本文主要是介绍论文阅读——Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
之前有一段时间看了挺多深度学习方面的论文,但是由于时间方面的问题一直没来得及进行总结。最近一段时间突发奇想把自己看论文时的学习笔记给记录一下,由于之前没写过博文,所以排版可能会有点emmm...一言难尽。专业方面的知识,如果有理解不到位的地方欢迎各位大佬指教。
Abstract
- 最近,使用卷积网络实现超分辨率的研究集中在最小化均方重构误差这一方向。这种方法可达到较高的峰值信噪比,但是恢复出的图片缺乏纹理细节。
- 文章提出了一种SRGAN网络,基于感知相似进行对抗训练,使网络可以从低分辨率图像中恢复图像纹理,并在平均意见得分(MOS)测试中获得优异成绩。
1、Introduction
这一部分主要是介绍了近来一些超分辨率图像恢复的方法和所遇到的问题并提出自己的解决方法。
- 有监督的图像超分辨率算法的目标为最小化恢复的高分辨率图像和实物图像的均方误差(MSE),最小化MSE问题可以转化为最大化峰值信噪比(PSNR)。
- 但是由于MSE和PSNR主要用于处理像素级的图像差异,感知相关差异的能力非常有限,因此重构的纹理细节通常有缺失。


1.1、相关工作
1.1.1、图像超分辨率
这一部分主要是提到了图像超分辨率领域的发展历程和相关工作:
- 传统的图像超分辨率方法:线性,立方体或Lanczos滤波器,生成纹理极度光滑的图片。
- 关注边界保护的方法:建立低分辨率和高分辨率图像信息间的复杂映射,通常依赖于训练数据。
- Gu等人提出一种卷积稀疏编码的方法,通过处理整幅图像而不是重叠块提升了一致性。
- ...(相关工作的内容太多了,而且写得很杂乱都可以写成一个综述了,具体看论文吧,害...)
1.1.2、卷积神经网络的设计
这一部分主要提到了卷积神经网络在计算机视觉领域有着越来越重要的作用。随着网络深度的增加,网络的精度也在不断提高,但是越深的网络越难训练,于是引入残差网络一概念,残差网络通过在残差块的输入层和输出层引入跳跃连接减小了深度网络的训练难度。
1.1.3、损失函数
文章这一部分主要提到基于像素的损失函数(比如MSE)很难处理恢复丢失的高频细节,因为它把所有可能的结果进行逐像素的平均以达到较好的MSE数值,但是肉眼上看,生成的图片却是过度平滑的。随后,文章还提到了一些人的处理方法:
- 通过运用生成对抗网络GANs来生成图像(Mathieu 和 Denton 等人)。
- 通过增大基于逐像素的均方误差和判别器误差来训练网络(Yu和Porikl等人)。
- Li和wang提出用GANs来学习由一个风格到另一个风格的图片的映射(即风格转换)。
- ...(其他的具体看论文原文)

1.2、贡献
文章的主要贡献为:
- 文章中使用16个残差块构成的生成网络将图像的分辨率提升了4倍。
- 提出一个基于GAN网络的SRGAN,并使用VGG网络特征图上计算出的损失值代替基于MSE的损失值。
- 在三个公开基准数据集上进行测试,SRGAN取得了最好的平均意见得分(MOS),视觉效果最好。
2、Method
假设为原高分辨率图片,
为其低分辨率的副本,
为通过低分辨率图片
生成的超分辨率图像,
为图像的色彩通道数目。GAN网络中生成器的大概设计思路:
- 对
进行高斯滤波,并进行系数为
的下采样得到低分辨率图片
。
- 假设使用一个大小为
的张量来表示
的张量来表示。
- 最终目标是获得生成函数
来得到从
为网络的权重和偏置,
为训练图片的序号,则可以得到以下表达式。
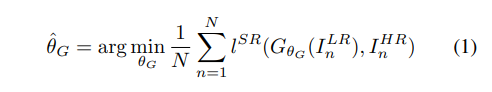
2.1、对抗网络结构
1、对抗网络的设计思路
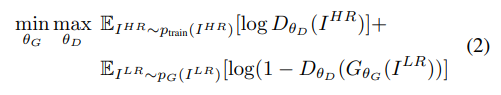
文中给出的对抗网络表达式如上,以下是我自己的理解。可以成生成网络基于输入的低分辨率图片产生超分辨率输出,
可以看成判别网络基于输入图像,输出该图像是否为真高分辨率图像的置信度值(0到1区间)。
可以看成使用判别网络判定真实高分辨率图像
为真的置信度有多少,
则可以看成使用判别网络判定生成超分辨率图片为假的置信度有多少。可以看出整个GAN网络基于min-max问题进行优化。对于max问题,通过训练修改参数
使判别器可以将真实高分辨率图片判定为真而把生成的超分辨率图片判定为假(即强化判别器的判别性能)。对于min问题,通过修改参数
使生成器可以生成更逼真的图片来瞒过判别器。min-max问题交替训练得到逼真的结果。
2、生成器结构:

k表示卷积核尺寸、n表示输出通道数、s为卷积步长(如k9n64s1表示3×3卷积核、64输出通道、步长为1的卷积层)
3、判别器结构:

2.2、感知损失函数
SRGAN网络的损失函数由内容损失和对抗损失两部分构成。
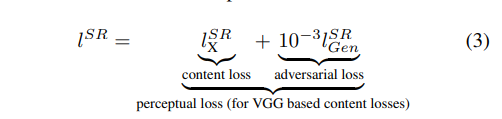
2.2.1、内容损失
1、MSE损失
- MSE损失函数是图片超分辨率用得最多的损失函数,其表达式如下所示。可以看出MSE损失函数的计算方式是使用高分辨图片
逐像素计算欧式距离最后求和取平均。
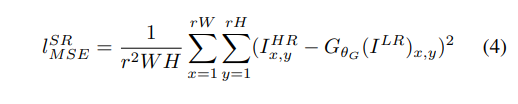
2、感知损失
- 感知损失是本论文中的一大亮点,其主要思想是使用一个VGG19网络对高分辨图片
和
分别为对应特征图的宽高,
为VGG19中第
个最大池化层前第
个卷积层输出的特征图。可以看出感知损失把VGG19网络中生成的特定层特征图拿出来,对
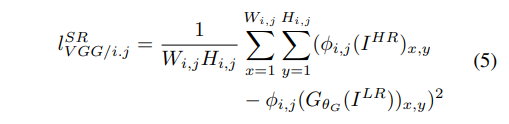
2.2.2、对抗损失
- 对抗损失的表达下如下图所示,主要的思想是让判别器在输入生成器生成的超分辨率图片
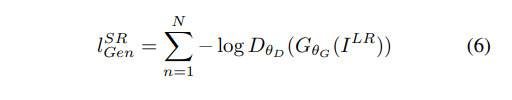
4、Discussion and future work
- 从人类视觉系统角度出发,MSE和PSNR标准不能精确地评估图像质量(MSE和PSNR高的图像可能看起来并不真实)。
- 更深的网络(残差模块数>16)可以更进一步增强SRResNet的性能,但会带来更大的计算负担。
- 由于VGG19网络中更深的卷积层表现出远高于像素层的提取特征能力,使用
作为感知损失函数可以得到更加逼真的结果。
5、Conclusion
- 构建了一个深度残差网络SRResNet,并在使用PSNR标准衡量网络生成的超分辨率图片时达到了顶尖的效果。
- 说明了使用MSE和PSNR标准衡量超分辨率图片时的局限性。
- 构建了一个SRGAN网络,并引入感知损失的概念,使网络生成的超分辨率图片效果非常逼真。
这篇关于论文阅读——Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









