本文主要是介绍【数字人】4、AD-NeRF | 使用 NeRF 来实现从声音到数字人人脸的直接驱动(ICCV2021),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一、背景
- 二、方法
- 2.1 适用于 talking head 的神经辐射场
- 2.2 使用辐射场来进行体渲染
- 2.3 独立 NeRF 表达
- 三、效果
论文:AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
代码:https://github.com/YudongGuo/AD-NeRF
出处:ICCV2021
贡献:
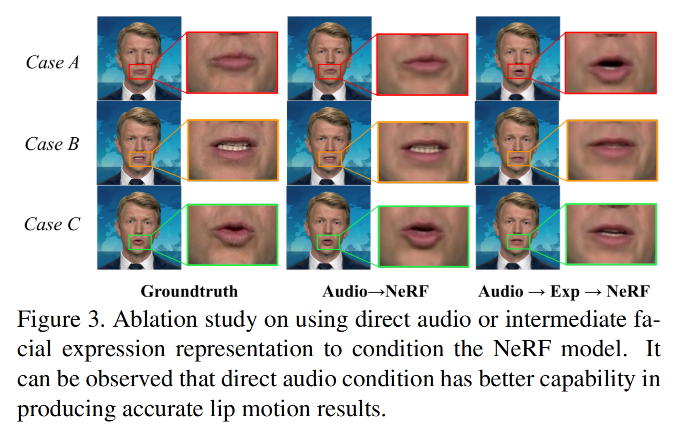
- 提出了基于 NeRF 的 talking head 生成, 不借助中间特征,不会导致信息丢失(消融实验也证明了这种直接映射的方式能更准确的捕捉唇部运动)
- 使用两个解耦的分支来分别对 head 和 torso 建模,能保证生成的结果更自然
- 能够进行姿态控制和替换背景,这个功能很实用
一、背景
Audio-driven 的说话人合成方法可以看成从 audio 到 visual face 的跨模态的特征映射
之前的很多方法都使用的 GAN,比如利用 3D face 或 2D landmark 作为中间表征,来对声音信号和面部形变作为中间桥梁,进行更简单的建模
但这样也会导致很多信息丢失,可能会让生成的面部形变和原始的声音信号之间缺乏正确的联系,为了避免一些误关联,很多方法只对嘴部建模,保持头部不动。
为了解决现有方法的问题,本文作者提出了基于 NeRF 的方法——AD-NeRF
- 使用 audio-driven 神经辐射场来建模 cross-modal 的特征映射,且不使用额外的中间表达
- 作者不使用 3D face 或 2D landmark 来对面部建模,而是直接使用 NeRF 来表达 talking head 的场景,同时考虑了 head 和 body 的运动
- 本文方法由于使用的事逐点建模的方法,所以比 GAN-based 的方法效果更好,质量更高,更保真
二、方法
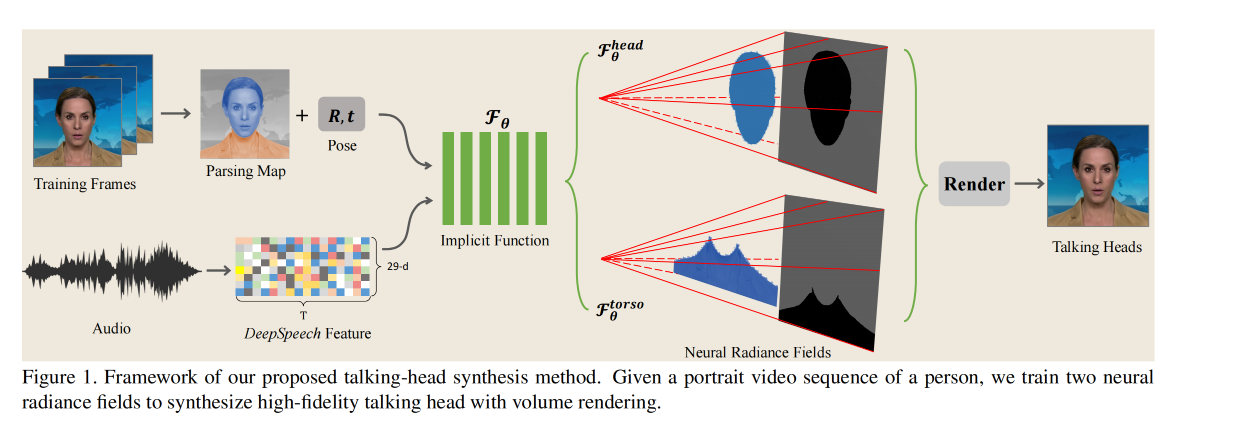
总体框架如图 1,输入使用的是一个视频序列:
- 首先,对每帧进行 parsing map 提取,对声音进行特征提取
- 然后,分别建模隐式函数来建模声音和 head 的关系、torso 的关系
- 最后,使用得到的颜色和密度进行渲染,得到 talking head
2.1 适用于 talking head 的神经辐射场
作者使用的是 conditional 神经辐射场来生成 talking heads,使用 audio 作为 condition
NeRF 其实就是一个映射函数,输入声音、3D 空间位置、每个位置的方向,输出该位置的颜色和密度(此处还额外的将每个声音 a 对应的 semantic feature 作为输入,semantic feature 在这里应该就是相邻 16 帧的信号)
Semantic audio feature
为了从声音信号中抽取到更有意义的语义信息,作者使用了 DeepSpeech 模型为每个 20ms 的 audio clip 来预测出 29-d feature code
本文中,连续的 audio feature 会送入时序的卷积网络来提出噪声信号,也就是使用从当前帧左右相邻的 16 帧的声音得到的特征 a ∈ R 16 × 19 a \in R^{16 \times 19} a∈R16×19 来表达当前时刻的声音信号。
2.2 使用辐射场来进行体渲染
使用 F θ F_{\theta} Fθ 得到了颜色和密度后,可以使用体渲染的方法来得到每个位置的颜色和密度
每个 ray r(t) \text{r(t)} r(t) 映射到某个位置上的期望的颜色为:

2.3 独立 NeRF 表达
作者对 head 和 torso 分别进行训练,因为两者的运动方式是不同的。
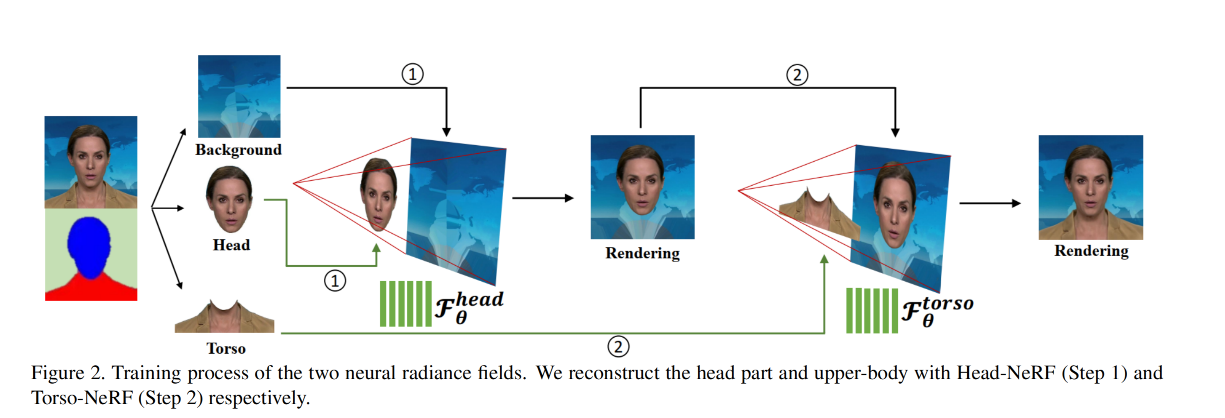
- 第一步,使用现有的方法来将图片分成三部分:static background、head、torso
- 第二步,对 head 区域训练 F h e a d F^{head} Fhead,训练该步骤时,只将 head 当做前景,其他的都当做背景(包括 torso),会使用 head pose Π \Pi Π 。一个 ray 的最后一个采样点被认为是落在背景上的
- 第三步,对 head 进行 render,重建好的 head 和 background 会合起来,被当做背景
- 第四步,对训练 F t o r s o F^{torso} Ftorso
三、效果



这篇关于【数字人】4、AD-NeRF | 使用 NeRF 来实现从声音到数字人人脸的直接驱动(ICCV2021)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








