本文主要是介绍Apache-POI读取Excel2003和Excel2007中数据。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先在F盘下的poiExcelTest文件夹下建立2个文件:student2003.xls和student2007.xlsx,如图
内容为:
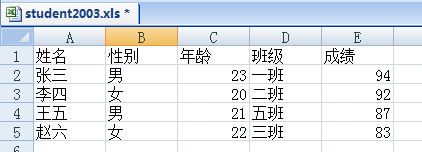
2个文件中的内容一样
由于Excel2003和Excel2007数据读取方式不一样,
Excel2003需要用HSSF…开头的类,Excel2007需要XSSF…开头的类,所以,通过判断文件后缀名之后用不同的方法来读取,
本测试中用到的jar在这里下载就行了
点击这里下载jar:
一下是测试代码:
package com.apache.poi.process.excel.poi.Excel.Test;import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.xssf.XLSBUnsupportedException;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;import com.apache.poi.process.excel.poi.Excel.model.Student;/*** POI读取Excel实例,分2003和2007* * @author zhangpei* */
public class ReadExcel {private static String xls2003 = "F:\\poiExcelTest\\student2003.xls";private static String xls2007 = "F:\\poiExcelTest\\student2007.xlsx";/*** 将Excel2003的数据读取做处理* * @param filePath* @return*/private static List<Student> readFromXLS2003(String filePath) {File excelFile = null;// Excel文件对象InputStream is = null;// 输入流对象String cellStr = null;// 单元格,最终按字符串处理List<Student> studentList = new ArrayList<Student>();// 返回封装数据的ListStudent student = null;// 每个学生信息对象try {excelFile = new File(filePath);is = new FileInputStream(excelFile);// 获取文件输入流HSSFWorkbook workbook2003 = new HSSFWorkbook(is);// 创建Excel2003文件对象HSSFSheet sheet = workbook2003.getSheetAt(0);// 取出第一个工作表,索引是0// 这里注意区分getLastRowNum()和getPhysicalNumberOfRows()的区别System.out.println("sheet.getLastRowNum():" + sheet.getLastRowNum());System.out.println("sheet.getPhysicalNumberOfRows():"+ sheet.getPhysicalNumberOfRows());// 开始循环遍历行,表头不处理,从1开始for (int i = 1; i <= sheet.getLastRowNum(); i++) {student = new Student();// 实例化Student对象HSSFRow row = sheet.getRow(i);// 获取行对象if (row == null) {// 如果为空,不处理continue;}// 如果row不为空,循环遍历单元格System.out.println("row.getLastCellNum:" + row.getLastCellNum());for (int j = 0; j < row.getLastCellNum(); j++) {HSSFCell cell = row.getCell(j);// 获取单元格对象if (cell == null) {// 如果为空,设置cellStr为空串cellStr = "";} else if (cell.getCellType() == HSSFCell.CELL_TYPE_BOOLEAN) {// 对布尔值的处理cellStr = String.valueOf(cell.getBooleanCellValue());} else if (cell.getCellType() == HSSFCell.CELL_TYPE_NUMERIC) {// 对数字值的处理cellStr = cell.getNumericCellValue() + "";} else {// 其余按照字符串处理cellStr = cell.getStringCellValue();}// 下面按照数据出现的位置封装到bena中if (j == 0) {student.setName(cellStr);} else if (j == 1) {student.setGender(cellStr);} else if (j == 2) {student.setAge(new Double(cellStr).intValue());} else if (j == 3) {student.setSclass(cellStr);} else {student.setScore(new Double(cellStr).intValue());}}studentList.add(student);// 数据装入List}} catch (Exception e) {e.printStackTrace();} finally {// 关闭文件流if (is != null) {try {is.close();} catch (Exception e2) {e2.printStackTrace();}}}return studentList;}/*** 将Excel2007表格数据读取做处理*/public static List<Student> readFromXLSX2007(String filePath) {File excelFile = null;// Excel文件对象InputStream is = null;// 输入流对象String cellStr = null;// 单元格,最终按字符串处理List<Student> studentList = new ArrayList<Student>();// 返回封装数据的ListStudent student = null;// 每一个学生信息对象try {excelFile = new File(filePath);is = new FileInputStream(excelFile);// 获取文件输入流XSSFWorkbook workbook2007 = new XSSFWorkbook(is);// 创建Excel2007文件对象XSSFSheet sheet = workbook2007.getSheetAt(0);// 取出第一个工作表,索引为0// 这里注意区分getLastRowNum()和getPhysicalNumberOfRows()的区别System.out.println("sheet.getLastRowNum():" + sheet.getLastRowNum());System.out.println("sheet.getPhysicalNumberOfRows():"+ sheet.getPhysicalNumberOfRows());// 开始循环遍历行,表头不处理,从1开始for (int i = 1; i <= sheet.getLastRowNum(); i++) {student = new Student();// 实例化Student对象XSSFRow row = sheet.getRow(i);// 获取行对象if (row == null) {// 如果为空,不处理continue;}// row如果不为空,循环遍历单元格for (int j = 0; j < row.getLastCellNum(); j++) {XSSFCell cell = row.getCell(j);// 获取单元格对象if (cell == null) {// 单元格为空设置cellStr为空串cellStr = "";} else if (cell.getCellType() == XSSFCell.CELL_TYPE_BOOLEAN) {// 对布尔值的处理cellStr = String.valueOf(cell.getBooleanCellValue());} else if (cell.getCellType() == XSSFCell.CELL_TYPE_NUMERIC) {// 对数字值的处理cellStr = cell.getNumericCellValue() + "";} else {// 其余按照字符串处理cellStr = cell.getStringCellValue();}// 下面按照数据出现位置封装到bean中if (j == 0) {student.setName(cellStr);} else if (j == 1) {student.setGender(cellStr);} else if (j == 2) {student.setAge(new Double(cellStr).intValue());} else if (j == 3) {student.setSclass(cellStr);} else {student.setScore(new Double(cellStr).intValue());}}studentList.add(student);// 数据装入List}} catch (Exception e) {e.printStackTrace();} finally {// 关闭文件流try {if (is != null) {is.close();}} catch (Exception e2) {e2.printStackTrace();}}return studentList;}/*** 测试从Excel2003中读取数据话费了的时间*/public void testReadExcel2003CostTime(String xlsPath) {long start = System.currentTimeMillis();List<Student> list = readFromXLS2003(xlsPath);for (Student student : list) {System.out.println(student);}long end = System.currentTimeMillis();long totalTime = end - start;System.out.println("一共花费了" + totalTime + "ms");}/*** 测试从Excel2007中读取数据话费了的时间*/public void testReadExcel2007CostTime(String xlsPath) {long start = System.currentTimeMillis();List<Student> list = readFromXLSX2007(xlsPath);for (Student student : list) {System.out.println(student);}long end = System.currentTimeMillis();long totalTime = end - start;System.out.println("一共花费了" + totalTime + "ms");}/*** 主函数方法调用* * @param args*/public static void main(String[] args) {ReadExcel readExcel = new ReadExcel();readExcel.testReadExcel2003CostTime(xls2003);readExcel.testReadExcel2007CostTime(xls2007);}
}测试数据结果如下
sheet.getLastRowNum():4
sheet.getPhysicalNumberOfRows():5
row.getLastCellNum:5
row.getLastCellNum:5
row.getLastCellNum:5
row.getLastCellNum:5
Strudnet [age=23,gender=男,name=张三,sclass一班,score94]
Strudnet [age=20,gender=女,name=李四,sclass二班,score92]
Strudnet [age=21,gender=男,name=王五,sclass五班,score87]
Strudnet [age=22,gender=女,name=赵六,sclass三班,score83]
一共花费了143ms
sheet.getLastRowNum():4
sheet.getPhysicalNumberOfRows():5
Strudnet [age=23,gender=男,name=张三,sclass一班,score94]
Strudnet [age=20,gender=女,name=李四,sclass二班,score92]
Strudnet [age=21,gender=男,name=王五,sclass五班,score87]
Strudnet [age=22,gender=女,name=赵六,sclass三班,score83]
一共花费了413ms
这篇关于Apache-POI读取Excel2003和Excel2007中数据。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





