webmagic专题

WebMagic爬虫框架及javaEE SSH框架将数据保存到数据库(二)
关于一些基本内容可查看上一篇博客:http://blog.csdn.net/u013082989/article/details/51176073 一、首先看一下爬虫的内容: (1)学科类型、课程、课程对应章节、课程对应参考教材(主要是要将课程章节对应到上一级爬取的课程上,还有就是课程教材的爬取比较麻烦,下面会讲到) 课程章节: 课程教材 教材内容 二、实体类的

使用WebMagic爬虫框架及javaEE SSH框架将数据保存到数据库(一)
由于近期做毕设,需要从网站上爬取教学资源,下面实现一个简单的爬虫,并将爬取的数据保存到数据库中。 一:有关爬虫框架的选取,我使用的是WebMagic爬虫框架,中文文档:http://webmagic.io/docs/zh/ 它是一个开源项目,github地址:https://github.com/code4craft/webmagic,之前想用python写爬虫的,也写了一点,但还要学习操作数
Elasticsearch系列(十)----使用webmagic爬取数据导入到ES
webmagic主要有两个文件 一个是对爬取页面进行处理,一个是对页面处理之后的数据进行保存: CSDNPageProcessor package com.fendo.webmagic;import java.io.IOException;import java.net.InetAddress;import java.net.UnknownHostExce

WebMagic高级用法
Maven依赖 <dependencies><dependency><groupId>us.codecraft</groupId><artifactId>webmagic-core</artifactId><version>0.7.3</version></dependency><dependency><groupId>us.codecraft</groupId><artifactId>web

webmagic 爬取https的网站抛avax.net.ssl.SSLHandshakeException异常
webmagic 抓取带有https的网站,抛出的异常javax.net.ssl.SSLHandshakeException。 初步解决办法: 1,在自己的项目中新建httpclient文件夹,新建类HttpClientGenerator, 复制webmagic源码中的 HttpClientGenerator. 2.修改 HttpClientGenerator 的代码,需要修改 buildSSLC
java 爬虫 WebMagic-使用入门
原文出自:http://webmagic.io/docs/zh http://blog.csdn.net/u013510614/article/details/50313835 在WebMagic里,实现一个基本的爬虫只需要编写一个类,实现PageProcessor接口即可。这个类基本上包含了抓取一个网站,你需要写的所有代码。 同时这部分还会介绍如何使用WebMagic的抽取API,以及最常
探索 Java 网络爬虫:Jsoup、HtmlUnit 与 WebMagic 的比较分析
1、引言 在当今信息爆炸的时代,网络数据的获取和处理变得至关重要。对于 Java 开发者而言,掌握高效的网页抓取技术是提升数据处理能力的关键。本文将深入探讨三款广受欢迎的 Java 网页抓取工具:Jsoup、HtmlUnit 和 WebMagic,分析它们的功能特点、优势以及适用场景,以助开发者选择最适合自己项目需求的工具。 2、Jsoup 2.1、简介 Jsoup 是一款 Java 编写
webmagic scheduler源码分析
webmagic scheduler源码分析 项目中使用webmagic作为爬虫爬取框架,需要实现2个功能: 对于一些未爬取到的URL,需要做重试机制,重复爬取,设置爬取次数,直至爬取到网页内容或者达到重试次数。用户点击停止,则停止对剩余URL的爬取。 这二个功能的添加都是对scheduler模块进行改造,webmagic的scheduler模块负责管理待抓取的URL,以及一些去重的工作。W
【Selenium+Webmagic】基于JAVA语言实现爬取js渲染后的页面,附有代码
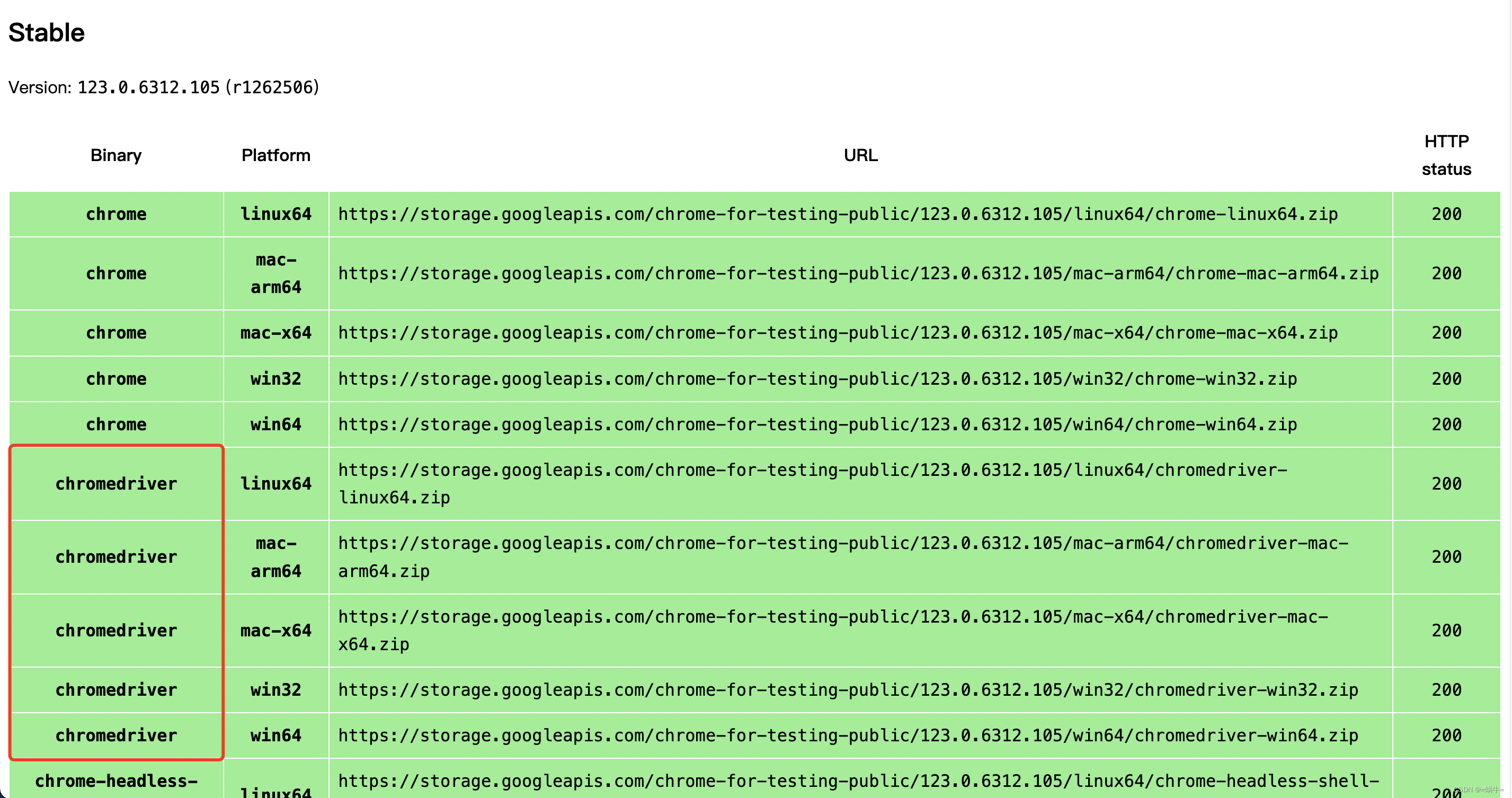
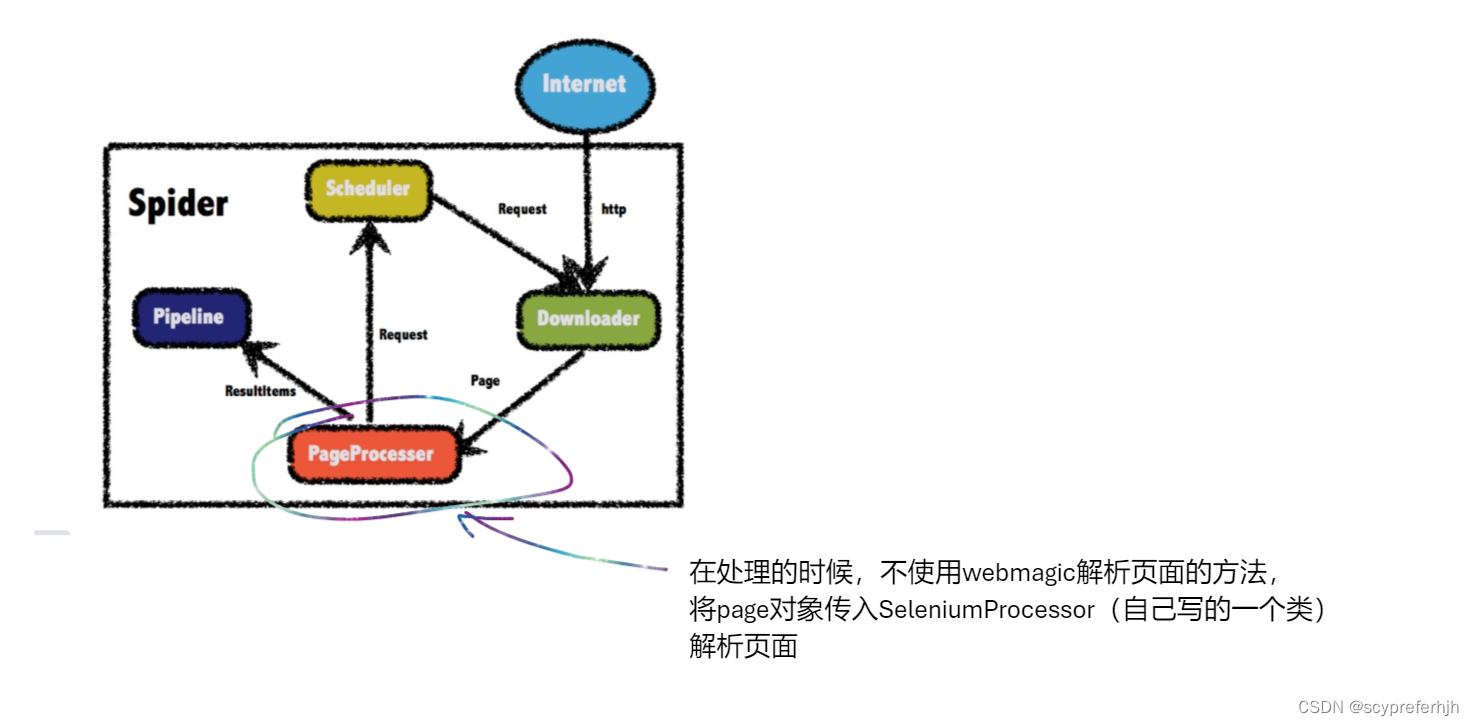
事先声明 笔者最近需要查看一些数据,自己挨个找太麻烦了,于是简单的学了一下爬虫。笔者在这里声明,爬的数据只为学术用,没有其他用途,希望来这篇文章学习的同学能抱有同样的目的。 枪本身不坏,坏的是使用枪的人 效果 基于JAVA语言实现爬取js渲染后的页面,详细教程 下载ChromeDriver下载ChromeDrive以及相对应的Chrome禁止Chrome自动升级第一步:禁用任务

webmagic-爬取51招聘信息
点击资料或前往github查看源码WebMagic 如果是采用@Autowired注入变量,则当前类的实例,必须也是spring 容器注入才能成功注入,应该也采用@Autowired注入,要不就不要new需要注入其他对象的当前类 使用springboot开启定时任务,使用自定义pipeline将数据存储到数据库,根据传入的url获取页面,和jquery相似的选择器方法解析页面存入自己想得到的信
08. Springboot集成webmagic实现网页爬虫
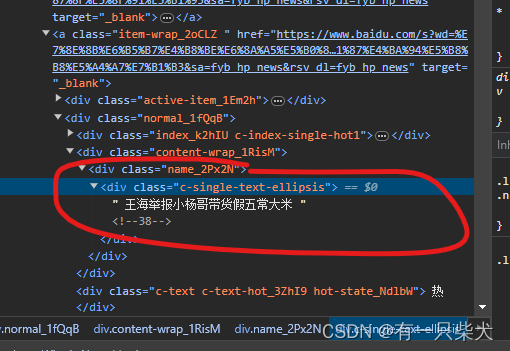
目录 1、前言 2、WebMagic 3、Springboot集成Webmagic 3.1、创建Springboot,并引入webmagic依赖 3.2、定义PageProcessor 3.3、元素选择 3.3.1、F12查看网页元素 3.3.2、元素选择 3.3.3、注意事项 4、小结 1、前言 在信息化的时代,网络爬虫已经成为我们获取和处理大规模网络数据的重要工
webmagic爬取图片
webmagic算是一个国人开发比较简单粗暴的爬虫框架,首页:http://webmagic.io/ 中文文档:http://webmagic.io/docs/zh/posts/ch2-install/ 这次随便找了个小图片网站爬取(大网站没代理怕被封IP):http://www.mmonly.cc/ktmh/hzw/list_34_1.html 分析网站: 要获取这些主要内容的连接

利用WebMagic的Cookie机制进行页面爬取
目前发布的WebMagic的最新版本仍然不支持post请求模拟登陆来抓取页面,但是相信,在后续的版本中,肯定会支持这项功能。那么要抓取登陆后才能看到的页面怎么办? 一、用户自己发送post请求,将获取的cookie设置到Spider中 二、用户使用抓包工具将抓到的cookie设置到Spider中 本文只讨论第二种方式,第一种方式的抓取,博主会在后续的博客中实现 本文抓取慕课网登陆后的

Webmagic 爬虫之通过cookie进行页面登录
介绍: 首先先来介绍下webmagic这个爬虫框架,这个框架是大佬黄义华开源的爬虫框架,用起来非常的顺手, 跟之前用python中的scrapy框架一样,层次非常清晰,可扩展性也是非常的好。文档也比较齐全,并且现在还在一直更新。 优点就说这些,但是也有一些不足,在我学习的过程中,遇到了一些问题,比如就是没有关于登录的例子,并且没有google出相关的内容,这里是自己摸索的出的一种方法。

基于Webmagic框架的爬虫小Demo
如题: Demo简介: 目标:爬取天善最热博文列表(https://blog.hellobi.com/hot/weekly)对应的博文信息存入mysql数据库中。 暂定的博文相关信息有: 博文url::url博文标题::title博文作者::author作者博客地址::blogHomeUrl博文阅读数:readNum博文推荐数:recommandNum博文评论数:comment

学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面 由于业务需要,老大要我研究一下爬虫。 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周。基于以上原因固放弃python,选择java为语言来进行开发。等之后有时间再尝试python来实现一个。 本次爬虫选用了webMagic+selenium

WebMagic+Selenium爬取网易云音乐
**在阅读本文章之前需要您具备一些WebMagic和Selenium的知识 像网易云音乐、QQ音乐等音乐网站,都会对音乐地址进行加密 这里提供给大家一个外链转换的网站 https://link.hhtjim.com/ 找到网易云这一栏 id后面的这一堆数字就是歌曲的id 最后生成的https://link.hhtjim.com/163/5146554.mp3即为该首音乐的外链地址 打开看一看