本文主要是介绍利用ArcGIS统计各地区内路网密度(附路网练习数据下载),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

实验数据:成都市行政区划、成都市路网数据(国家基础地理信息数据库)文末有数据下载链接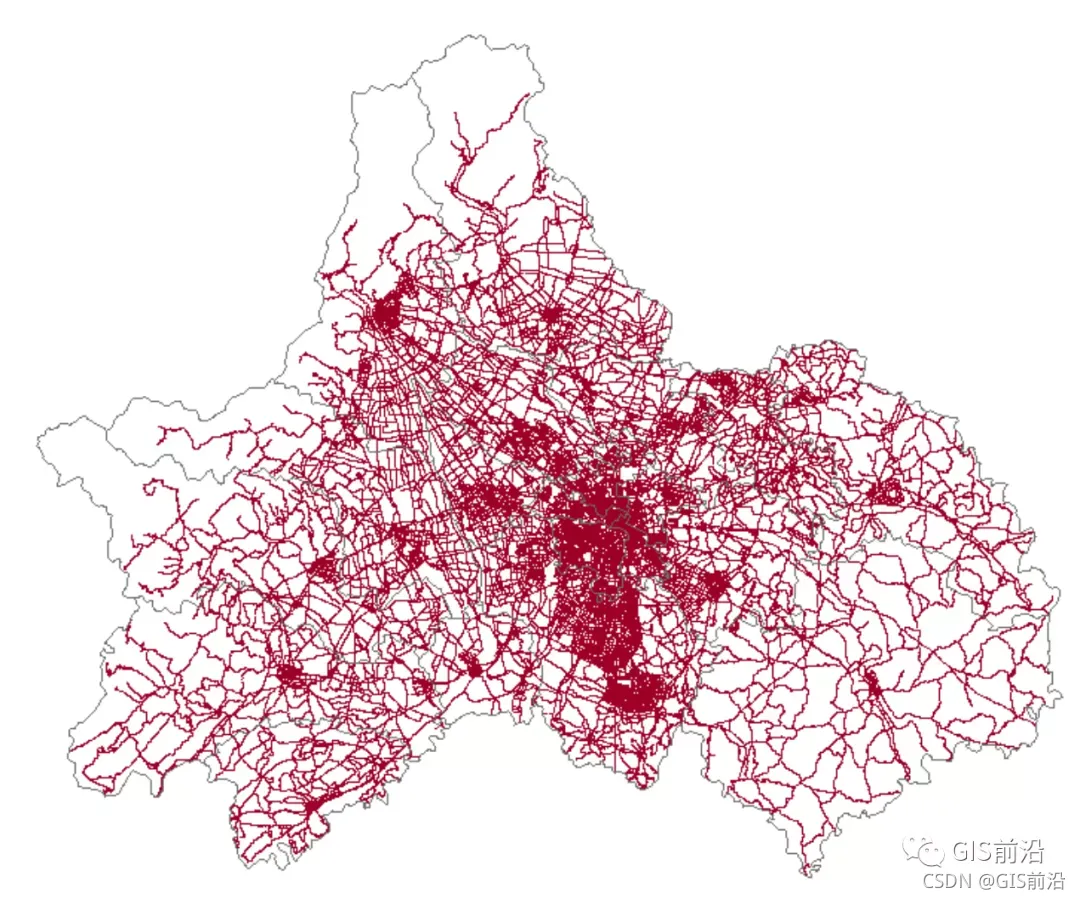
关于路网数据,除了国家基础地理信息数据库,也可以从OSM获取(全国矢量shp数据:行政区划,县界,道路,河流…都可下载),不过,最最重要的,记得开始先把数据地理坐标系转换为投影坐标系再开始计算。
1、路网密度=【道路长度/区域面积】,所以我们需要先计算出路网长度和各个行政区域的面积。在行政区划数据和路网数据的属性表内分别添加area和len两个字段,代表面积和长度,然后右键计算几何,分别计算面积和长度(单位统一为km²)。
2、将行政区划和路网数据进行相交,这样每段路都能标识到它属于哪个区。len是长度,area是面积,这是在第一步中添加的字段。除了相交还可以通过【标识】工具来操作,将行政区划信息标识到每段道路上。这里用相交,输出结果后打开属性表可以看到,每条道路都有区划信息。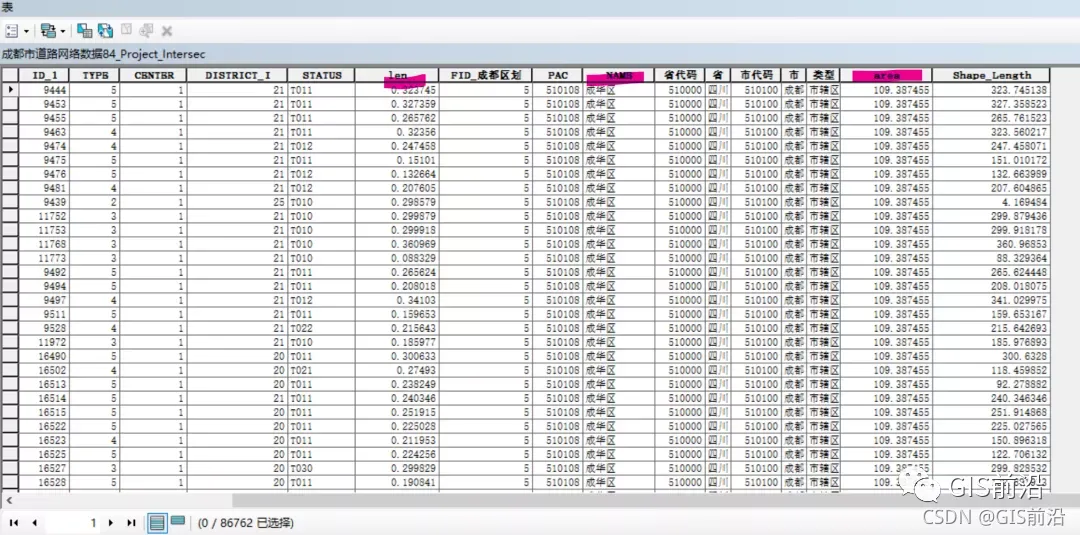
3、选择【NAME】字段右键汇总统计,统计的是len长度总和,输出后是一个dBASE表(右图)。这一步是为了统计各行政区内的道路总长度。
4、连接图层。右键行政区划的图层—连接和关联,以NAME字段为连接字段,将上一步的汇总表的信息连接至行政区划图层中。如下图,道路长度和面积信息都计算出来了。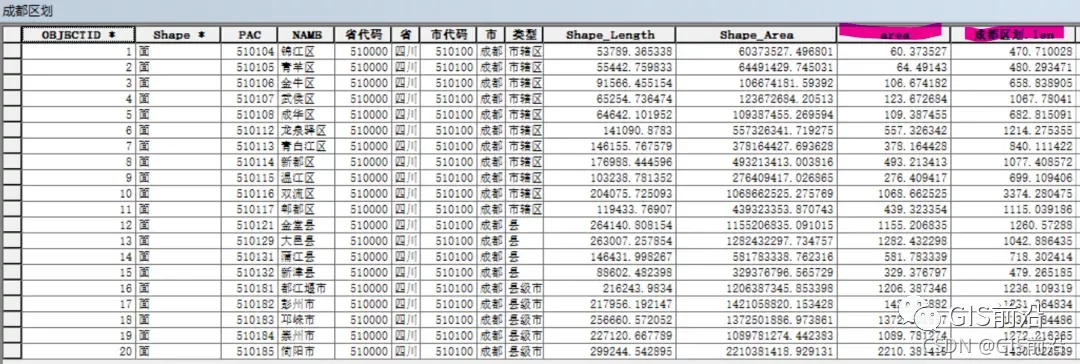
5、路网密度=【道路长度/区域面积】,添加字段-字段计算器用len/area计算便得到每个区的路网密度。
最后在符号系统里稍微弄一下样子就可以了。可以看到,武侯区路网密度最大,为8.63km/km²,其次是锦江区7.8km/km²,大邑县是最小的,0.81 km/km²。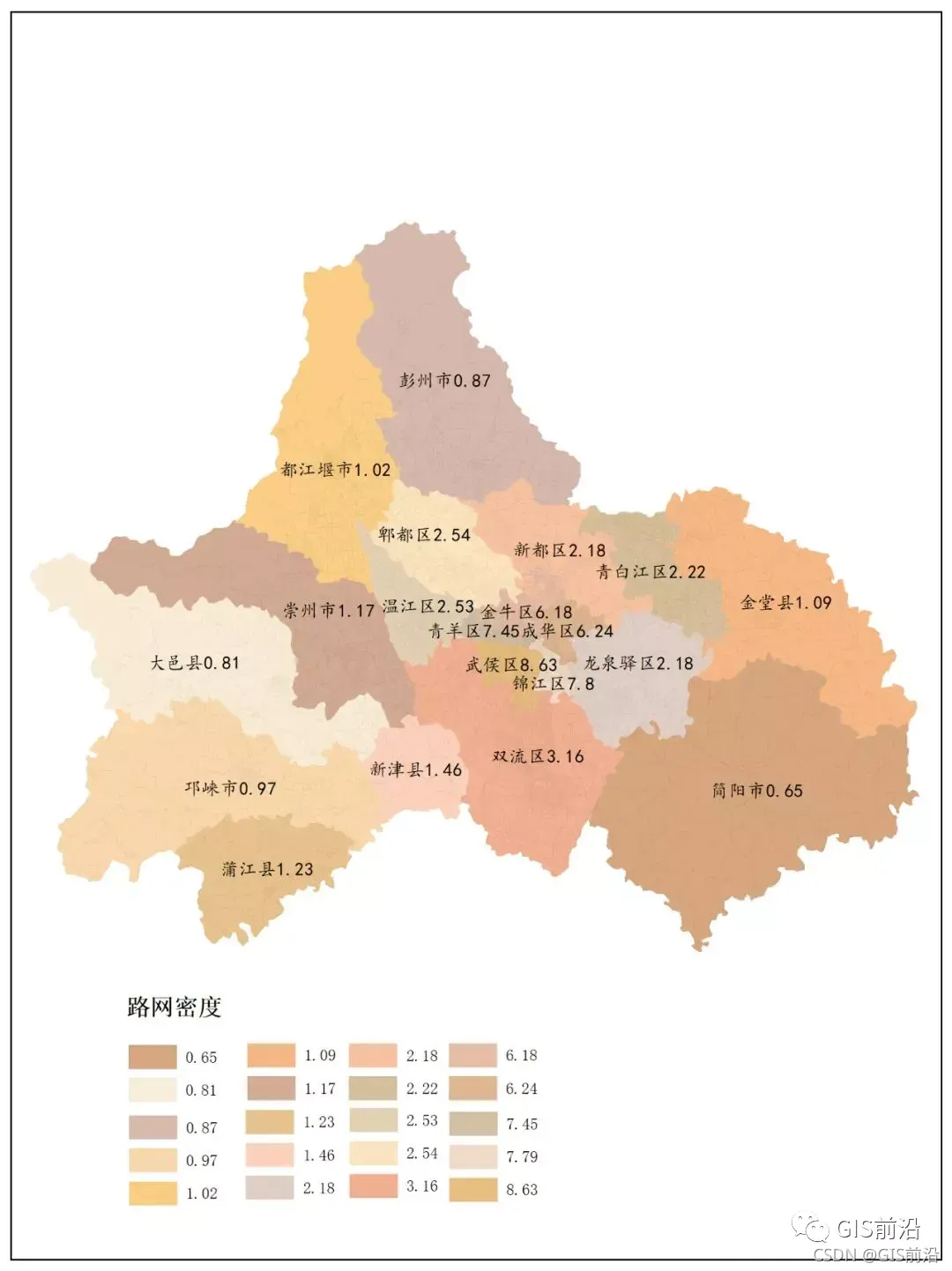
- END -

这篇关于利用ArcGIS统计各地区内路网密度(附路网练习数据下载)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






