本文主要是介绍【Mapreduce】利用单表关联在父子关系中求解爷孙关系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
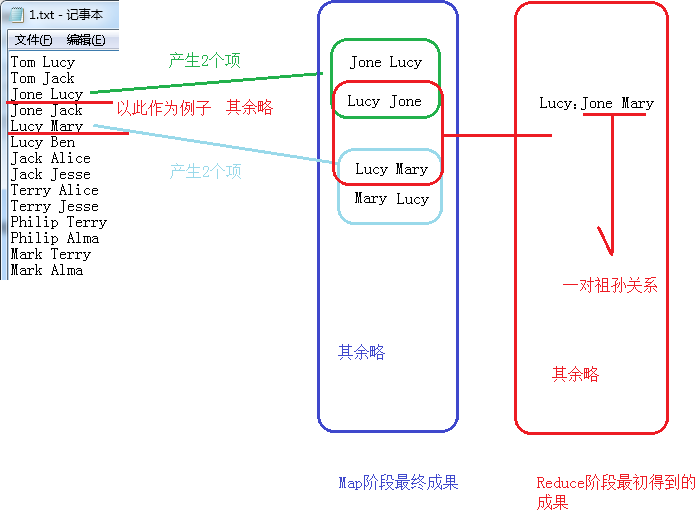
首先是有如下数据,设定左边是右边的儿子,右边是左边的父母
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark AlmaTom Jesse
Tom Alice
Jone Jesse
Jone Alice
Jone Ben
Jone Mary
Tom Ben
Tom Mary
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
要利用Mapreduce解决这个问题,主要思想如下:
1、在Map阶段,将父子关系与相反的子父关系,同时在各个value前补上前缀-与+标识此key-value中的value是正序还是逆序产生的,之后进入context。
下图通过其中的Jone-Lucy Lucy-Mary,求解出Jone-Mary来举例
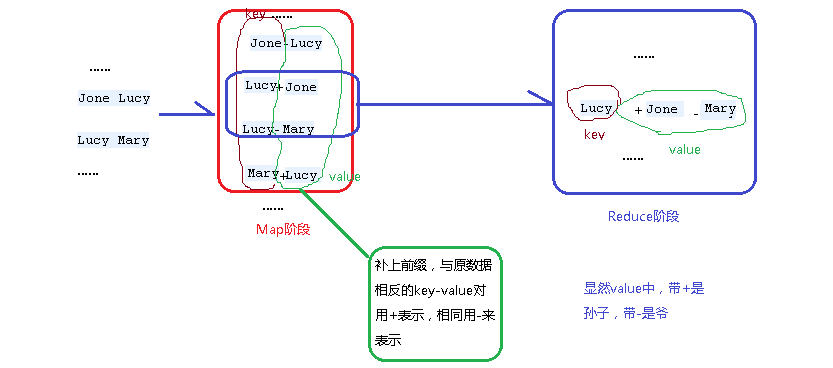
2、MapReduce会自动将同一个key的不同的value值,组合在一起,推到Reduce阶段。在value数组中,跟住前缀,我们可以轻松得知,哪个是爷,哪个是孙。
因此对各个values数组中各个项的前缀进行输出。
可以看得出,整个过程Key一直被作为连接的桥梁来用。形成一个单表关联的运算。
因此代码如下,根据上面的思想很容易得出如下的代码了,需要注意的是,输出流输入流都要设置成Text,因为全程都是在对Text而不是IntWritable进行操作:
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class MyMapReduce {public static class MyMapper extends Mapper<Object, Text, Text, Text> {public void map(Object key, Text value, Context context)throws IOException, InterruptedException {String child = value.toString().split(" ")[0];String parent = value.toString().split(" ")[1];//产生正序与逆序的key-value同时压入contextcontext.write(new Text(child), new Text("-" + parent));context.write(new Text(parent), new Text("+" + child));}}public static class MyReducer extends Reducer<Text, Text, Text, Text> {public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {ArrayList<Text> grandparent = new ArrayList<Text>();ArrayList<Text> grandchild = new ArrayList<Text>();for (Text t : values) {//对各个values中的值进行处理String s = t.toString();if (s.startsWith("-")) {grandparent.add(new Text(s.substring(1)));} else {grandchild.add(new Text(s.substring(1)));}}//再将grandparent与grandchild中的东西,一一对应输出。for (int i = 0; i < grandchild.size(); i++) {for (int j = 0; j < grandparent.size(); j++) {context.write(grandchild.get(i), grandparent.get(j));}}}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length != 2) {System.err.println("Usage: wordcount <in> <out>");System.exit(2);}Job job = new Job(conf);job.setMapperClass(MyMapper.class);job.setReducerClass(MyReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);// 判断output文件夹是否存在,如果存在则删除Path path = new Path(otherArgs[1]);// 取第1个表示输出目录参数(第0个参数是输入目录)FileSystem fileSystem = path.getFileSystem(conf);// 根据path找到这个文件if (fileSystem.exists(path)) {fileSystem.delete(path, true);// true的意思是,就算output有东西,也一带删除}FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}这篇关于【Mapreduce】利用单表关联在父子关系中求解爷孙关系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





