本文主要是介绍使用Python免费批量查询企业司法信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用Python批量查询企业司法信息
- 批量获取企业的司法信息
- 逻辑分析
- 输入基本信息
- 获取企业列表
- 获取企业详情
- 代码编写
- 搜索企业获取ocid
- 获取企业案号
- 数据存储
- 分批查询数据
- 免责声明
批量获取企业的司法信息
在某些情况下需要查询一些企业的司法信息,比如:
- 了解企业的信用情况:通过查询企业司法信息,可以了解企业的诉讼情况、失信被执行人维度等信息,进而判断企业的信用情况。
- 判断企业是否存在风险:企业的诉讼情况是判断一家企业是否存在风险的重要角度之一,透过企业所涉及到的诉讼可以了解到该企业的财力、信用度等情况,还能判断其是否存在爆雷的风险。
- 为投资决策提供参考:无论是机构投资者还是个人投资者,在做出投资决策之前,都需要对目标企业的诚信度、生产经营情况、财务情况有一定的了解,以帮助其判断可能需要承担的风险和收益。
- 对于个人的话就是相当于对企业的背调,这个企业是否有价值。
总之,对于不同的人有不同的需要。那么如何快速获取这些信息呢?答案就是找一个免费的查询网站,使用Python来实现。
逻辑分析
本文以钉钉企典为例,实现对企业的查询以及信息的存储。
输入基本信息
在首页输入企业名称后即可,以宁德时代为例。
获取企业列表
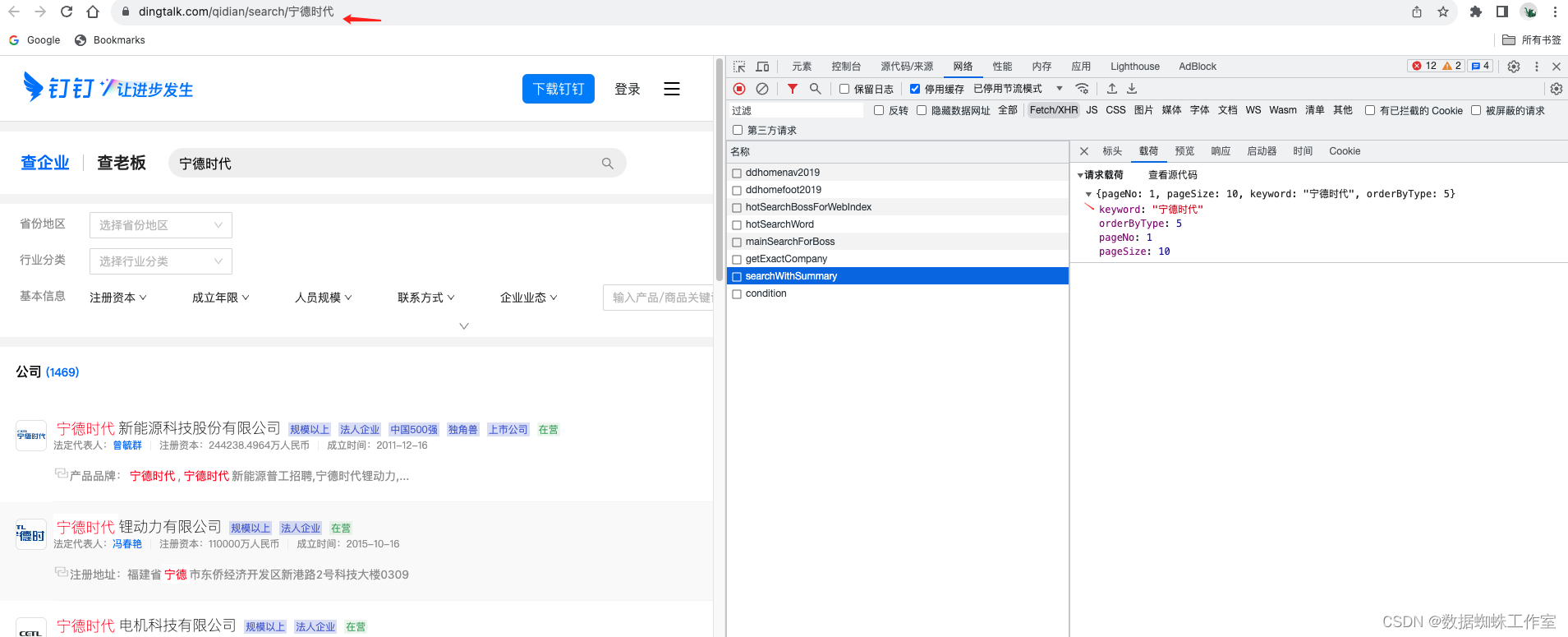
如图所示,这里获取到了若干个企业的名称,因为咱们是模糊查询的,如果企业名称更精确,展示的会更精准。
经过对比分析,只有searchWithSummary 这个接口是我们想要的结果。令人开心的事这里的查询参数是明文的,没有做任何加密,只有企业名称是变量,其他参数都可以固定不变。接下来分析一些响应数据:
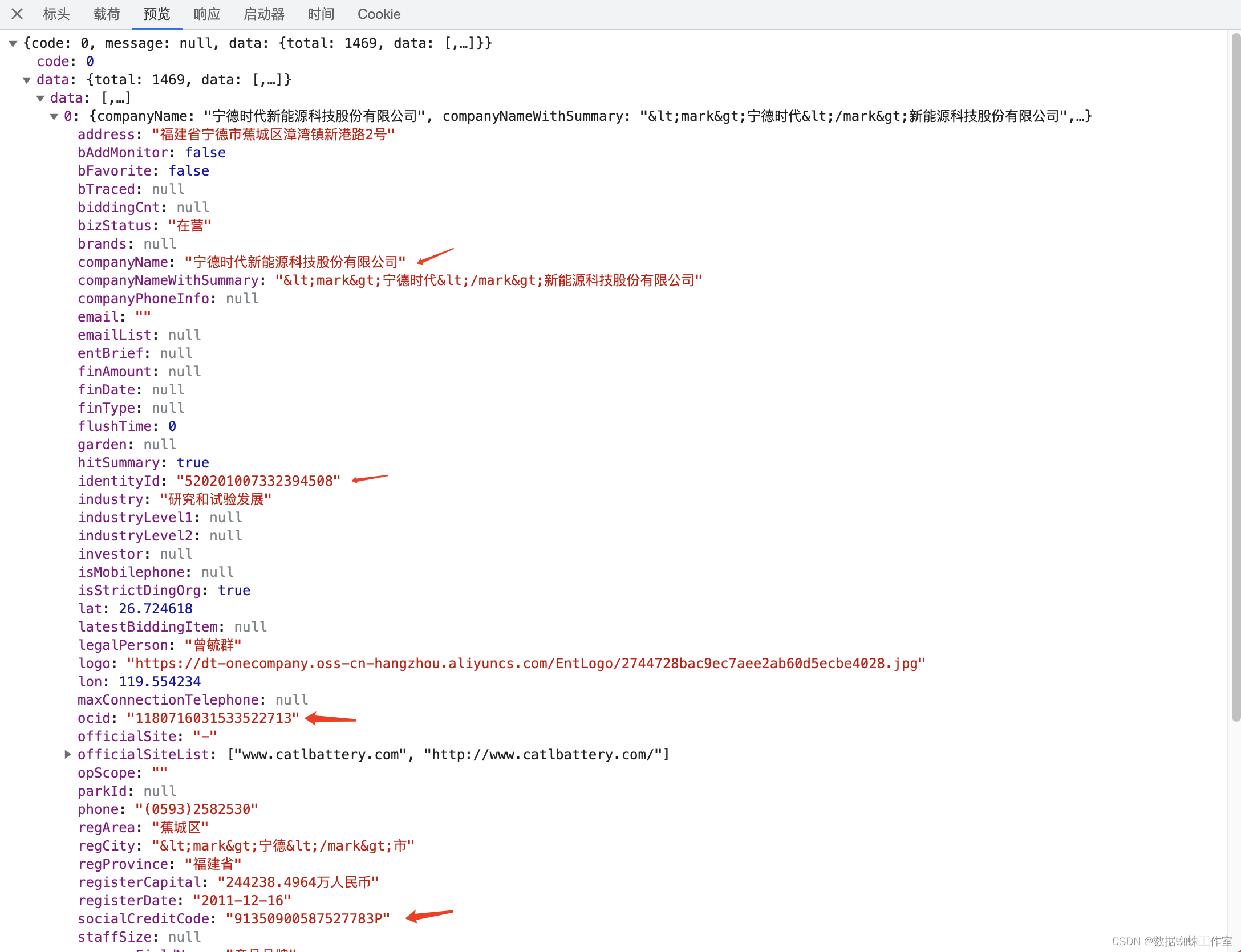
其实数据还有很多,但是标注的这些可能是能用得到的,但具体是哪个还不清楚,待会再继续看。
获取企业详情
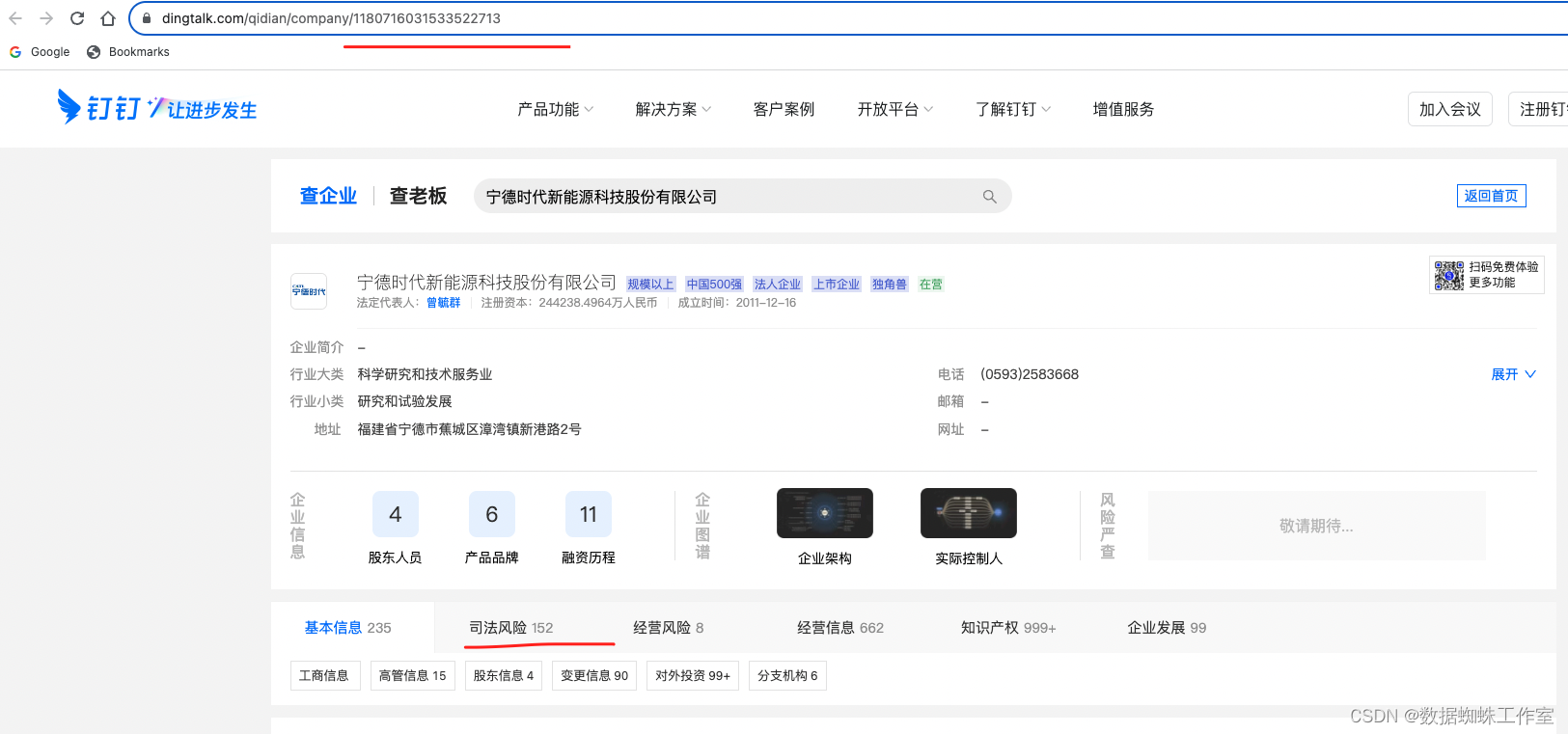
这里可以看到URL里跟着的一个参数很眼熟,就是前面获取的数据中的ocid字段。
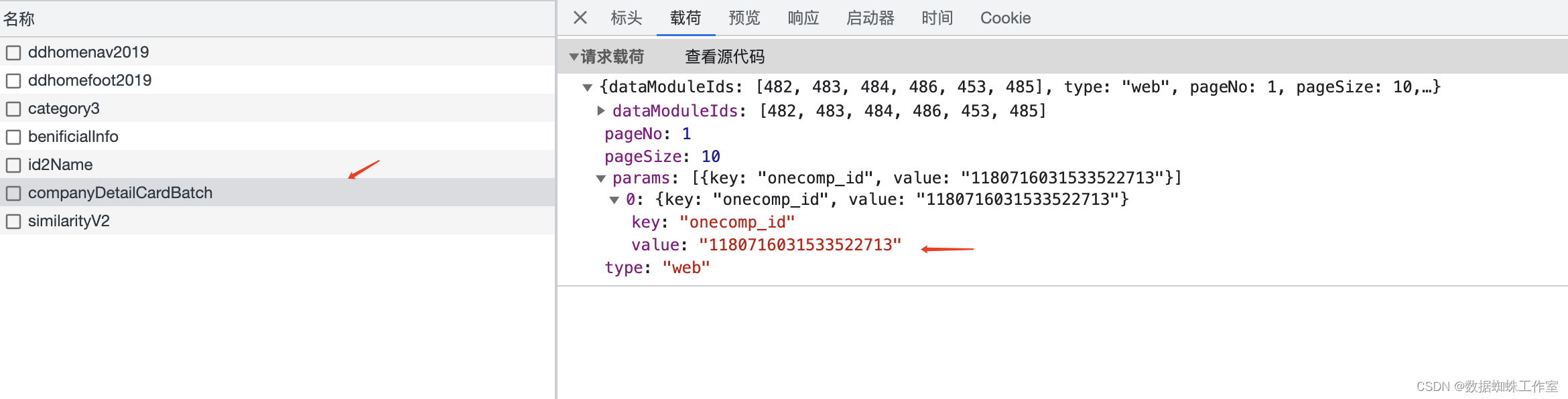
其实也就是这个接口里的参数拼接。但是这里有一个坑,companyDetailCardBatch接口里的数据并没有案号。只有一些别的信息,比如工商信息、高管信息、股东信息和变更信息等。明明页面里展示了司法信息的数量,但是并没有司法数据,这是为什么呢?
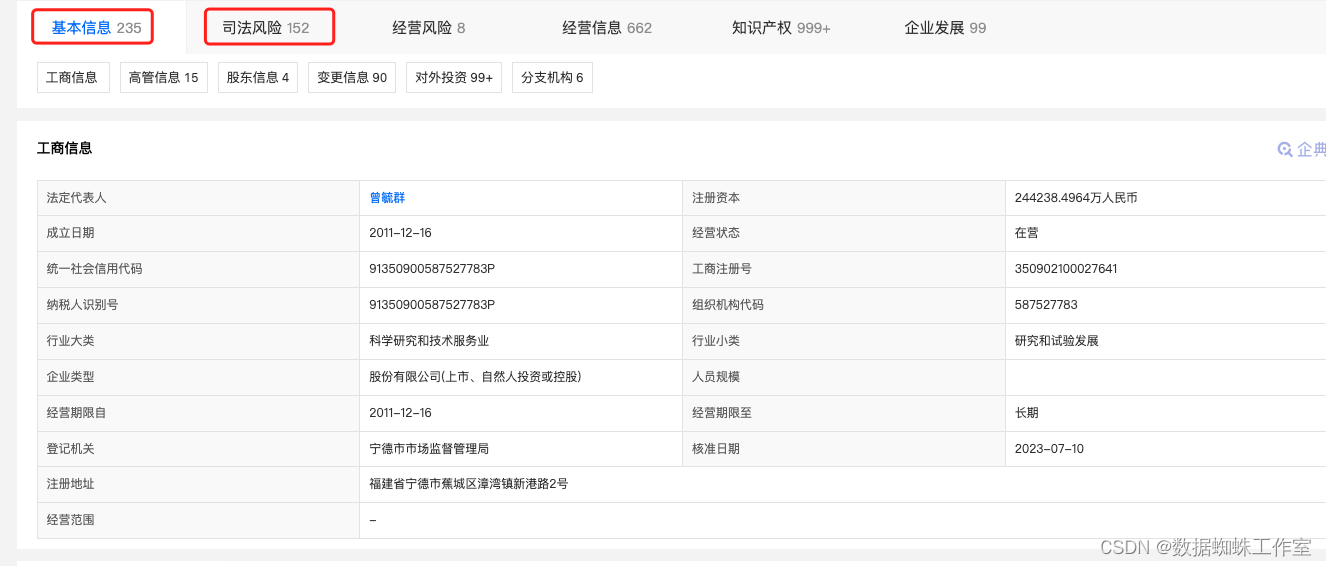
可以看到,当前选择的是基本信息,高亮的也是这个板块,所以会不会是因为没有选中司法风险导致的呢?
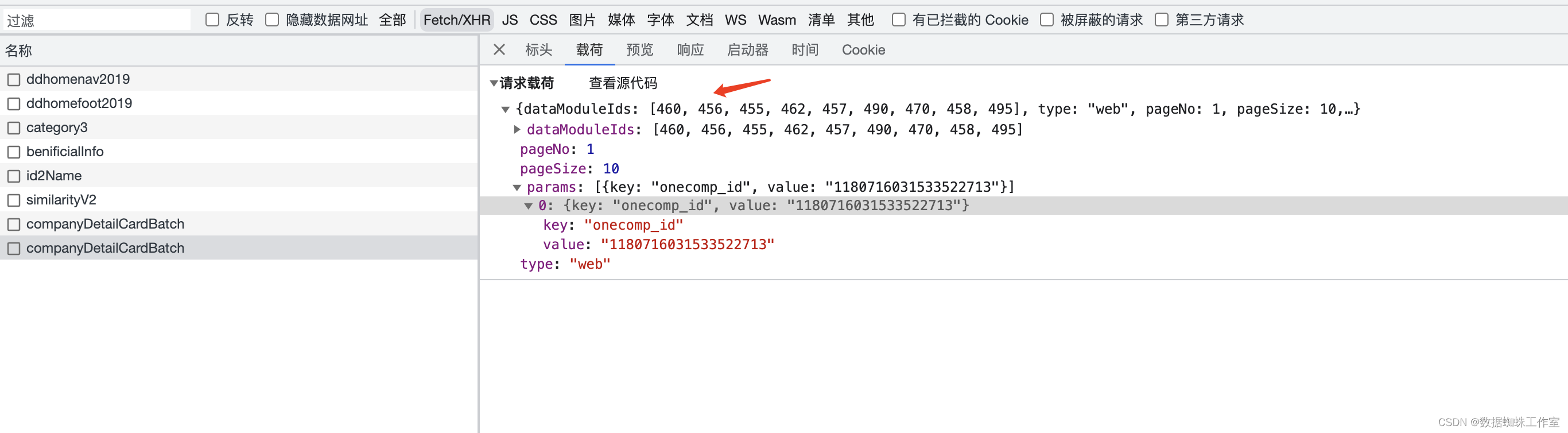
当我们点击司法风险版块的时候,发出了第二次请求,但是请求参数变了,所以会不会是增加了司法信息的参数查询,接下来看一下响应数据就可以确定了。
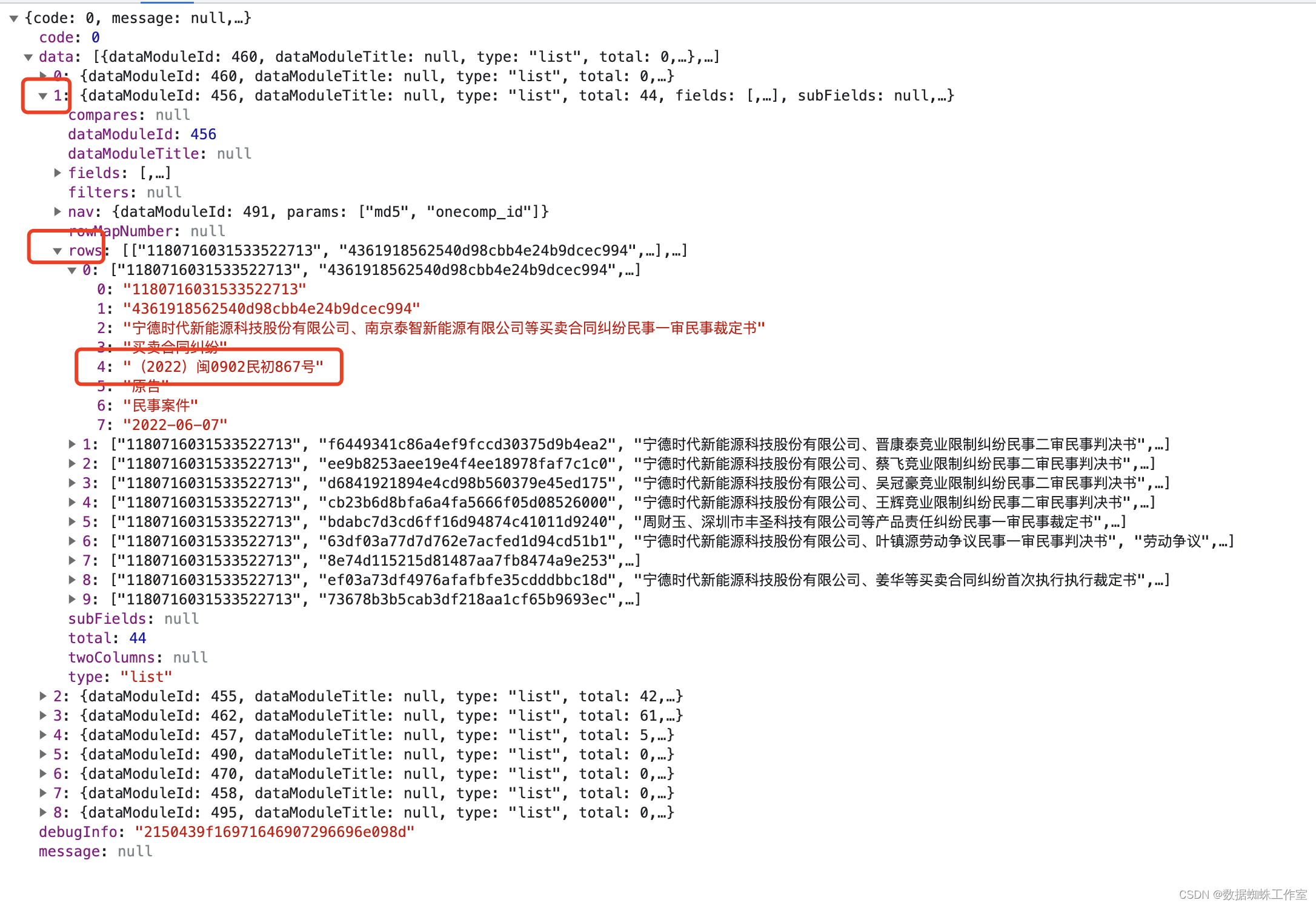
的确,在这里找到了多条案号信息。
至此,整套逻辑梳理完了,接下来就可以写代码了。
代码编写
搜索企业获取ocid
这里的c_name就是企业名称。
async def get_company(c_name):async with semaphore:async with aiohttp.ClientSession() as session:data = {"keyword": c_name,"orderByType": 5,"pageNo": 1,"pageSize": 10}async with session.post(host_search, data=json.dumps(data), ssl=False, headers=headers,) as resp:if resp.status == 200:try:res = await resp.json()ocid = res.get('data').get('data')[0]['ocid']print(c_name, ocid)com_info = {'name': c_name, 'ocid': ocid}await get_card_batch(com_info)except Exception as e:print(e)else:# 处理状态码不是 200 的情况print(f"Request to {host_search} failed with status code {resp.status} {resp.json()}")获取企业案号
async def get_card_batch(info):async with aiohttp.ClientSession() as session:data = {"dataModuleIds": [460, 456, 455, 462, 457, 490, 470, 458, 495], "type": "web", "pageNo": 1,"pageSize": 10, "params": [{"key": "onecomp_id", "value": info.get('ocid')}]}async with session.post(card_batch, data=json.dumps(data), ssl=False, headers=headers,) as resp:if resp.status == 200:try:res = await resp.json()rows = res.get('data')[1]['rows']if rows:tmp_list = [row[4] for row in rows]info['rows'] = ",".join(tmp_list)else:info['rows'] = ""save_to_csv([[info.get('name'), info.get('rows')]])print(info['rows'])except Exception as e:print(e)else:# 处理状态码不是 200 的情况print(f"Request to {host_search} failed with status code {resp.status} {resp.json()}")await asyncio.sleep(random.uniform(1.0, 10.0))
数据存储
def save_to_csv(data):with open(output_file, 'a', newline='') as file:writer = csv.writer(file)for sublist in data:writer.writerow(sublist)
以上就是代码基本逻辑,当然还有很多细节需要完善。
分批查询数据
async def read_csv_in_batches(csv_file, batch_size=100):with open(csv_file, 'r') as file:csv_reader = csv.reader(file)next(csv_reader) # 忽略首行batch = []for row in csv_reader:batch.append(row[0])if len(batch) >= batch_size:yield batchbatch = []if batch:yield batchasync def main():csv_head = ["公司名称", "案号"]# 写入CSV文件表头if not os.path.isfile(output_file):with open(output_file, mode="w", newline="") as file:writer = csv.DictWriter(file, fieldnames=csv_head)writer.writeheader()async for batch in read_csv_in_batches(resource_file, batch_size):tasks = [asyncio.create_task(get_company(com_info)) for com_info in batch]await asyncio.wait(tasks)
这段代码定义了一个异步生成器函数 read_csv_in_batches,其作用是从指定的 CSV 文件中逐批次读取数据,每批次包含指定数量的记录(默认为 100 条记录)。
这个函数的逻辑如下:
-
打开指定的 CSV 文件 csv_file 以只读模式,并创建一个 CSV 读取器 (csv.reader)。
-
使用next(csv_reader) 忽略 CSV 文件的首行,通常首行包含列名或表头,不包含实际数据。
-
初始化一个空列表batch,用于存储每个批次的记录。
-
使用 for 循环迭代 CSV 文件中的每一行(每一行通常代表一条记录)。
-
每次读取一行数据后,将其添加到 batch 列表中。
-
当 batch 列表的长度达到或超过指定的 batch_size(默认为100)时,通过 yield batch 语句将这个批次的数据生成为一个异步迭代项。
-
如果在文件遍历结束后,batch列表中仍有未处理的记录,最后一个批次也会通过 yield batch 返回。
这个生成器的作用是将数据分成多个批次,每个批次可以由协程异步处理,这在处理大量数据时非常有用,可以降低内存占用并提高效率
免责声明
- 教育和研究用途: 本文章提供的信息和示例代码仅供教育和研究用途。它们的目的是帮助读者了解爬虫技术的原理和应用。
- 合法合规性: 请注意,网络爬虫可能会侵犯网站的服务条款或法律法规。在实际应用中,你必须确保你的爬虫活动合法、合规,并遵守所有相关法律。
- 责任限制: 作者对于读者使用文章中提供的信息和代码所导致的任何问题或法律纠纷概不负责。读者应自行承担风险并谨慎操作。
- 合理使用: 请在使用网络爬虫时保持谨慎和礼貌。不要对目标网站造成不必要的干扰或侵害他人利益。请在遵守法律的前提下使用爬虫技术。
- 变动和更新: 作者保留随时更改文章内容的权利,以反映新的法规、技术和最佳实践。
- 资源和参考文献:本文章中的示例代码和信息可能依赖于第三方资源,作者会尽力提供相关参考文献和资源链接。作者不对这些资源的可用性或准确性负责。
- 协商: 如果您有任何关于本文内容或责任声明的疑虑或疑问,请在使用之前与专业法律顾问协商。
更多关注,获取更多内容。

这篇关于使用Python免费批量查询企业司法信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




