本文主要是介绍WebMagic+Selenium爬取网易云音乐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
**在阅读本文章之前需要您具备一些WebMagic和Selenium的知识
像网易云音乐、QQ音乐等音乐网站,都会对音乐地址进行加密
这里提供给大家一个外链转换的网站
https://link.hhtjim.com/

找到网易云这一栏
id后面的这一堆数字就是歌曲的id
最后生成的https://link.hhtjim.com/163/5146554.mp3即为该首音乐的外链地址
打开看一看

果然为音乐的源地址
地址有什么规律呢,我们再输入几个音乐的id

规律很明显了
歌曲源地址为https://link.hhtjim.com/163/******.mp3
那么我们的思路就很清晰了,通过歌单页面获取音乐id,将id拼接为外链地址,进入该地址下载歌曲
代码走起
一、导入依赖
<dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>3.4.0</version></dependency><dependency><groupId>us.codecraft</groupId><artifactId>webmagic-core</artifactId><version>0.7.3</version></dependency><dependency><groupId>us.codecraft</groupId><artifactId>webmagic-extension</artifactId><version>0.7.3</version></dependency>
二、解析页面
这里我选取了网易云音乐的top榜单
 https://music.163.com/#/discover/toplist
https://music.163.com/#/discover/toplist
现在开始对音乐列表进行解析,相信了解爬虫的朋友对解析页面丝毫不陌生
F12观察一下这些歌曲在什么地方呢

原来存放在class=“m-table m-table-rank”的table里,每个tr就是一首歌曲
那么table的xpth为://table[@class=‘m-table m-table-rank’]
验证一下xpth是否正确

结果竟然为空?是我们的xpth写错了吗?
其实我们并没有错,而是这个table藏在了框架iframe里,导致外部程序找不到他
那我们进入到框架找他不就完事了
这就用到了selenium,它提供了方法可以进入到框架里面
首先确定框架是哪个

可以通过iframe的id和name确定
也可以用xpth定位到节点
//*****找到歌单列表所在的框架WebElement iframelement = driver.findElement(By.xpath("//iframe[@id='g_iframe']"));//*****进入框架driver.switchTo().frame(iframelement);
进入框架就可以对歌曲信息随意解析了
我们先找到table
//找到存放歌曲的tableWebElement table= wait.until(ExpectedConditions.presenceOfElementLocated(By.xpath("//table[@class='m-table m-table-rank']")));
每首歌曲的信息在tr标签里
找到所有tr节点
//获取所有歌曲所在的tr节点List<WebElement> trs = table.findElements(By.xpath("//tbody/tr"));System.out.println("歌单共有歌曲"+trs.size()+"首");
到了最重要的环节了
- 获取歌曲id和name
- 拼接外链地址https://link.hhtjim.com/163/id.mp3
以第一首歌曲为例

歌曲id和name太明显了
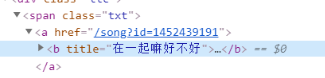
标签a的xpth:.//span[@class=‘txt’]/a
歌曲id在a标签的href属性里
同理歌名位于b标签的title属性
上面的"."的含义为“当前”
结合这段代码tr.findElement(By.xpath(".//span[@class='txt']/a"))
他的含义为:当前这个tr里的class为txt的span下的a节点
List<WebElement> trs = table.findElements(By.xpath("//tbody/tr"));
for (WebElement tr : trs) {//获取歌曲idString id = tr.findElement(By.xpath(".//span[@class='txt']/a")).getAttribute("href").split("=")[1];//获取歌曲nameString name = tr.findElement(By.xpath(".//span[@class='txt']/a/b")).getAttribute("title").replace("\n", "");//拼接外链地址String realUrl="https://link.hhtjim.com/163/" + id + ".mp3";//****将外链地址加入到url队列中,等待被解析page.addTargetRequest(realUrl);//将歌曲id与name存入mapmap.put(id,name);}
通过上述代码我们获取到了音乐id和name,并且将外链地址加入到了请求队列中。
最后就是解析存在于请求队列中的每个url页面
只要是外链地址所在的url则进行下载
完整代码
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;import java.io.*;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class Music163 implements PageProcessor {//定义存放音乐id和name的字典Map<String,String> map=new HashMap<>();/*** 用于下载音乐的方法* @param page page*/public void download(Page page){//在桌面创建盛放音乐的文件夹File directory = FileSystemView.getFileSystemView().getHomeDirectory();File file = new File(directory.getPath()+"\\网易云音乐Top");if(!file.exists()){file.mkdirs();}byte[] bytes = page.getBytes();//将页面数据转换为二进制数据存入byte数组FileOutputStream outputStream=null;try {String url = page.getUrl().toString();/*通过字符串截取得到url的音乐id部分例如:https://link.hhtjim.com/163/123456.mp3最后得到的id为123456*/String id=url.substring(url.lastIndexOf("/")+1,url.lastIndexOf("."));//通过id确定歌名String name=map.get(id);//获取输入流outputStream = new FileOutputStream(file.getAbsolutePath()+"\\"+name+".mp3");outputStream.write(bytes);outputStream.flush();System.out.println("《"+name+"》下载完成");} catch (Exception e) {e.printStackTrace();}finally {if(outputStream!=null){try {outputStream.close();} catch (IOException e) {e.printStackTrace();}}}}/*** 解析页面* 用于获取音乐id和名称* 通过id构造音乐外链地址* @param page page*/public void addRealMusicUrl(Page page){//创建谷歌浏览器驱动WebDriver driver = new ChromeDriver();//进入页面driver.get(page.getUrl().toString());//*****找到歌单列表所在的框架WebElement iframelement = driver.findElement(By.xpath("//iframe[@id='g_iframe']"));//*****进入框架driver.switchTo().frame(iframelement);/*实际场景中可能会发生页面节点没有加载出来但是程序已经跑完的情况可以利用显示等待,等待节点加载出来程序继续运行但是不能无限等待这里设置等待时长为5秒超过这个时间就会抛出异常*/WebDriverWait wait = new WebDriverWait(driver, 5);//等待存放歌曲的table节点出现WebElement table = wait.until(ExpectedConditions.presenceOfElementLocated(By.xpath("//table[@class='m-table m-table-rank']")));//获取所有歌曲所在的tr节点List<WebElement> trs = table.findElements(By.xpath("//tbody/tr"));System.out.println("歌单共有歌曲"+trs.size()+"首");for (WebElement tr : trs) {//获取歌曲idString id = tr.findElement(By.xpath(".//span[@class='txt']/a")).getAttribute("href").split("=")[1];//获取歌曲nameString name = tr.findElement(By.xpath(".//span[@class='txt']/a/b")).getAttribute("title").replace("\n", "");System.out.println(id);//拼接外链地址String realUrl="https://link.hhtjim.com/163/" + id + ".mp3";//****将外链地址加入到请求队列中,等待被解析page.addTargetRequest(realUrl);//将歌曲id与name存入mapmap.put(id,name);}}
/*** 实现WebMagic框架的process方法* 每次解析队列中的请求都会调用该方法* @param page*/public void process(Page page) {//网易云外连格式https://link.hhtjim.com/163/音乐Id.mp3if(page.getUrl().toString().contains("mp3")){//如果页面的url含有mp3,则为音乐源地址,下载download(page);}else {//解析歌单页面addRealMusicUrl(page);}}/*对爬虫进行配置设置超时时间和编码方式*/private Site site=Site.me().setTimeOut(5000).setCharset("utf8");public Site getSite() {return site;}public static void main(String[] args) {String startUrl="https://music.163.com/#/discover/toplist";//起始歌单的url//启动爬虫Spider.create(new Music163()).addUrl(startUrl).run();}
}
最后瞅一瞅文件夹

果然爬到了!!
总结一下
- 导入WebMgic和Selenium依赖
- 解析页面,找到音乐的id进行外链地址拼接,然后将外链地址加入到请求队列中
- 将url为外链地址的页面进行下载并保存为MP3格式
第一次写文章没有经验,如果有不足之处望批评指正。
这篇关于WebMagic+Selenium爬取网易云音乐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






