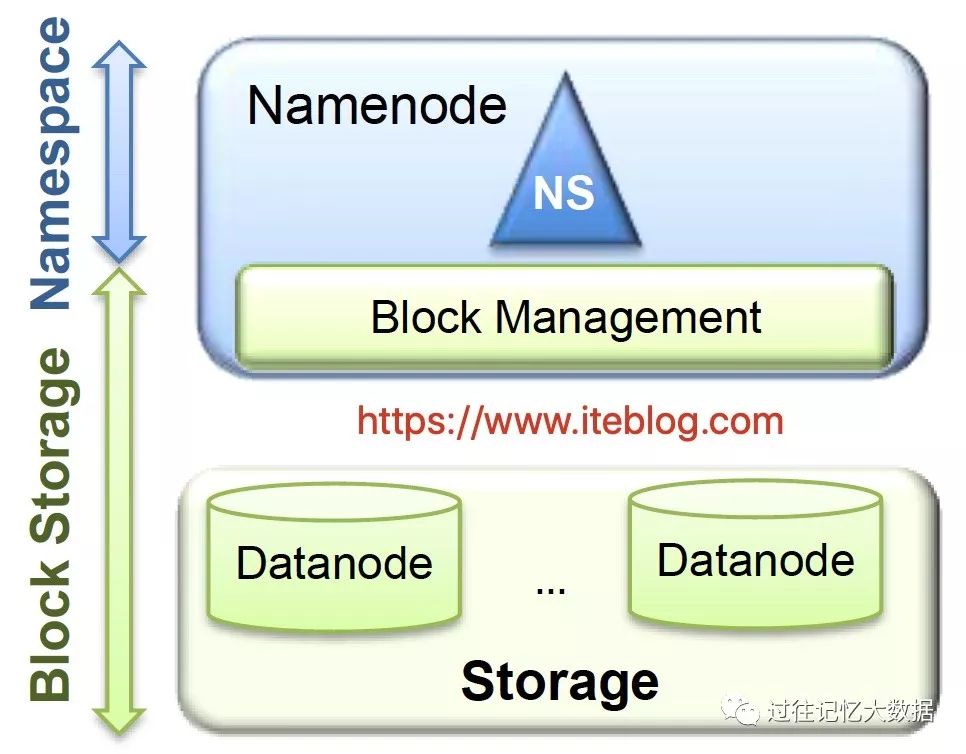
熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
从上面可以看出 HDFS 的架构其实大致可以分为两层:
Namespace:由目录,文件和数据块组成,支持常见的文件系统操作,例如创建,删除,修改和列出文件和目录。
Block Storage Service:这个部分又由两部分组成
数据块管理(Block Management),这个模块由 NameNode 提供
通过处理 DataNode 的注册和定期心跳来提供集群中 DataNode 的基本关系;
维护数据到数据块的映射关系,以及数据块在 DataNode 的映射关系;
支持数据块相关操作,如创建,删除,修改和获取块位置;
管理副本的放置,副本的创建,以及删除多余的副本。
存储( Storage) - 是由 DataNode 提供,主要在本地文件系统存储数据块,并提供读写访问。
虽然这个架构可以很好的处理海量的大数据存储,但是当文件比较多,特别是集群运行了很长时间产生大量小文件的情况下,这种架构的 NameNode 就会产生很严重的问题。这是因为集群中数据的元数据(比如文件由哪些块组成、这些块分别存储在哪些节点上)全部都是由 NameNode 节点维护,为了达到高效的访问, NameNode 在启动的时候会将这些元数据全部加载到内存中。而 HDFS 中的每一个文件、目录以及数据块,在 NameNode 内存都会有记录,每个数据块的信息大约占用150字节的内存空间。当 NameNode 维护的目录和文件总量达到1亿,数据块总量达到4亿后,常驻内存使用量将达到90GB!这将严重影响 HDFS 集群的扩展性。
任何一方面,单个 NameNode 提供读写访问请求,也会影响整个 HDFS 集群的吞吐量。同时,这种架构中所有租户共享一个命名空间(namespace),无法对不同的应用程序进行隔离。
HDFS Federation
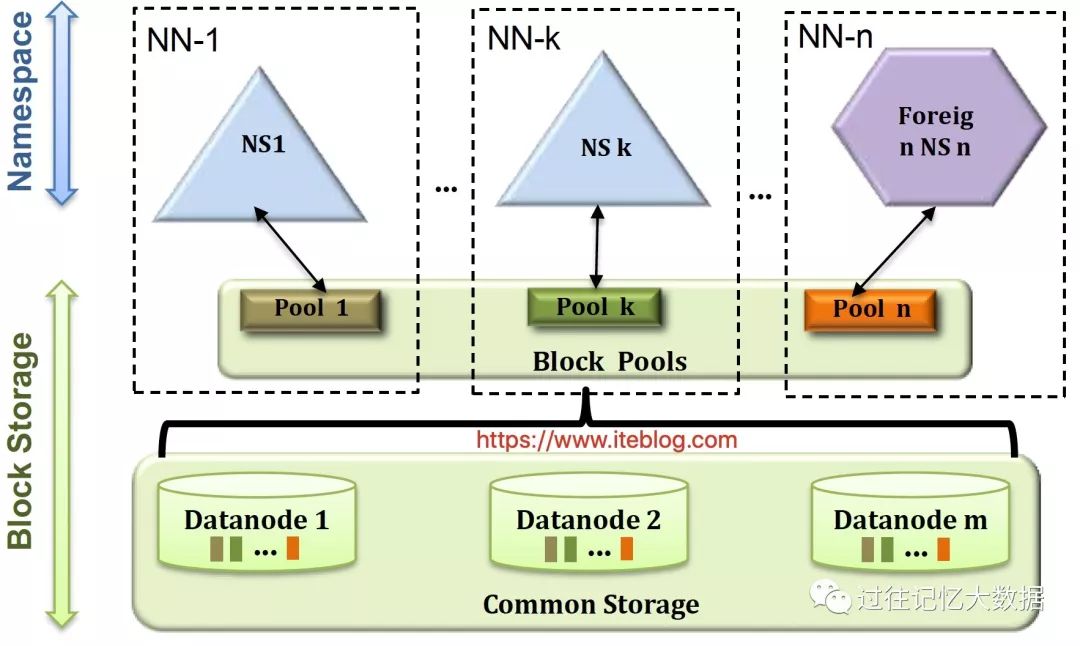
为了解决 HDFS 的水平扩展性问题,社区从 Apache Hadoop 0.23.0 版本开始引入了 HDFS federation(参见 HDFS-1052)。HDFS Federation 是指 HDFS 集群可同时存在多个 NameNode/Namespace,每个 Namespace 之间是互相独立的;单独的一个 Namespace 里面包含多个 NameNode,其中一个是主,剩余的是备,这个和上面我们介绍的单 Namespace 里面的架构是一样的。这些 Namespace 共同管理整个集群的数据,每个 Namespace 只管理一部分数据,之间互不影响。
集群中的 DataNode 向所有的 NameNode 注册,并定期向这些 NameNode 发送心跳和块信息,同时 DataNode 也会执行 NameNode 发送过来的命令。集群中的 NameNodes 共享所有 DataNode 的存储资源。HDFS Federation 的架构如下图所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
通过 HDFS Federation 架构可解决单 NameNode 存在扩展性、业务隔离以及性能等问题。关于如何配置 HDFS Federation 可以参见这里。
ViewFs
这个版本的 HDFS Federation 虽然能够解决单 Namespace 带来的一些问题,但是又引来了新的问题。比如现在集群中存在多个 Namespace,每个 Namespace 管理一部分数据,那客户端如何知道要查询的数据在哪个 Namespace 上呢?为了解决这个问题,社区引入了视图文件系统(View File System,简称 ViewFs),具体可以参见 HADOOP-7257。ViewFs 类似于某些 Unix / Linux 系统中的客户端挂载表。ViewFs 可用于创建个性化命名空间视图,也可用于创建每个群集的公共视图。那 ViewFs 是如何解决文件映射到对应的 Namespace 上呢?
ViewFs 通过在 core-site.xml 文件里面引入了路径映射配置,如下:

正如上面的配置文件所示,在启用了 HDFS Federation 的集群,fs.defaultFS 的值已经变成了 viewfs://clusterX,这个和未启用 HDFS Federation 的集群是不一样的。然后紧接着配置了五个属性,用于指定文件和集群的映射关系。
比如用户访问了 /data 路径,那么通过这个配置文件,我们就知道直接到 hdfs://nn1-clusterx.iteblog.com:8020 集群的 /data 路径下拿数据;当用户访问 /iteblog,那么通过这个配置文件,我们就知道直接到 hdfs://nn2-clusterx.iteblog.com:8020 集群的 /iteblog 路径下拿数据。其他路径的数据获取和这个类似。如果访问的路径在配置文件里面没找到,那么将会访问 fs.viewfs.mounttable.ClusterX.linkFallback 属性配置的集群和路径进行访问。关于详细的 ViewFs 配置可以参见 官方文档。
HDFS Router-based Federation
ViewFs 方案虽然可以很好的解决文件命名空间问题,但是它的实现有以下几个问题:
ViewFS 是基于客户端实现的,需要用户在客户端进行相关的配置,那么后面对客户端升级就会比较困难,这个客户端相当于重客户端了;
新增或者修改路径映射,需要多方配合完成,维护成本比较高。
为了解决这个问题,社区从 Hadoop 2.9.0 和 Hadoop 3.0.0 版本开始引入了一种基于路由的 Federation方案(Router-Based Federation),具体参见 HDFS-10467,这个方案主要是由微软和优步的工程师实现。和之前的 ViewFS 不一样,这个是基于服务端实现的。
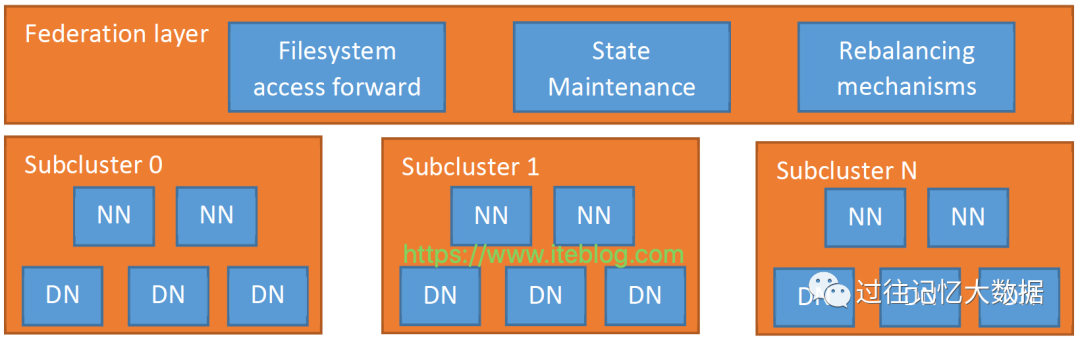
基于路由的 Federation 方案是在服务端添加了一个 Federation layer,这个额外的层允许客户端透明地访问任何子集群,让子集群独立地管理他们自己的 block pools,并支持跨子集群的数据平衡。为实现这些目标,Federation layer 必须将块访问路由到正确的子集群,维护 namespaces 的状态,并提供数据重新平衡的机制,跨集群的数据平衡可以参见 HDFS-13123。同时,这个层必须具有可扩展性,高可用性和容错性。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Federation layer 的设计架构如上图所示,从上图可以看出,这个层包含了多个组件:Router、State Store 以及 Rebalancing mechanisms。Router 组件和 Namenode 具有相同的接口,并根据 State Store 里面的信息将客户端请求转发到正确的子集群。State Store 是远程挂载表(remote mount table,和 ViewFS 方案里面的配置文件类似,但在客户端之间共享),存储子集群相关的信息包括 load/capacity。下面对这几个模块进行介绍。
Router
一个系统中可以包含多个 Router,每个 Router 主要包含两个作用:
通过 Federated interface,Router 为客户端提供单个全局的 NameNode 接口,并将客户端的请求转发到正确子集群中的活动 NameNode 上;路由器接收到客户端的请求,然后检查 State Store 中是否有正确的子集群,并将请求转发到该子集群的活动 NameNode 上。路由器是无状态的,所以可以部署在负载均衡器后面并达到高可扩展性等。为了提高性能,路由器还会缓存远程挂载表里面的信息和子群集的状态。为确保 State Store 的更改可以传播到所有的路由器,每个路由器需要向 State Store 发送心跳信息。
收集 NameNode 的心跳信息,报告给 State Store,这样 State Store 维护的信息是实时更新的。路由器也会定期检查 NameNode 的状态(通常位于同一服务器上),并将其高可用性(HA)状态和负载/空间状态报告给 State Store。为了实现高可用性和灵活性,多个路由器可以监视相同的 Namenode 并将心跳发送到 State Store,这种方式可以提高整个系统的可靠性,State Store 中冲突的 NameNode 信息是由每个 Router 通过 quorum 协议解决。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
State Store
State Store 物理实现是分布式的,在 State Store 里面主要维护以下几方面的信息:
子集群的状态,包括块访问负载,可用磁盘空间,HA状态等;
文件夹/文件和子集群之间的映射,即远程挂载表;
Rebalancer 操作的状态;
Routers 的状态。
上面四点中的文件夹/文件和子集群之间的映射其实和 ViewFS 里面的远程挂载表类似,内容如下:

通过这些我们就可以知道数据在哪个子集群,针对这些信息的存储 Hadoop 为我们提供了几种实现,包括基于文件(StateStoreFileSystemImpl)的和基于ZK(StateStoreZooKeeperImpl)的方式,可以通过 dfs.federation.router.store.driver.class 参数配置。关于 Router-Based Federation 更多的情况请访问 Hadoop 的官方文档。
Router-Based Federation 整个访问流程
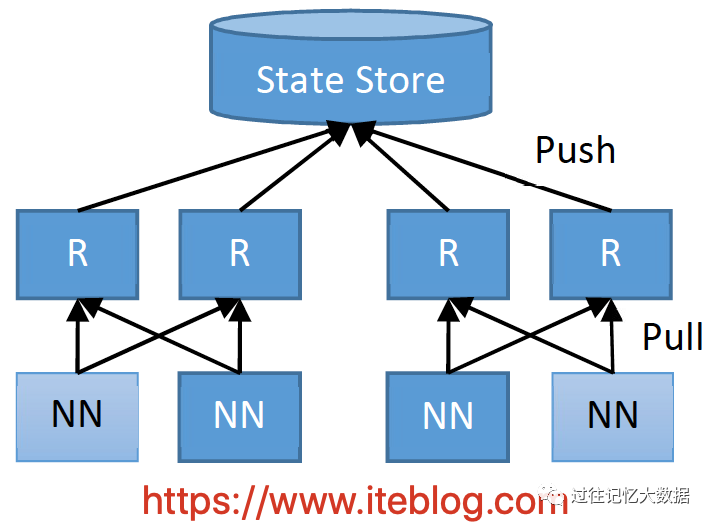
上面已经简单的介绍了 Router-Based Federation 的各个组件等情况,下面我们来看看这个方案客户端访问文件的流程,如下所示:
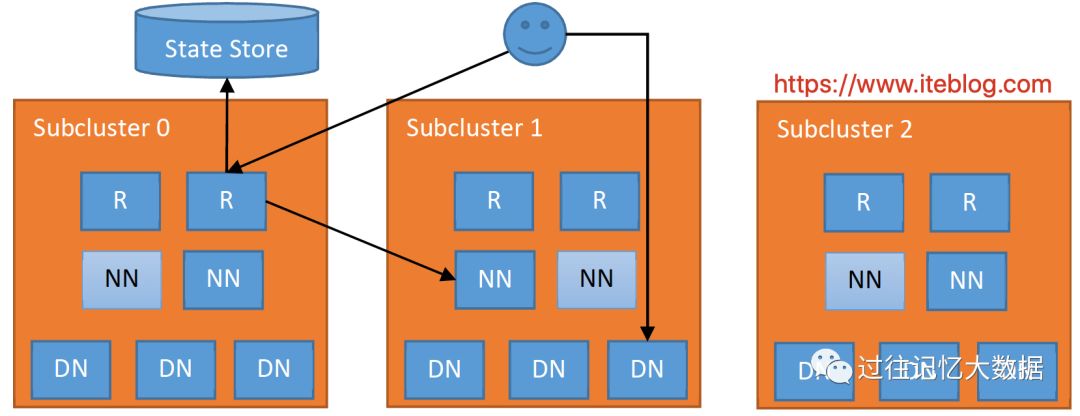
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
图中的 R 代表 Router。当客户端需要进行读写操作,它的步骤如下:
客户端向集群中任意一个 Router 发出某个文件的读写请求操作;
Router 从 State Store 里面的 Mount Table 查询哪个子集群包含这个文件,并从 State Store 里面的 Membership table 里面获取正确的 NN;
Router 获取到正确的 NN 后,会将客户端的请求转发到 NN 上,然后也会给客户端一个请求告诉它需要请求哪个 子集群;
此后,客户端就可以直接访问对应子集群的 DN,并进行读写相关的操作。
由于 Router-based HDFS federation 还算比较新的特性,所以社区分了几个阶段修复或添加了一些新的功能,比如 Apache Hadoop 3.2.0 版本修复或添加了一些功能,参见 HDFS-12615,以及 Router-based HDFS federation 稳定性相关的 ISSUE HDFS-13891,这个 ISSUE 可能会在 Apache Hadoop 3.3.0 版本发布。
欢迎关注本公众号:iteblog_hadoop:
回复 spark_summit_201806 下载 Spark Summit North America 201806 全部PPT
回复 spark_summit_eu_2018 下载 Spark+AI Summit europe 2018 全部PPT
回复 HBase_book 下载 2018HBase技术总结 专刊
回复 all 获取本公众号所有资料
0、回复 电子书 获取 本站所有可下载的电子书
1、Elasticsearch如何做到亿级数据查询毫秒级返回?
2、京东HBase平台进化与演进
3、深入理解 Spark Delta Lake 的诞生及其工作原理
4、Apache Kafka 2.3 发布,新特性讲解
5、Hadoop 气数已尽?
6、一条 SQL 在 Apache Spark 之旅(下)
7、Kafka 是如何保证数据可靠性和一致性
8、Kylin 在小米大数据中的应用
9、Uber 大数据平台的演进(2014~2019)
10、图文了解 Kafka 的副本复制机制
11、更多大数据文章欢迎访问https://www.iteblog.com及本公众号(iteblog_hadoop) 12、Flink中文文档: http://flink.iteblog.com 13、Carbondata 中文文档: http://carbondata.iteblog.com



这篇关于Apache Hadoop 的 HDFS federation 前世今生的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






