本文主要是介绍翻译--ASYNCHRONOUS FEDERATED LEARNING IN PYSYFT(PYSYFT中的异步联邦学习),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这篇文章中,我们提供了使用PySyft应用联邦学习的展示。PySyft是一个开源python库,用于从OpenMined社区进行安全和私有的深度学习。它将私人数据与模型训练分离。
在联邦学习中,每个边缘设备都处理自己的数据以进行训练,避免将其发送给另一个实体,从而保护了隐私。此外,训练阶段的主要处理工作是在设备上完成的,因此与在数据中心进行训练相比,减少了必要的带宽和数据处理。所有设备都可以通过组合其AI模型相互学习,这可以由可以放置在云中或边缘的中央协调节点完成。由于从设备发出的信息是最终的AI模型更新,因此泄漏用户数据的风险很低。像技术安全的聚集和差分隐私有助于提高隐私。
在此示例中,训练将在不同的边缘设备上执行。在我们的实验室中,我们为此使用了Nvidia Jetson Tx2设备。训练任务是MNIST数据集上的图像分类任务,其中包含0-9范围内的手写数字图像。训练数据集的样本以这样一种方式分配给三个工作人员(分别称为Alice,Bob和Charlie),即每个设备只能看到一定范围的数字,并且只能使用这些数字来训练模型。由于结合了学习,即使在每个训练步骤中只有一部分数字可用,最终获得的模型仍将能够识别所有数字。
架构
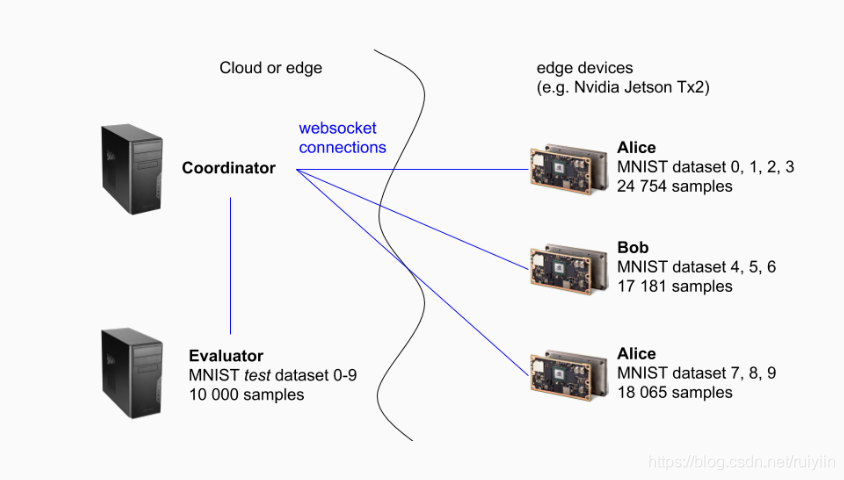
协调节点
协调节点是将与工作节点进行沟通并协调联邦训练的实例。它从每个工作人员那里接收本地更新,并平均模型的权重,并使用生成的平均(组合)模型更新工作人员。
它还创建websocket客户端实例,这些实例连接到在工作程序和评估程序上启动的websocket服务器。
工作节点
工作节点是训练数据(一部分数字)的一部分的所有者,他们在本地训练模型并将更新发送给协调节点。
他们启动一个websocket服务器并等待连接。
评估程序评估程序
保存MNIST数据集的测试数据集,并带有所有数字的表示形式。它负责定期评估经过训练的模型,不执行任何训练。
当开始训练参与者Alice,Bob,Charlie和Testing(评估者)时,他们将打印可用数字的计数,请参见下面的输出。第一个输出是来自工作人员Alice的,显示它有5923个数字0的示例,6742个数字1的示例...,而没有4-9的数字示例。Alice上可用的示例总数为24754个示例。
$ python run_websocket_server.py --id alice --port 8777 --host 0.0.0.0
MNIST dataset (train set), available numbers on alice:0: 59231: 67422: 59583: 61314: 05: 06: 07: 08: 09: 0
datasets: {'mnist': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7fdbcd433748>}
len(datasets[mnist]): 24754
Bob的输出显示它总共有17181个示例,所有示例都显示数字4-6,而0-3和7-9范围内没有数字。
$ python run_websocket_server.py --id bob --port 8778 --host 0.0.0.0
MNIST dataset (train set), available numbers on bob:0: 01: 02: 03: 04: 58425: 54216: 59187: 08: 09: 0
datasets: {'mnist': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7fea69678748>}
len(datasets[mnist]): 17181
charlie的输出显示它只有7-9位数字,总共有18065个示例。
$ python run_websocket_server.py --id charlie --port 8779 --host 0.0.0.0
MNIST dataset (train set), available numbers on charlie:0: 01: 02: 03: 04: 05: 06: 07: 62658: 58519: 5949
datasets: {'mnist': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7f3c6200c748>}
len(datasets[mnist]): 18065
最终,评估者拥有MNIST数据集的测试集。它包含10000个示例,分布在所有数字0-9之间。
$ python run_websocket_server.py --id testing --port 8780 --host 0.0.0.0 --testing
MNIST dataset (test set), available numbers on testing:0: 9801: 11352: 10323: 10104: 9825: 8926: 9587: 10288: 9749: 1009
datasets: {'mnist_testing': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7f3e5846a6a0>}
训练
现在让我们开始异步联邦训练。为此,协调节点创建了到每个工作人员和评估者的Websocket连接。
然后创建一个模型,在我们的示例中是一个具有2个卷积层和2个完全连接层的神经网络。该模型开始时完全未经训练,具有随机权重值。
然后,演示通过执行40次训练回合来获得训练过的模型。
一轮训练包含以下步骤:
- 将模型和训练配置发送给每个工作节点
- 并行地,每个工作节点根据训练配置(优化器,损失函数,训练的时期/批次,批次大小等)在其私有数据上训练模型。
- 工作节点完成训练后,会将改进后的模型发送回协调节点
- 协调节点等待所有改进的模型,一旦获得它们,它将对模型执行联合平均,以获得一个改进的组合模型。改进后的模型将发送给工作节点进行下一轮训练。
每十轮训练将模型(以及工作节点返回的单个模型)发送给评估者。评估人员可以预测测试数据集的目标,并计算准确性和平均损失。
出于演示目的,评估器还显示了模型返回的不同数字的百分比。这样做的目的是表明,工作节点返回的第一个模型只会返回他们在本地可用于训练的数字。然而,经过一些迭代后,组合模型以及工作人员返回的各个模型都将预测所有数字。
输出示例如下所示。它显示了训练如何进行40轮训练,并在第1、11、21、31和40轮之后评估了模型。在第1轮之后的评估表明,Alice,Bob和Charlie的每个模型都将测试数据集的所有数字分类为如果仅包含其数字子集。爱丽丝将测试数据集的所有数字分类为数字0-3(如下所示的百分比100%),总精度为28.75%。爱丽丝的模型比鲍勃和查理的模型表现更好。这是因为Alice有4位数字可供训练,而Bob和Charlie分别有3位数字。
经过40轮训练的联盟模型的准确率达到95.9%。
$ python run_websocket_client.py
Training round 1/40
Evaluating models
Model update alice: Percentage numbers 0-3: 100%, 4-6: 0%, 7-9: 0%
Model update alice: Average loss: 0.0190, Accuracy: 2875/10000 (28.75%)
Model update bob: Percentage numbers 0-3: 0%, 4-6: 100%, 7-9: 0%
Model update bob: Average loss: 0.0275, Accuracy: 958/10000 (9.58%)
Model update charlie: Percentage numbers 0-3: 0%, 4-6: 0%, 7-9: 100%
Model update charlie: Average loss: 0.0225, Accuracy: 1512/10000 (15.12%)
Federated model: Percentage numbers 0-3: 0%, 4-6: 86%, 7-9: 12%
Federated model: Average loss: 0.0179, Accuracy: 1719/10000 (17.19%)
Training round 2/40
Training round 3/40
Training round 4/40
Training round 5/40
Training round 6/40
Training round 7/40
Training round 8/40
Training round 9/40
Training round 10/40
Training round 11/40
Evaluating models
Model update alice: Percentage numbers 0-3: 79%, 4-6: 11%, 7-9: 9%
Model update alice: Average loss: 0.0093, Accuracy: 5747/10000 (57.47%)
Model update bob: Percentage numbers 0-3: 15%, 4-6: 76%, 7-9: 7%
Model update bob: Average loss: 0.0134, Accuracy: 5063/10000 (50.63%)
Model update charlie: Percentage numbers 0-3: 5%, 4-6: 0%, 7-9: 94%
Model update charlie: Average loss: 0.0225, Accuracy: 3267/10000 (32.67%)
Federated model: Percentage numbers 0-3: 40%, 4-6: 22%, 7-9: 36%
Federated model: Average loss: 0.0032, Accuracy: 8693/10000 (86.93%)
Training round 12/40
Training round 13/40
Training round 14/40
Training round 15/40
Training round 16/40
Training round 17/40
Training round 18/40
Training round 19/40
Training round 20/40
Training round 21/40
Evaluating models
Model update alice: Percentage numbers 0-3: 60%, 4-6: 18%, 7-9: 21%
Model update alice: Average loss: 0.0050, Accuracy: 7808/10000 (78.08%)
Model update bob: Percentage numbers 0-3: 31%, 4-6: 54%, 7-9: 14%
Model update bob: Average loss: 0.0069, Accuracy: 7241/10000 (72.41%)
Model update charlie: Percentage numbers 0-3: 21%, 4-6: 6%, 7-9: 72%
Model update charlie: Average loss: 0.0094, Accuracy: 5671/10000 (56.71%)
Federated model: Percentage numbers 0-3: 41%, 4-6: 28%, 7-9: 30%
Federated model: Average loss: 0.0017, Accuracy: 9427/10000 (94.27%)
Training round 22/40
Training round 23/40
Training round 24/40
Training round 25/40
Training round 26/40
Training round 27/40
Training round 28/40
Training round 29/40
Training round 30/40
Training round 31/40
Evaluating models
Model update alice: Percentage numbers 0-3: 59%, 4-6: 21%, 7-9: 19%
Model update alice: Average loss: 0.0044, Accuracy: 8078/10000 (80.78%)
Model update bob: Percentage numbers 0-3: 34%, 4-6: 48%, 7-9: 16%
Model update bob: Average loss: 0.0050, Accuracy: 7755/10000 (77.55%)
Model update charlie: Percentage numbers 0-3: 23%, 4-6: 9%, 7-9: 67%
Model update charlie: Average loss: 0.0124, Accuracy: 6195/10000 (61.95%)
Federated model: Percentage numbers 0-3: 41%, 4-6: 26%, 7-9: 31%
Federated model: Average loss: 0.0014, Accuracy: 9449/10000 (94.49%)
Training round 32/40
Training round 33/40
Training round 34/40
Training round 35/40
Training round 36/40
Training round 37/40
Training round 38/40
Training round 39/40
Training round 40/40
Evaluating models
Model update alice: Percentage numbers 0-3: 56%, 4-6: 23%, 7-9: 20%
Model update alice: Average loss: 0.0041, Accuracy: 8218/10000 (82.18%)
Model update bob: Percentage numbers 0-3: 33%, 4-6: 45%, 7-9: 20%
Model update bob: Average loss: 0.0039, Accuracy: 8155/10000 (81.55%)
Model update charlie: Percentage numbers 0-3: 32%, 4-6: 17%, 7-9: 50%
Model update charlie: Average loss: 0.0047, Accuracy: 7802/10000 (78.02%)
Federated model: Percentage numbers 0-3: 41%, 4-6: 29%, 7-9: 29%
Federated model: Average loss: 0.0011, Accuracy: 9592/10000 (95.92%)
如果您想自己运行代码,可以尝试使用此jupyter笔记本。
何时可以进行联邦学习?
在进行联邦学习时,我们还必须考虑其要求。在数据自然分布并且您无法或不希望将数据集中在一个位置的情况下,它很有用。联邦学习解决了这一需求,并将训练中计算量大的部分移到了资源有限的边缘设备上。尽管每个单独的设备仅负责总工作量的一小部分,但是资源消耗是在每种情况下都必须评估的约束。
我们还必须考虑该体系结构所依赖的沟通渠道,因为工作节点需要在训练阶段与协调节点进行沟通。在不可靠的边缘环境(连接性和安全性是必须解决的挑战)上工作时,这变得更加棘手。
在Midokura,我们使用边缘虚拟化平台(EVP)照顾部署部分,将AI应用程序组件作为分布式体系结构的微服务进行处理,并实现工作负载的垂直放置,以便用户可以设计工作负载的处理位置。该平台负责边缘边缘或边缘云场景的通信通道(联邦学习所依赖),提供灵活的连接性,工作负载优先级(QoS)和安全路径。
结论
我们已经看到了一个示例,该示例说明了如何在边缘设备中使用本地(专用)数据来联合训练神经网络而不将数据发送到中央位置。联邦学习使每个客户端都可以将其数据保存在本地,并通过汇总和平均本地更新来在协调节点上训练共享模型。
尽管设计涉及中央协调节点,但也可以将其放置在边缘中。请注意,此节点看不到训练数据,只能看到生成的AI模型(或更新)。该中央节点也可以放置在边缘设备之一中,从而无需云实例。
本文翻译自OpenMined官方博客,链接地址:https://blog.openmined.org/asynchronous-federated-learning-in-pysyft/
- 这篇文章的作者:
-
西尔维亚·甘迪(Silvia Gandy)
机器学习专家和软件开发人员
这篇关于翻译--ASYNCHRONOUS FEDERATED LEARNING IN PYSYFT(PYSYFT中的异步联邦学习)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






