本文主要是介绍刘二大人《PyTorch深度学习实践》循环神经网络RNN高级篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
个人认为RNN的两个视频讲的没有前面几个视频通俗易懂
任务:输入名字,输出名字对应的国家
模型

########################################### 题外话 本次使用了双向循环神经网络
Bi-Direction RNN/LSTM/GRU 双向循环神经网络
对于单向的循环神经网络,输出只考虑过去的信息(只有一个方向),而有些情景需要考虑未来的信息
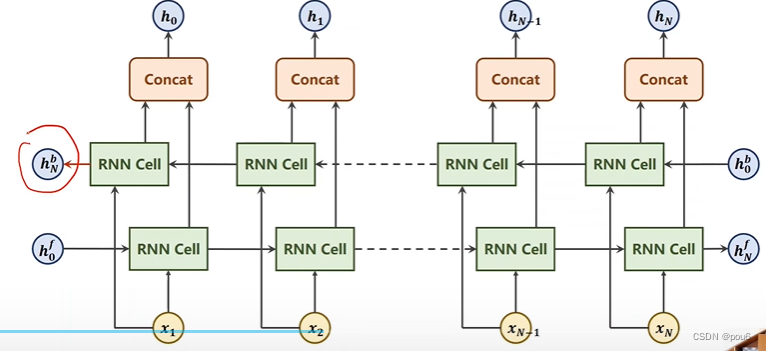
将正向和反向的隐藏层做拼接
###############################################################
着重解释 数据处理部分
输入单词,先转变成序列,因为都是英文字符所以使用ascll表
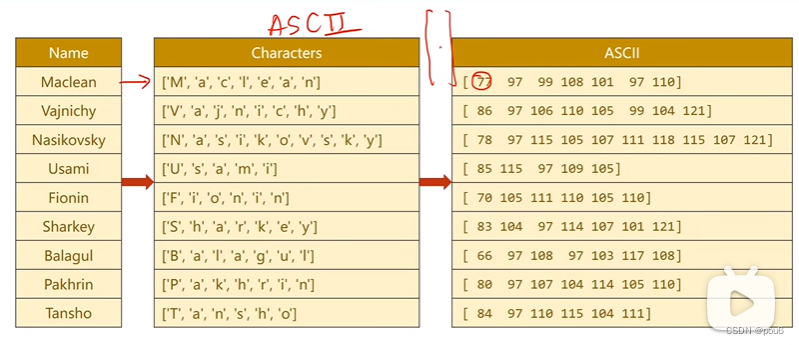
若对于'M'使用独热向量,则77表示只有第77个元素为1(过于稀疏)
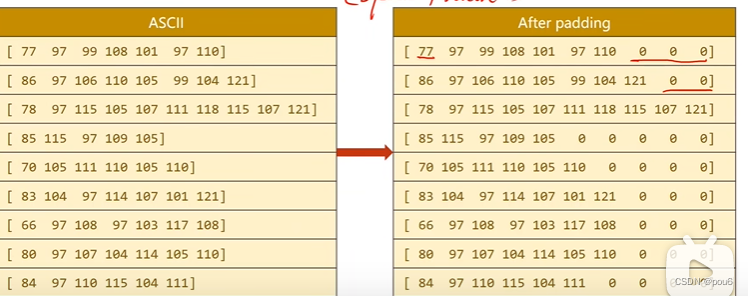
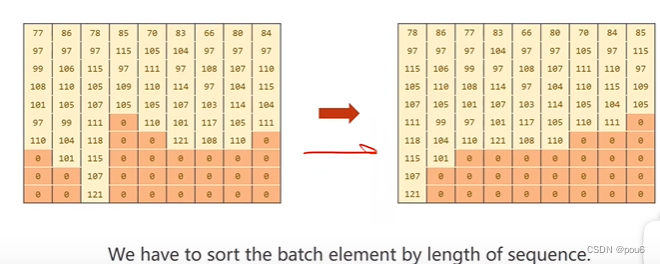
对于张量。要求所有的张量维度相等,所以需要padding填充
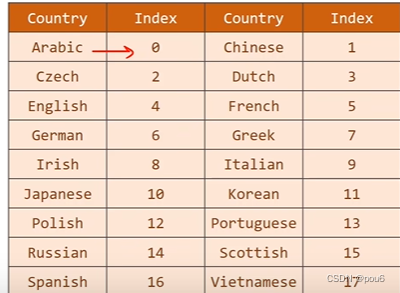
对于国家名,处理成索引标签
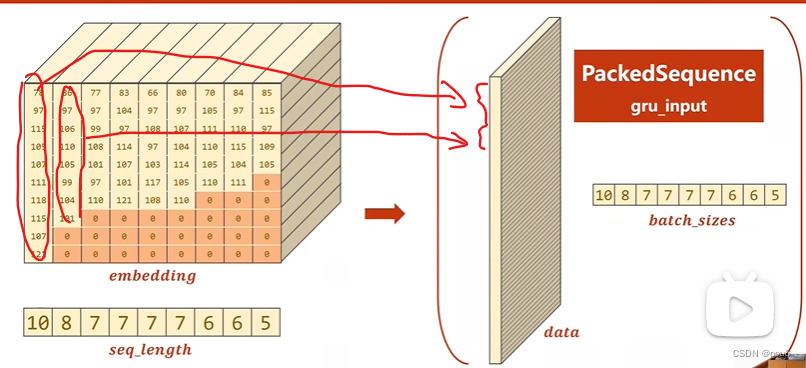
对padding后的矩阵转置再经过Embedding

对于变长序列,按序列长度排序后(不排序没法用PackedSequence),通过PackedSequence只存非0的维度,同时记住每个序列的非0项的长度(提高储存密度,提高计算速度),输入gru中
代码实现:
def make_tensors先把名字的ascll和长度、国家取出
然后设置一个全0张量尺寸 (batchsize,seq_lengths.max())
再把数据覆盖上去
然后按序列长度从大到小排序,同时把countries列表也转成相应的从大到小格式
最后输出tensor格式的seq_tensor、seq_lengths、countries
这样在训练时,seq_tensor、seq_lengths会传入模型
使用
gru_input = pack_padded_sequence(embedding,seq_lengths) pack_padded_sequence()将会自动根据序列长度去掉0项
##################################################################
全文代码实现
import torch
import csv
from torch.utils.data import DataLoader,Dataset
from torch.nn.utils.rnn import pack_padded_sequence
import matplotlib.pyplot as plt
# 输入姓名 输出属于哪个国家
import gzip
import timeHIDDEN_SIZE = 100
BATCH_SIZE = 1024
N_LAYER = 2
N_EPOCHS = 100
N_CHARS = 128
USE_GPU = False
start = time.time()############################################################################# 读入数据
class NameDataset(Dataset):def __init__(self,is_train_set=True):filename = './names_train.csv' if is_train_set else './names_test.csv'with open (filename,'rt') as f:reader = csv.reader(f)rows = list(reader)self.names = [row[0] for row in rows] #第一列人名self.len = len(self.names) #名字长度self.countries = [row[1] for row in rows] #对应国家名self.country_list = list(sorted(set(self.countries))) #对国家名长度排序self.country_dict = self.getCountryDict() #构造字典 key:国家名 value:indexself.country_num = len(self.country_list) #国家个数def __getitem__(self, index): #必须重写__getitem__和__len__方法return self.names[index],self.country_dict[self.countries[index]]def __len__(self):return self.lendef getCountryDict(self):country_dict = dict()for idx,country_name in enumerate(self.country_list,0):country_dict[country_name] = idxreturn country_dictdef idx2country(self,index):return self.country_list[index]def getCountriesNum(self):return self.country_numtrainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=True)N_COUNTRY = trainset.getCountriesNum()############################################################################## 模型class RNNClassifier(torch.nn.Module):def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):super(RNNClassifier,self).__init__()self.hidden_size = hidden_sizeself.n_layers=n_layersself.n_directions = 2 if bidirectional else 1 #单向还是双向循环神经网络self.embedding = torch.nn.Embedding(input_size,hidden_size)self.gru = torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)self.fc = torch.nn.Linear(hidden_size*self.n_directions,output_size) #如果是双向则维度*2def _init_hidden(self,batch_size):hidden = torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)return create_tensor(hidden)def forward(self,input,seq_lengths):#input shape Batchsize*SeqLen->SeqLen*Batchsizeinput = input.t() #矩阵转置batch_size = input.size(1)hidden = self._init_hidden(batch_size)embedding = self.embedding(input)# pack them upgru_input = pack_padded_sequence(embedding,seq_lengths) ### make be sorted by descendent 打包变长序列output , hidden = self.gru(gru_input,hidden)if self.n_directions == 2:hidden_cat = torch.cat([hidden[-1],hidden[-2]],dim=1)else:hidden_cat = hidden[-1]fc_output = self.fc(hidden_cat)return fc_output############################################################################ 数据处理
def create_tensor(tensor):if USE_GPU:device = torch.device("cuda:0")tensor = tensor.to(device)return tensordef name2list(name): #返回ascll值和长度arr = [ord(c) for c in name]return arr, len(arr)def make_tensors(names,countries):sequences_and_lengths = [name2list(name) for name in names]name_sequences = [sl[0] for sl in sequences_and_lengths] #名字的ascll值seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) #单独把列表长度拿出来 (名字的长度)countries = countries.long()#make tensor of name,BatchSize x SeqLen paddingseq_tensor = torch.zeros(len(name_sequences),seq_lengths.max()).long() #先做一个batchsize*max(seq_lengths)全0的张量for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):seq_tensor[idx,:seq_len]= torch.LongTensor(seq) #把数据贴到全0的张量上去#sort by length to use pack_padded_sequenceseq_lengths,perm_idx = seq_lengths.sort(dim=0,descending=True) #sort返回排完序的序列和对应的indexseq_tensor = seq_tensor[perm_idx]countries = countries[perm_idx]return create_tensor(seq_tensor),\create_tensor(seq_lengths),\create_tensor(countries)############################################################################ 训练测试模块
def trainModel():total_loss = 0for i,(names,countries) in enumerate(trainloader,1):inputs,seq_lengths,target = make_tensors(names,countries)output = classifier(inputs,seq_lengths)loss = criterion(output,target)optimizer.zero_grad()loss.backward()optimizer.step()total_loss+=loss.item()if i%10==0:print(f'[{time_since(start)}] Epoch{epoch}',end='')print(f'[{i*len(inputs)}/{ len(trainset)}]',end='')print(f'loss={total_loss/(i*len(inputs))}')return total_lossdef testModel():correct = 0total = len(testset)print("evaluating trained model...")with torch.no_grad():for i,(names,countrise) in enumerate(testloader,1):inputs,seq_lengths,target = make_tensors(names,countrise)output = classifier(inputs,seq_lengths)pred = output.max(dim = 1,keepdim=True)[1]correct+=pred.eq(target.view_as(pred)).sum().item()percent = '%.2f'%(100*correct/total)print(f'Test set:Accuracy {correct}/{total} {percent}%')return correct/totaldef time_since(start):"""计算给定时间戳 `start` 与当前时间之间的时间差"""return time.time() - startif __name__=='__main__':classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')if USE_GPU:device = torch.device("cuda:0")classifier.to(device)criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)print("Training for %d epochs..." % N_EPOCHS)acc_list = []epoch_list=[]for epoch in range(1,N_EPOCHS+1):trainModel()acc=testModel()acc_list.append(acc)epoch_list.append(epoch)plt.plot(epoch_list,acc_list)plt.ylabel('Accuracy')plt.xlabel('epoch')plt.grid()plt.show()
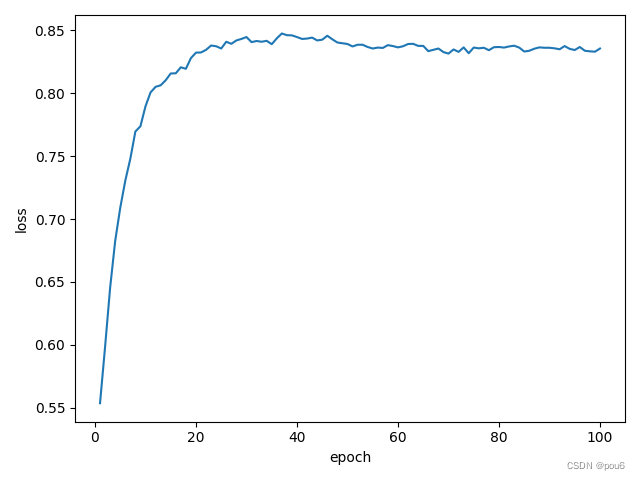
#################################################################
使用该模型参加kaggle的电影评论分析比赛(第一次在kaggle提交数据)
Sentiment Analysis on Movie Reviews | Kaggle
最终准确率
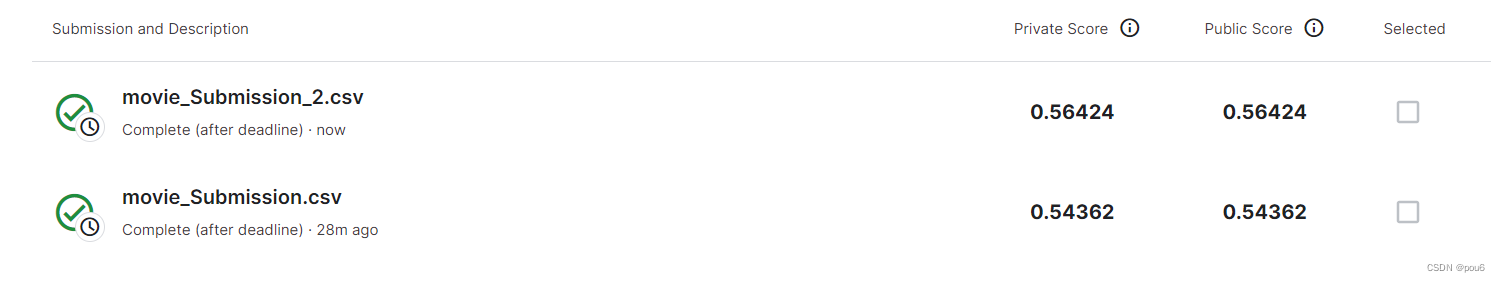
movie_Submission使用双向循环网络
movie_Submission_2不使用双向循环网络
准确率较差,因为我没有语义分割而是直接把文本变成Ascii码进行训练
这篇关于刘二大人《PyTorch深度学习实践》循环神经网络RNN高级篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





