本文主要是介绍ICML 2021杰出论文公布!上海交大校友摘得桂冠!田渊栋rebuttal加分论文获荣誉提名...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

本文转载自:AI科技评论
作者 | 维克多、琰琰 编辑 | 青暮
原定于在奥地利维也纳召开的ICML 2021,受疫情影响已于近日在线上召开。根据官方消息,会议将在7月18日~7月24日内完成所有的日程。
本次会议共收到5513篇论文投稿,接收1184篇论文,其中包含1018篇短论文和166篇长论文,接收率为21.48%,近五年最低。
在接收的一千多篇论文中,组委会最终挑出了四篇论文,分别颁发了一个杰出论文奖,三个杰出论文提名奖。

杰出论文奖由康奈尔大学博士生Yucheng Lu获得,他本科毕业于上海交通大学,研究领域是分布式优化和机器学习系统。获奖论文标题为“Optimal Complexity in Decentralized Training”,探究了去中心化训练的极限以及如何达到这种极限。

如上三篇文章获得了杰出论文荣誉提名奖,其中论文"Understanding Self-Supervised Learning Dynamics without Contrastive Pairs"由Facebook科学家田渊栋担任一作,其提出了一种新方法DirectPred,它根据输入的统计数据直接设置线性预测器,而无需梯度训练。

据田渊栋学者在知乎发表的想法,我们可以得知,这篇论文原来获得过一个Weak Accept,经过他与评审rebuttal,将其改为了Accept,这在某种程度上说明了好的rebuttal的重要性,也说明只要你有“理”,就别怕!

此外,发表在ICML 2011的论文“Bayesian Learning via Stochastic Gradient Langevin Dynamics”获得了时间检验奖,作者是来自加利福尼亚大学的Max Welling(现在是高通荷兰公司技术副总裁)和伦敦大学学院的Yee Whye Teh(中文名字郑宇怀,现在是牛津大学教授)。
值得一提的是,郑宇怀 1997年于加拿大滑铁卢大学获得计算机科学与数学学士学位,之后在多伦多大学师从Geoffery Hinton,并于2003年获得计算机博士学位。他还是Hinton那篇划时代论文《A fast learning algorithm for deep belief nets》的署名作者之一。
获奖论文一览
杰出论文奖:去中心化训练的极限在哪里?

论文标题:"Optimal Complexity in Decentralized Training"
作者:Yucheng Lu, Christopher De Sa
机构:康奈尔大学
论文地址:http://proceedings.mlr.press/v139/lu21a.html
去中心化(Decentralization)是扩展并行机器学习系统的一种有效方法。本文提供了该方法在随机非凸环境下进行复杂迭代的下界。我们的下界表明,许多现有的分散训练算法(如D-PSGD)在已知收敛速度方面存在理论差距。通过构造并证明这个下界是合理的和可实现的,我们进一步提出了DeTAG,这是一种实用的gossip风格的去中心化算法,只需要一个对数间隔就可以达到下界。本文将DeTAG算法与其他分散算法在图像分类任务上进行了比较,结果表明,DeTAG算法比基线算法具有更快的收敛速度,特别是在非缓冲数据和稀疏网络中。
荣誉提名奖之一:离散分布的可伸缩抽样

论文标题:"Oops I Took A Gradient: Scalable Sampling for Discrete Distributions"
作者:Will Grathwohl, Kevin Swersky, Milad Hashemi, David Duvenaud, Chris Maddison
机构:多伦多大学,谷歌大脑
论文地址:http://proceedings.mlr.press/v139/grathwohl21a.html
本文针对离散概率模型,提出了一种通用的、可扩展的近似抽样策略。该方法利用似然函数对离散输入的梯度来更新Metropolis-Hastings采样。实验表明,这种方法在高难度设置中,要优于一般的采样器,例如伊辛模型,波特模型,受限玻尔兹曼机,隐马尔可夫模型。本文还展示了改进的采样器,用于训练基于高维离散图像数据的深层能量模型。这种方法优于变分自动编码器和现有的基于能量的模型。此外,本文提供的边界,表明该方法在更新局部的采样器类中是接近最优的。
荣誉提名奖之二:为什么非对比自监督学习效果好?

论文题目:"Understanding self-supervised learning dynamics without contrastive pairs"
作者:Yuandong Tian、Xinlei Chen、Surya Ganguli
机构:FAIR,斯坦福大学
论文地址:http://proceedings.mlr.press/v139/tian21a.html
一般而言,对比自监督学习(SSL)通过最小化同一数据点(正对)的两个增强视图之间的距离和最大化不同数据点(负对)的视图来学习表征,而最近的非对比SSL(如BYOL和SimSiam)的研究表明,在没有负配对的情况下,使用额外的可学习预测器(learnable predictor)和停止梯度操作(stop-gradient operation),可以使模型性能更佳。一个基本的问题出现了:为什么这些方法没有引发崩溃的平凡的表征?
本文通过一个简单的理论研究回答了该问题,并提出了新的方法DirectPred,它不需要梯度训练,直接根据输入的统计信息来设置线性预测。在ImageNet上,它与更复杂的BatchNorm(两个线性层)预测器性能相当,在300个epoch的训练中比线性预测器高2.5%(在60个epoch中高5%)。DirectPred方法,来源于我们对简单线性网络中非对比SSL的非线性学习动力学的理论研究。这项研究提供了非对比SSL方法如何学习的概念性见解,如何避免表征崩溃,以及预测网络、停止梯度、指数移动平均数和权重衰减等因素如何发挥作用。此外,本文还提供了该方法在STL-10和ImageNet上的消融研究结果。
荣誉提名奖之三:倒向随机微分方程结合张量格式的回归型方法

论文标题:"Solving high-dimensional parabolic PDEs using the tensor train format"
作者:Lorenz Richter 、Leon Sallandt、Nikolas Nüsken
机构:德国柏林自由大学,德国波茨坦大学等
论文地址:http://proceedings.mlr.press/v139/richter21a.html
高维偏微分方程的应用在经济、科学和工程等研究中普遍存在。然而,由于传统的基于网格的方法易受到维数灾难的影响,该方程在数值处理上面临着巨大的挑战。在本文中,我们认为,张量训练为抛物型偏微分方程提供了一个更合理的近似框架:将倒向随机微分方程和张量格式的回归型方法相结合,有望利用潜在的低秩结构,实现压缩和高效计算。
遵循这一范式,我们开发了新的迭代方案,包括显式和快速(或隐式和准确)的更新。实验证明,与最先进的基于神经网络的方法相比,我们的方法在精确度和计算效率之间取得了一个良好的折中。
时间检验奖:随机梯度朗格文动力学

论文标题:"Bayesian Learning via Stochastic Gradient Langevin Dynamics"
作者:Max Welling、郑宇怀
机构(原):加利福尼亚大学、伦敦大学学院
论文地址:https://www.cse.iitk.ac.in/users/piyush/courses/tpmi_winter21/readings/sgld.pdf
本文中提出了一个新的框架,在small mini-batches中迭代学习的基础上,可以用于从大规模数据集中学习。通过在标准的随机梯度优化算法中加入适量的噪声,论文证明,当anneal the stepsize,迭代将收敛到真实后验分布的样本。这种优化和贝叶斯后验抽样之间的无缝过渡提供了一个内在的保护,防止过度拟合。此外,还提出了一种实用的后验统计蒙特卡罗估计方法,它可以监控 “抽样阈值”,并在超过该阈值后收集样本。最后,将该方法应用于三种模型:高斯混合模型、逻辑回归模型和自然梯度的ICA模型。
具体而言,本文提出了一种基于大规模数据集的贝叶斯学习方法。将随机优化似然的Robbins-Monro型算法与Langevin动态相结合,Langevin动态在参数更新中注入噪声,使得参数的轨迹收敛到完全后验分布,而不仅仅是最大后验分布。由此产生的算法开始类似于随机优化,然后自动过渡到使用Langevin动力学模拟后验样本的算法。
论文接收一览
ICML 2021大会上,香港科技大学教授、大会程序主席张潼通过一则视频展示了今年的论文收录情况。
数据显示,今年接收论文投稿5513篇,其中长论文166篇,短论文1017篇。整体来看,ICML近五年来投稿数量持续走高,并于2020年首次突破5000关卡。
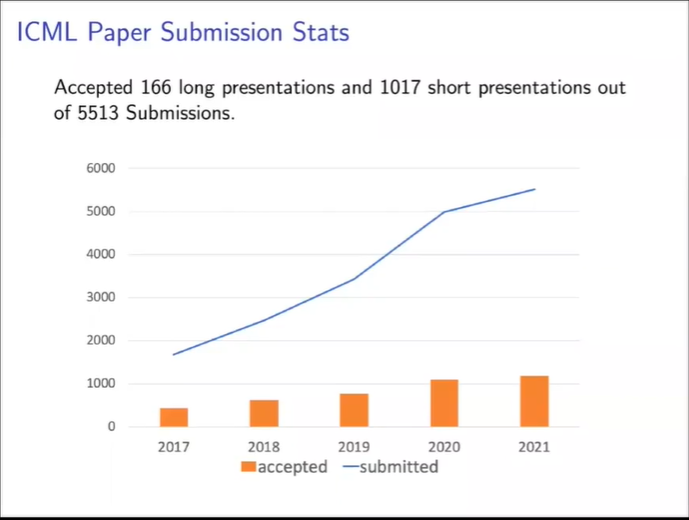
两个月前,ICML组委会为了保证AC/SAC 接收标准和论文质量,宣布将接收论文砍掉10%。今年共接受论文1184篇,接收率21.4%,为近五年来最低。
今年的录用论文涉及深度学习、算法、应用、强化学习、隐私、理论、概率方法和社会方面等8个研究方向。
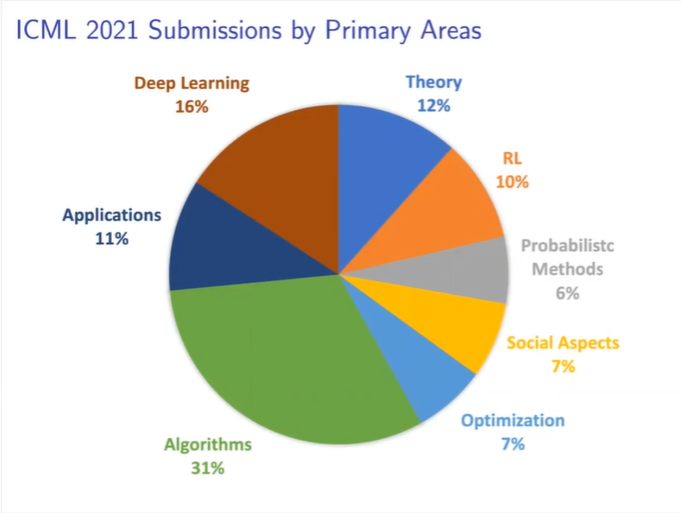
其中,算法方面的论文一枝独秀,提交的论文数量占比31%,比第二名深度学习,数量高出近一倍。排名Top3的算法、深度学习、理论三大机器学习热门方向,占据了总接收论文的50%以上。相对冷门的隐私、概率方法、社会方面等也有20%的论文被接收。

哪个领域接受率最强?理论工作32%,强化学习27%,概率方法26%,社会角度24%,优化22%,算法19%,应用和深度学习只有18%。
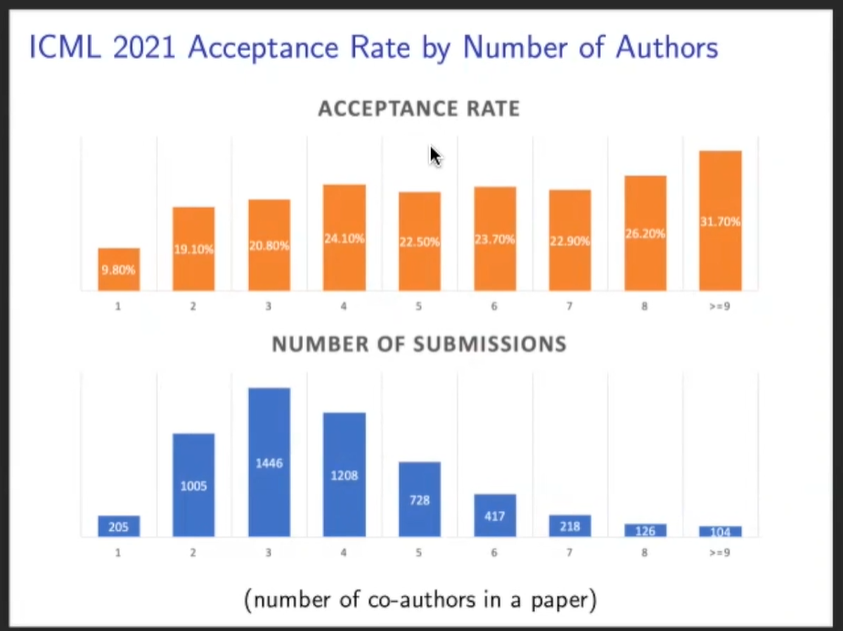
一篇论文往往有好几位合著者,似乎论文接收率有相关关系。据统计数据,如果一篇论文有着大于9位的作者,那么它将有1/3的概率被接收,如果仅有1位作者,论文接受率不到1/10;另外,8位作者和4位作者,虽然在人数上相差一倍,但是接受率仅相差2%。
在所有的提交论文中,有1446篇论文包含3位作者,大于或等于9位作者的论文数只有104篇;此外,还有205位作者单独提交了论文,由2位作者合写的论文数有1005篇。
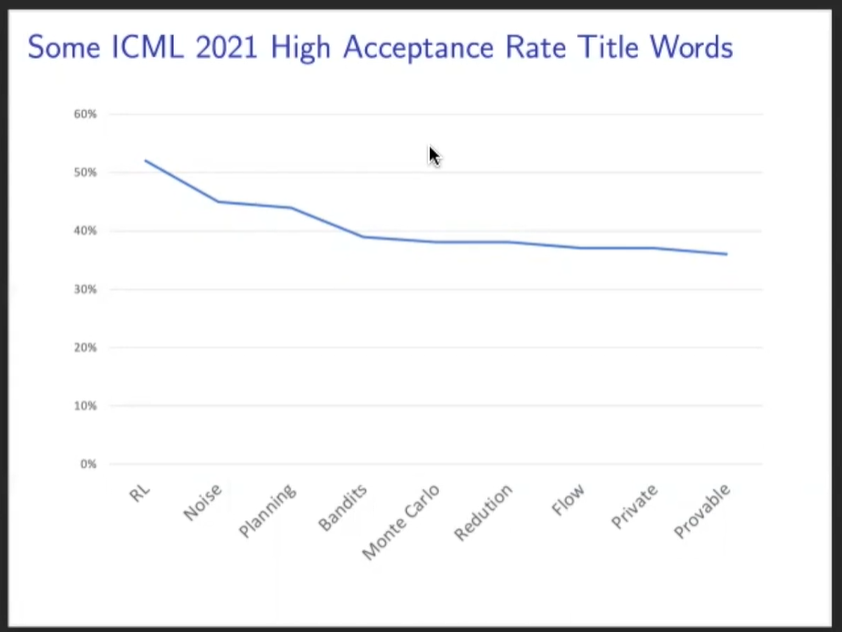
经过统计,今年的ICML 2021接收的论文中,如果标题中带有这么几个词,将会有较高的接收率:强化学习、噪音、规划、Bandits、蒙特卡洛、流、隐私.......
相关链接:
https://icml.cc/virtual/2021/awards_detail
https://mp.weixin.qq.com/s/_wrmuqhPSX7-JRx-eFJiwQ
https://watch.videodelivery.net/b504b00c401ac24e41ab297a9f3781b9
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()
这篇关于ICML 2021杰出论文公布!上海交大校友摘得桂冠!田渊栋rebuttal加分论文获荣誉提名...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


