本文主要是介绍常用数据探查函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Task01–data structure@TOC
glimps()
library(dplyr)
library(readr)
h1n1_flu<-read_csv('/Users/shixinjin/Desktop/h1n1_flu.csv')
glimpse(h1n1_flu)
最终得到的结果为

从这里就可以看出,glimpse()起到了一个print()的转置功能,有时候,如果列数太多,用print()打印出来看不出来数据的全部列,这时候为了能看到所有列数,就可以使用glimpse()
str()
str(h1n1_flu)
最后得到的结果为

从这个结果我们可以看到每一列的名称,每一列的数据类型,以及总长度。看出来这是一个dataframe,共有26707行,33列。
他能够紧密的展示R的内在结构,是summary的替代品。对于任何类型的R数据结构都能用它来查看结构。
head()
head(h1n1_flu)
最终得到的结果为:

这个函数可以显示dataframe的前几行,可以设置参数n,来明确需要显示到底是前面几行。
tail()
tail(h1n1_flu)
最后得到的结果为

从这里就可以看出tail()这个函数显示的dataframe的后几行,和head()的用法相同。
View()
View(h1n1_flu)
得到的结果为

使用这个函数之后,它会自动跳转到看原始数据的界面中去.它能够唤起数据表格式的数据。
summary()
summary(h1n1_flu)
得到的结果为

从这个结果可以看出,它能够显示每一列中的最大值,最小值一分位数,三分位数和平均值。以及含有NA的个数。如果是字符型的列的话,会显示总长度,类型和模式。例如

nrow()
nrow(h1n1_flu)
得到的结果为

从这里可以看出,它能够显示一个dataframe的总行数。本来认为会有ncolumn,但实际情况下却发现并没有。总列数是用length()这个函数得到的
length()
length(h1n1_flu)
最后得到的结果为

length()可以显示dataframe的总列数。
class()
class(h1n1_flu)
最后得到的结果为
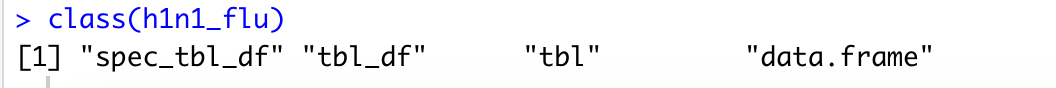
这个函数应该是可以显示数据类型。
table()
table(h1n1_flu$sex)
得到的结果为
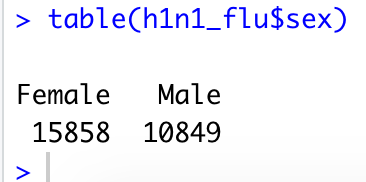
如果某一列是因子的话,它可以统计不同水平的因子的个数。
这篇关于常用数据探查函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





