本文主要是介绍ManTra-Net: Manipulation Tracing Network论文阅读记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:提出Mantra-Net端到端的深度学习框架用于现实生活中的篡改取证,并不包含前后处理操作具有检测和定位 的功能,包括拼接、复制粘贴、移除、增强等未知类型。提出一种可以检测385中类型的篡改痕迹检测简单高效的自监督模型,把图像篡改当做异常检测,实验证明其应对多种篡改操作的组合。
5、实验部分
以上部分已经说明了篡改痕迹特征和异常检测网络,在标注数据集中评估其泛化性能、敏感性、鲁棒性能等,使用AUC作为性能评估标准,由于网络中少部分原始像素错误认为篡改像素,在网络中并未得到惩罚(一定程度上会造成误检过高),因此如果mask出现一半以上的篡改区域,我们则不认同。参考文献(Fighting fake news: Image splice detection via learned self-consistency)
5.1预训练模型和一般性测试
在四个数据库中评估,为了评估这些模型的可推广性,选择最新的部分cnn的图像修复算法,作为一种典型的基于域外dnn的操作。另外使用 Photoshope-battle数据集,因为数据集较大具有多样性,并未像素级的标注,我们评估时候是图像水平的评判。
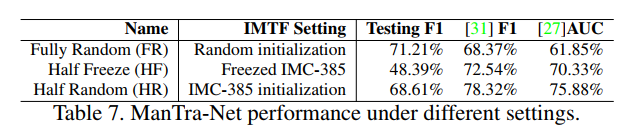
从表7中可以看出,用全随机权重训练的全随机模型不能很好地泛化,因为它过度拟合合成数据,而使用的合成数据集中呈现的伪造线索与现实世界中的有很大不同。通过冻结图像处理痕迹特征(IMTF)和随机LADN权重训练的半冻结模型可以防止这种情况的发生过拟合,但这也打消了寻找更好功能的希望
对于其他伪造类型,因为已知操作跟踪特征是优化增强数据集
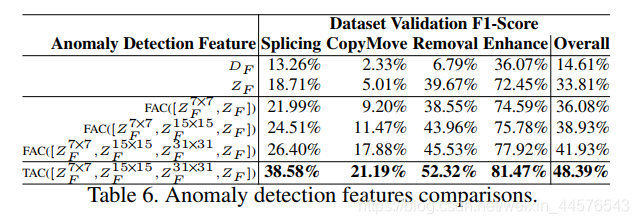
(见表6中的Enhance列),但不是拼接,copy-move或删除。相反,半随机模型这允许这些权值在较低的学习中更新速率5e-5防止过拟合和收敛到一个更好所有伪造类型的特征表示。因此,我们使用半随机模型在以后的实验
5.2 敏感性与鲁棒性评估
1)使用篡改函数和参数P,在dresden testing生成5000块;2)在合成数据上评估 3)在图4 显示数据性能表现
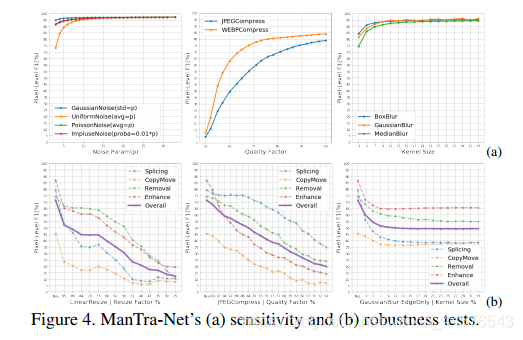
考虑三种后处理操作,缩放、压缩、边缘模糊,最后,虽然局部模糊在欺骗基于边缘的伪造检测方法方面是非常有效的,但mantranet对这类攻击是相当免疫的。
5.3 比较现有方法
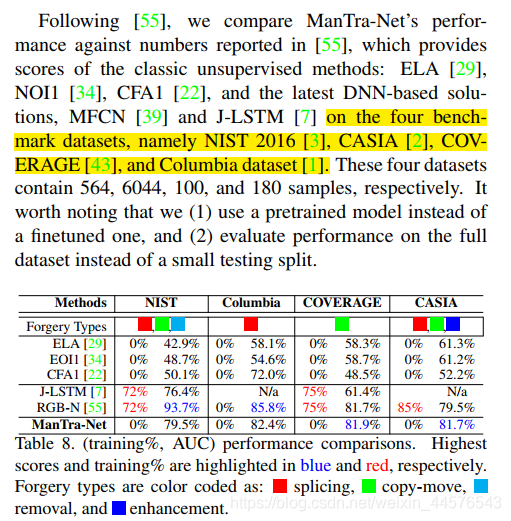
讨论了实验结果,在nist 和columbi上排名第二,原因是对于哥伦比亚数据库并未采用具体的特征,rgb-n利用其噪声差异特征能够很好刻画这一点,nist 图像块的尺寸较大 相较于训练的图片,加上 他们的方法有微调。在coverage 和casia数据集上的图片取得优异的结果,最有可能的解释就是输入图片和训练时的图像尺寸相近。
可以得出初步结论:提出的方法优于现有的方法,在不同数据上性能表现较好,并未需要微调和后处理等。

限制:
在提出的方法有较好的表现外,说明了方法存在的限制 1)通过电脑合成的图片 2)篡改区域与背景区域具有相同时噪声分别时 3)图片中存在多区域篡改的情况下,需要指定区域的情况下,才能判断出篡改区域

6、结论
在本文中,提出新颖的端到端的神经网络篡改定位称为Mantra-Net,首先提取待检测图片的篡改痕迹特征,确定异常区域通过评估局部特征的异常性,并且通过预训练模型证明预训练模型对微小物体的敏感性,后处理操作具有鲁棒性,在不可见数据和未知篡改类型具有能力。
这篇关于ManTra-Net: Manipulation Tracing Network论文阅读记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






