本文主要是介绍Spark on k8s 在阿里云 EMR 的优化实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导读: 随着大数据技术的发展,Spark 成为当今大数据领域最受关注的计算引擎之一。在传统的生产环境中,Spark on YARN 成为主流的任务执行方式,而随着容器化概念以及存算分离思想的普及,尤其是 Spark3.1 版本下该模式的正式可用(GA),Spark on K8s 已成燎原之势。
今天的介绍会围绕下面两点展开:
- Spark on K8s 的基础概念和特性
- Spark on K8s 在阿里云 EMR 的优化和最佳实践
点击查看直播回放
Spark on K8s 的基础概念和特性
首先和大家分享下 Spark on K8s 的一些背景。
1. Spark 的集群部署模式
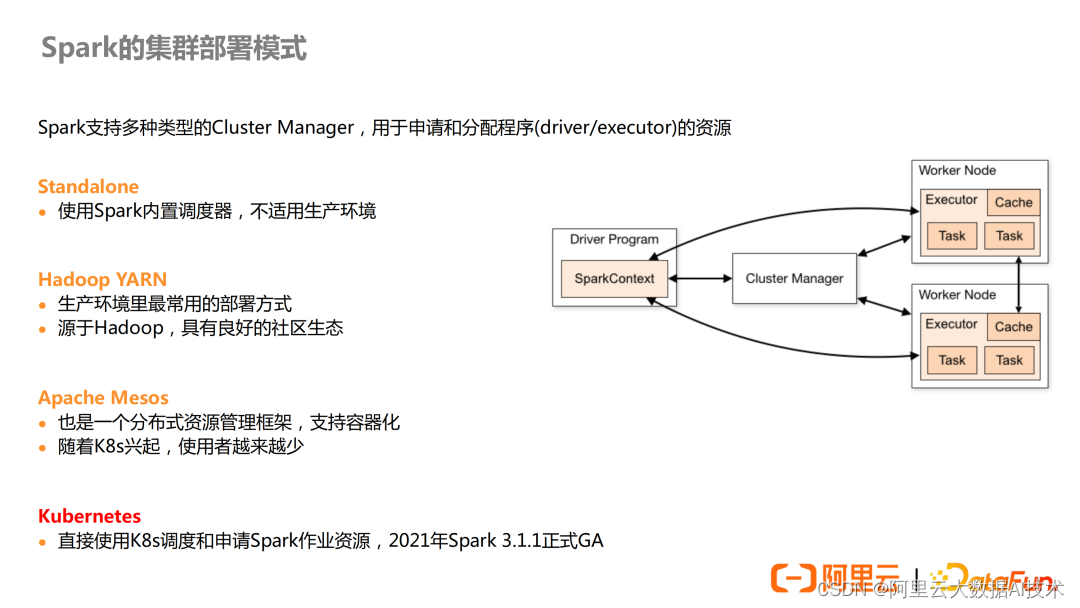
Spark 现如今支持 4 种部署模式:
- Standalone:使用 Spark 的内置调度器,一般用于测试环境,因为没有充分利用到大数据的调度框架,无法充分利用集群资源。
- Hadoop YARN:最常见的一种方式,源自 Hadoop,拥有良好的社区生态。
- Apache Mesos:与 YARN 类似,也是一个资源管理框架,现在已经逐渐退出历史舞台。
- Kubernetes:即 Spark on K8s,Spark3.1.1 对这种部署模式正式提供可用支持,越来越多的用户也在积极做这方面的尝试。
使用 Spark on K8s 的优势如下:
- 提高资源利用率:无需按照使用场景部署多个集群,所有 Spark 作业共享集群资源,能提高总体集群利用率,而且在云上使用时可以弹性容器实例,真正做到按量付费。
- 统一运维方式:可以利用 K8s 的社区生态和工具,统一维护集群,减少集群切换带来的运维成本。
- 容器化:通过容器镜像管理,提高 Spark 任务的可移植性,避免不同版本 Spark 带来版本冲突问题,支持多版本的 A/B Test。
尤其需要关注的一点是,根据我们的测试,在相同的集群资源条件下,Spark on K8s 和 Spark on YARN 的性能差距几乎可以忽略不计。再加上充分利用 Spark on K8s 的弹性资源,可以更好地加速 Spark 作业。
总结来看,Spark on K8s 相较于 Spark on YARN 的模式来说,其实是利大于弊的。
2. Spark on K8s 的部署架构
当前环境下,想要把 Spark 作业提交到 K8s 上,有两种方式:
- 使用原生的 spark-submit

在这种方式下,K8s 集群无需提前安装组件。像现在使用的 YARN 的提交方式一样,提交作业的 Client 端需要安装 Spark 的环境,并且配置 kubectl,就是连接 K8s 集群的一个工具,然后在提交命令中标注 K8s 集群地址以及使用的 Spark 镜像地址即可。
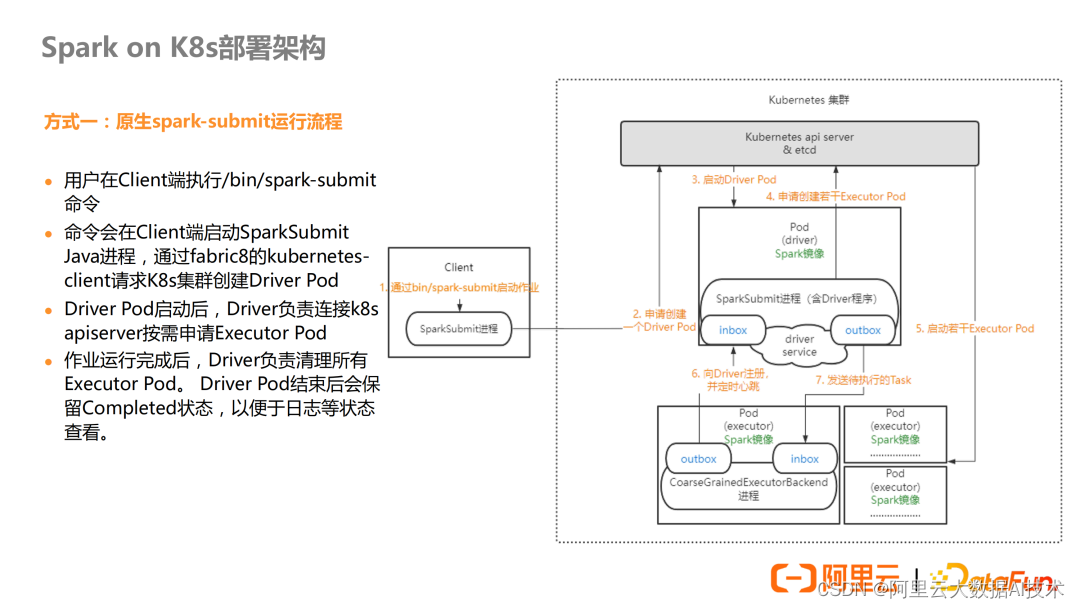
上图详细的展示了使用原生的 spark-submit 提交任务到 K8s 的任务运行流程。用户在 Client 端执行 spark-submit 命令后会在本地启动一个进程,该进程会连接 K8s 的 api server 请求创建一个 Driver Pod。Driver Pod 在启动进程中会启动 Spark Context,并负责申请 Executor Pod。任务执行完毕后,Driver Pod 会负责清理 Executor Pod。但 Driver Pod 结束后会保留,用于日志或状态的查看,需要手动清理。
优点:
这种提交方式符合用户的使用习惯,减少用户学习成本,与现有的大数据平台集成性更好。因为是 Client 模式提交,支持本地依赖,支持 Spark-shell 的交互式作业模式。
- 使用 Spark-on-K8s-operator
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p0Vdynhk-1666922196840)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/69ae882219004c5baf3a672e86afb13c~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/5f303164463e48fd8cb84481b75eaf37.png)
Spark-on-K8s-operator 是 Google 开源的一个组件,需要提前在 K8s 集群中部署一个常驻 pod,以提供相关服务。与第一种方式不同的是,使用这种方式不再是以命令行的方式提交,而是使用 kubectl 提交一种 yaml 文件来提交作业。本质上来说,这种工具具体实现还是使用的 spark-submit 的方式,只是相当于命令行中的信息换了一种格式以文件的形式提交。但是 Spark-on-K8s-operator 在第一种方式的基础上,做了一些辅助工具,包括定时调度、监控、作业管理等。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dd5cTOf8-1666922196842)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/347d6adbab76457b991d7d7231c8548d~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/1c2cf695c12d429a9528fbf7455507d0.png)
从流程上来说,用户提交了一个 yaml 文件,在 K8s 集群上常驻的 Spark-on-K8s-operator 就监听到了这个事件,通过解析文件转化成执行 spark-submit 命令启动一个 Spark 任务。
除了提交方式的不同,我们刚刚也提到这个工具提供了一些辅助的功能。Spark-on-K8s-operator 通过 K8s 的 Mutating Admission Webhook 机制,拦截了 K8s 的 Api 请求,在启动 Driver 和 Executor Pod 资源时,可以对其进行一些自定义配置处理。另一方面,工具可以监听 Driver 和 Executor Pod 的事件,从而跟踪和管理任务的执行进度。
优点:
工具的存在支持作业的管理,包括记录、重试、定时执行等。提供作业监控指标,也可以对接 Prometheus 方便统一监控。支持自动清理作业资源,也可以自动配置 Spark UI 的 service/ingress。
3. Spark on K8s 的社区进展
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yqy9Fjcx-1666922196844)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/6010916b79d248008c1f2a57fa2ac03f~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/5e175cbf43504092a9ce04916e2392c3.png)
Spark2.3 之前,有人尝试过通过在 K8s 上部署 YARN 的方式来支持 Spark on K8s,但是本质上 Spark 还是跑在 YARN 的资源管控下,所以并不能称之为完整意义上的 Spark on K8s。
Spark2.3,社区首次发布支持了原生的 Spark on K8s,全是第一次官方支持这样的部署方式。
Spark2.4 做了少量的特性优化,真正完善了这个功能是在 Spark3 版本,尤其是 Spark3.1 正式可用(GA)。当前 Spark on K8s 方向热度很高,所以如果感兴趣的同学建议直接升级到 Spark3.1 来尝试这个部署方式。
4. Spark on K8s 的重点特性
- 优化 Spark Pod 配置属性
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HdadImvw-1666922196846)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/d5477ea18aca4bf1a0cbc461c4cd8873~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/7457542530df4c678f2d15c30b57429d.png)
K8s 的 Pod 定义通常采用 Yaml 的描述处理,早期的 Driver 和 Executor Pod 定义只能通过 Spark Conf 进行配置,灵活性很差,毕竟不是所有的配置都能通过 Spark Conf 处理。Spark3.0 开始,支持使用模板文件。用户可以建立模板文件,定义 Pod 的属性,然后通过 spark 的配置传入,相较于单条配置更加便利,灵活性增强了很多。
- 动态资源分配(Dynamic Allocation)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eo5YnGAM-1666922196847)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/a1d73c83e9ef4d5e9f424eaa3ecebd42~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/70154a4a380b413b8b72fe498f05847c.png)
Spark2 版本时,动态资源分配只能使用 External Shuffle Service(ESS)的方式,这种方式下,executor 在执行时产生的 shuffle 数据全部交由 ESS 服务接管,executor 执行完毕随时回收。但是这种方式一般由 YARN 的 Node Manager 启动管理,很难在 K8s 上部署。
Spark3 版本中支持了 Shuffle Tracking 的特性,就是可以在没有 ESS 的情况下,利用自身对 executor 的管理,做到动态资源配置的效果。但是这种方式的缺点就是,在 shuffle read 阶段 executor 不能动态回收,仍需要保留以供 reducer 读取 shuffle 数据,然后需要等到 driver 端 gc 之后才会标记这个 executor 可以释放,资源释放效率低。
- 节点优雅下线(node decommissioning)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L0tFBhR8-1666922196849)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/ad9288956cbe4eaf8d858216ba57c0c0~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/86dff577bce547009f787c702bec7cb8.png)
在 K8s 的环境中,节点的缩容,抢占式实例回收这些场景还是比较常见的,尤其是在一些场景下,将部分 Spark 的任务优先级调低以满足其他高优先级的任务的使用。这种场景下,executor 直接退出可能会存在 stage 重算等情况,延长了 Spark 的执行时间。Spark3.1 提供了“优雅下线”特性,支持 Executor Pod 在“被迫”下线前,可以通知 Driver 不再分配新的 Task,并将缓存的数据或者 shuffle 的文件迁移到其他的 Executor Pod 中,从而保证对应 Spark 任务的效率,避免重算。
当前这个功能还属于实验性质,也就是默认不开启。
- PersistentVolumeClaim 复用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qcg2dF8V-1666922196850)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/ebd735ce3f8f423598e426b4594a2f85~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/d84718f402ab4221abaff22abbf4af40.png)
PersisentVolumnClaim(简称 pvc),是 K8s 的存储声明,每个 Pod 都可以显式地申请挂载。Spark3.1 支持动态创建 pvc,意味着不需要提前声明申请,可以随着执行动态的申请挂载资源。但是这个时候 pvc 的生命周期伴随着 Executor,如果出现上述的抢占式被迫关闭的情况,同样会出现保存在 pvc 上面的数据丢失重算的问题。所以在 Spark3.2 中,支持了 pvc 重新利用,它的生命周期伴随 Driver,避免了重新申请和计算,保障整体的效率。
Spark on K8s 在阿里云 EMR 的优化和最佳实践
接下来和大家分享下阿里云 EMR 对于 Spark on K8s 的优化和最佳实践。
1. Spark on ACK 简介
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l3WnUKdr-1666922196851)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/26b7606dd0504c8aa8c744fa88509fbe~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/ee585e25868e4566babd63585a6993bb.png)
ACK:阿里云容器服务 Kubernetes 版,简称 ACK。
EMR:阿里云开源大数据平台 E-MapReduce,简称 EMR。
在阿里云公共云上,我们有一款 EMR on ACK 的产品,其中包含了 Spark 类型的集群,后面简称 Spark on ACK。Spark on ACK 这个产品是一套半托管的大数据平台,用户首先需要有一个自己的 ACK 集群,也就是 k8s 集群,然后我们会在这个集群内创建一个用于 Spark 作业的 namespace,并安装一些固定组件 pod 比如 spark-operator、historyserver 之类,后续的 Spark 作业 pod 也会在这个 namespace 下运行,这些 Spark 作业 pod 可以利用用户自己的 ACK 节点机器来跑,也可以利用我们的弹性实例 ECI 来跑,来实现按量付费。这个所谓弹性实例 ECI 是什么,接下来我们具体介绍一下。
2. 云上弹性优势
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sDTIfTXW-1666922196852)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/c53163dcfa584cad9081979a516ce01a~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/5aaef2d056f84d3e8150e259e10b6162.png)
Spark 在云上最大的优势就是更好的弹性,在阿里云的 ACK 的环境中,提供了一个弹性容器实例 ECI 的产品,有了 ECI 意味着,我们申请 pod 时不再是占用自己的机器节点的资源了,而是完全利用云上资源来创建 pod,而且可以做到快速拉起,秒级付费。利用 ECI 来跑 spark 作业我认为是非常划算的,因为通常大家用 spark 作业跑批处理任务,凌晨高峰,白天可能只有少量查询,这种峰谷明显的特点搭配快速弹性和按量付费是很适合的,外加 ECI 可以使用 spot 抢占式实例,有 1 个小时的保护期,并结合 Spark 的 Node decommissioning 特性,可以节省很多成本。
3. RSS 优化 Shuffle 和动态资源
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SShdZ3K7-1666922196853)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/d1ac50c16afa471b89f6a975e0b7dc34~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/47f593181b0f46bfb85a6df4161871f1.png)
Spark Shuffle 对本地存储依赖较大,但是云上环境下,存储分离的机器很难保障自带本地磁盘,使用云盘大小也无法预估,性价比不高。另一方面,Spark 原生的无 ESS 的动态资源配置,executor 的释放资源效率较低,可能因为无法回收造成资源浪费。
Spark Shuffle 本身也有很多缺点。Mapper 的输出量增大,导致 spill 到本地磁盘,引发额外的 IO;Reducer 并发拉取 Mapper 端的数据,导致大量随机读的产生,降低效率;在 shuffle 过程中,产生 numMapper * numReducer 个网络连接,消耗过多 CPU 资源,带来性能和稳定性问题;Shuffle 数据单副本导致数据丢失时,需要重新计算,浪费资源。
阿里云提供了独立部署的 RSS,目前已经在 github 上开源,可以直接对接 ACK,用户无需关注 Shuffle 数据是否有本地磁盘支持。原先的 spark shuffle 数据保存在 executor 本地磁盘,使用 RSS 后,shuffle 的数据就交给 RSS 来管理了。其实采用 push based 的外部 shuffle service 业界已经是一种共识了,很多公司都在做这方面的优化。优点有很多,Executor 执行完毕即可回收,节约资源;RSS 还将传统的大量随机读优化成了追加写,顺序读,进一步弥补了 Spark Shuffle 的效率问题;RSS 服务支持 HA 部署,多副本模式,降低重复计算的可能性,进一步保障 Spark 任务的效率。
4. 增强 K8s 作业级别调度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A1brkvZL-1666922196854)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/29d229a18057438bb4c0fe99e26af863~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/eadb0a8eb7754eaab3adf0955c8b1de1.png)
K8s 默认的调度器调度粒度是 Pod,但是传统的 Spark 任务调度默认粒度是 application。一个 Application 的启动,会伴随启动多个 Pod 执行支持。所以,突然提交大量 Spark 任务时,可能出现大量 Driver Pod 启动,单都在等待 Executor Pod 启动,从而导致整个集群死锁。另一方面,K8s 的多租户场景支持不佳,也不支持租户之间的弹性调度,以及动态配额等。相比于 YARN 的调度策略,K8s 的调度策略单一,为默认优先级+FIFO 的方式,无法做到公平调度。
阿里云 ACK 在这个方面做了增强:
- 调度时优先判断资源是否满足,解决上述可能出现的死锁问题。
- 基于 NameSpace 实现多租户树状队列,队列可以设置资源上下限,支持队列间抢占资源。
- 实现了以 App 粒度调度 Spark 作业的优先级队列,支持队列间的公平。调度,并基于 Spark-on-K8s-operator 的扩展,提交作业会自动进入队列。
5. 云上数据湖存储与加速
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RDH65Ypm-1666922196854)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f2fd333d4f554fbd88fb88e980966d76~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/d59cfdc699ad47a0bfa108aed41992c8.png)
- 在 K8s 环境下,相比于传统的 Hadoop 集群,使用数据湖存储 OSS 更贴合存算分离的架构。Spark on ACK 内置 Jindo SDK,无缝对接 OSS。
- Fluid 可支撑 Spark on K8s 部署模式下的缓存加速,在 TPC-DS 场景下,可以提升运行速度 30%左右。
6. 使用 DLF 构建云上数据湖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b8u6fXez-1666922196855)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/8aed35c7e056463894da55d9577405bd~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/097c641de9f945ebb428a877052b3106.png)
在 K8s 上想要使用 Hadoop 生态圈的组件,还需要额外部署。但是 Spark on ACK 无缝对接阿里云 DLF(Data Lake Formation),DLF 提供了统一的元数据服务,支持权限控制和审计,另外提供数据入湖的功能,支持 Spark SQL 的交互式分析,以及数据湖管理功能,支持进行存储分析和成本优化。
7. 易用性提升
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rhoA2jwJ-1666922196856)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/929423e81f7c40aca8a5722893a60a6f~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/8f814d2913ac441880705e16a8459953.png)
Spark on ACK 提供了一个 CLI 工具,可以直接以 spark-submit 语法来提交 spark 作业,同时也会记录到 spark-operator 里面来管理。之前我们提到了 2 种提交作业方式的优劣,spark-operator 具备比较好的作业管理能力,但是提交作业不兼容老的命令语法,也无法跑交互式 shell,从老集群迁移的用户改动比较麻烦,因此利用我们这种工具,可以同时享受 2 种提交方式的优点,对用户的易用性来说是个比较大的提升。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q1LE9JZ4-1666922196857)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f86816317ae5424da1ed0836ab940e96~tplv-k3u1fbpfcp-zoom-1.image)]](https://img-blog.csdnimg.cn/24e00dcb936b45679ad40f7e37eab0a9.png)
在日志收集这一点,Spark on ACK 提供日志收集方案,并通过 HistoryServer 让用户可以像 Spark on YARN 一样在界面上查看。
这篇关于Spark on k8s 在阿里云 EMR 的优化实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








