本文主要是介绍Node2Vec实战---《悲惨世界》人物图嵌入,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. pip各个包后导入
import networkx as nx # 图数据挖掘
import numpy as np # 数据分析
import random # 随机数# 数据可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号2. 导入内置的数据集
# 《悲惨世界》人物数据集
G = nx.les_miserables_graph()3. 可视化图,with_labels=True,以此给每个节点的名称显示出来
# 可视化
plt.figure(figsize=(15,14))
pos = nx.spring_layout(G, seed=5)
nx.draw(G, pos, with_labels=True) # 给每个节点的名称显示出来
plt.show()
4. 接下来导入Node2Vec模型,并设置其模型参数,并将最终得到的各个节点的嵌入向量embedding赋予给变量X
from node2vec import Node2Vec# 设置node2vec参数
node2vec = Node2Vec(G, dimensions=32, # 嵌入维度p=1, # 回家参数q=3, # 外出参数walk_length=10, # 随机游走最大长度num_walks=600, # 每个节点作为起始节点生成的随机游走个数workers=4 # 并行线程数)# p=1, q=0.5, n_clusters=6。DFS深度优先搜索,挖掘同质社群
# p=1, q=2, n_clusters=3。BFS宽度优先搜索,挖掘节点的结构功能。# 训练Node2Vec,参数文档见 gensim.models.Word2Vec
model = node2vec.fit(window=3, # Skip-Gram窗口大小min_count=1, # 忽略出现次数低于此阈值的节点(词)batch_words=4 # 每个线程处理的数据量)X = model.wv.vectors # 77个节点的嵌入向量5. 接下来用Kmeans聚类算法,进行节点Embedding聚类可视化
#DBSCAN聚类
# from sklearn.cluster import DBSCAN
# cluster_labels = DBSCAN(eps=0.5,min samples=6).fit(X).labels
# print(cluster labels)# KMeans聚类
from sklearn.cluster import KMeans
cluster_labels = KMeans(n_clusters=3).fit(X).labels_ # 对X进行聚类,聚成三簇,
print(cluster_labels) # 得到聚类的labelprint(cluster_labels)的结果:
将词汇表的节点顺序转为networkx中的节点顺序。
colors = []
nodes = list(G.nodes)
for node in nodes: # 按 networkx 的顺序遍历每个节点idx = model.wv.key_to_index[str(node)] # 获取这个节点在 embedding 中的索引号colors.append(cluster_labels[idx]) # 获取这个节点的聚类结果把colors放到原图中可视化,可视化聚类效果如下:
plt.figure(figsize=(15,14))
pos = nx.spring_layout(G, seed=10)
nx.draw(G, pos, node_color=colors, with_labels=True)
plt.show()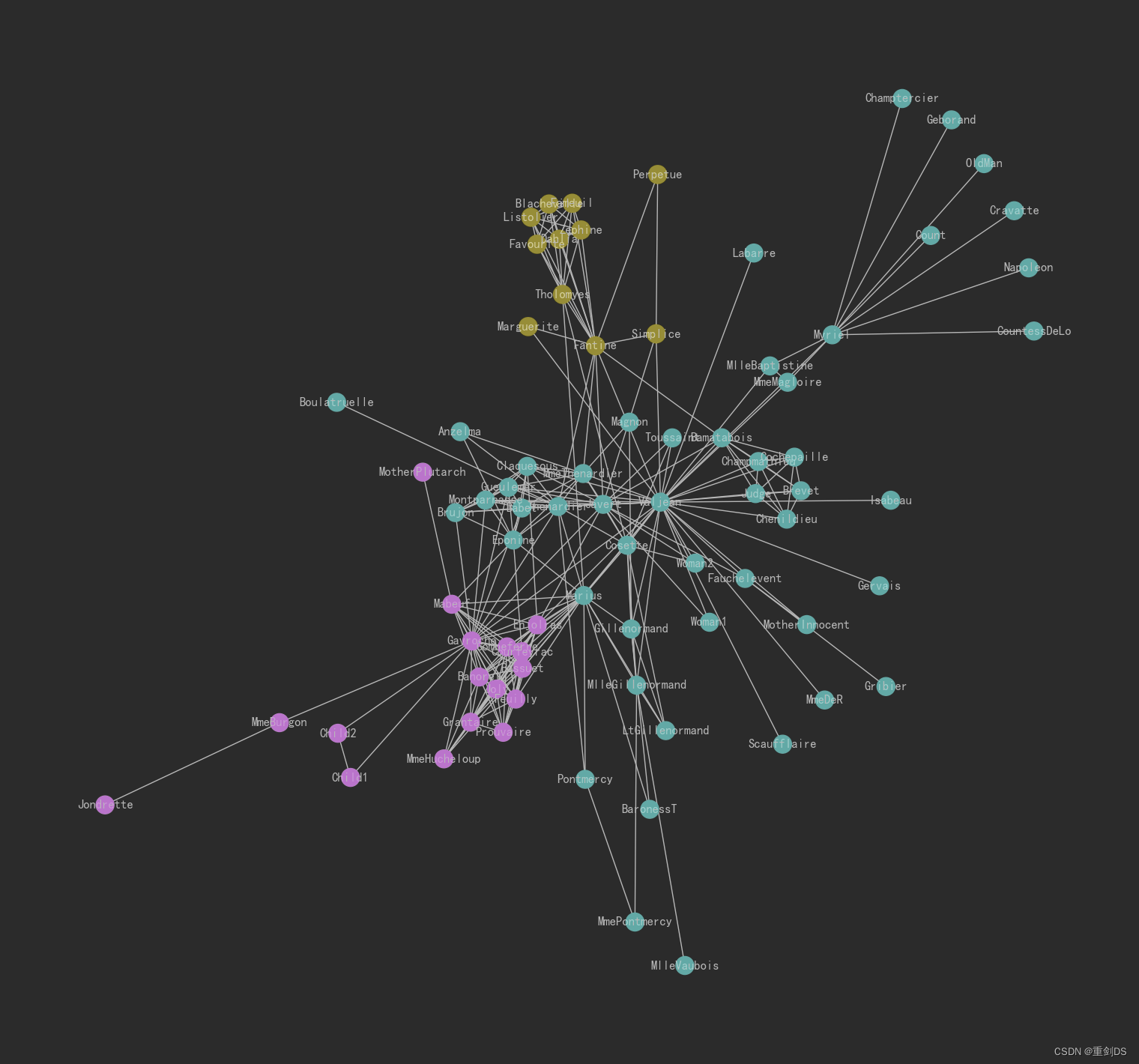
上图的效果其实很像原论文里所谓DFS的效果,也就是挖掘同质社群,我觉得更通俗一点,就是相邻的节点其实就是一类。
6. 将Embedding用PCA降维到2维,进行节点embedding降维可视化
# 将Embedding用PCA降维到2维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
embed_2d = pca.fit_transform(X)# # 将Embedding用TSNE降维到2维
# from sklearn.manifold import TSNE
# tsne = TSNE(n_components=2, n_iter=5000)
# embed_2d = tsne.fit_transform(X)# plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0], embed_2d[:, 1]) # 绘制散点图
plt.show()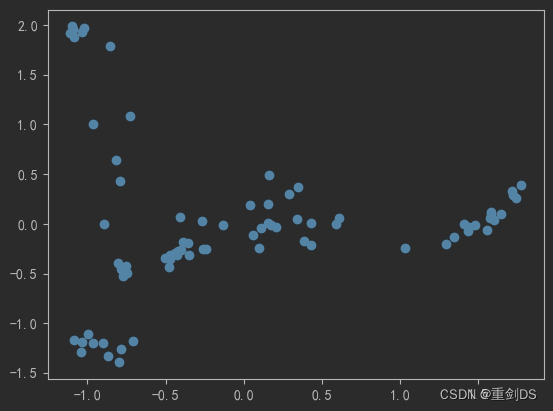
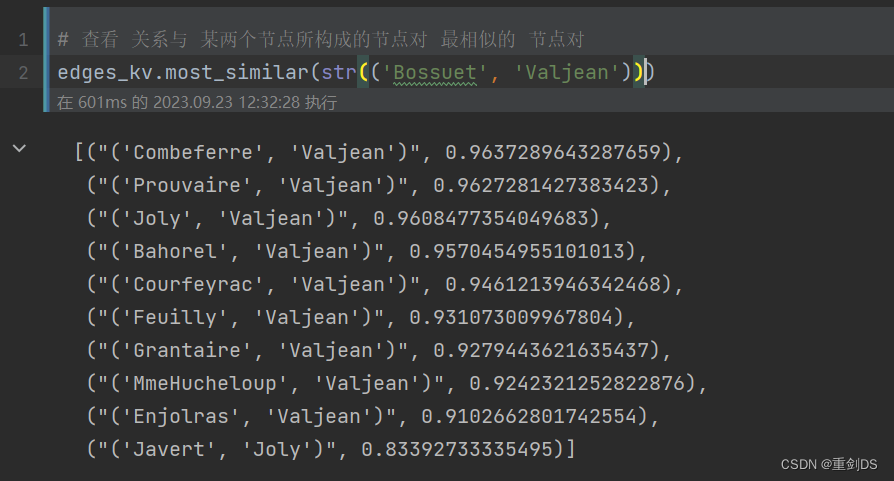
7. 找到和拿破仑相似的节点
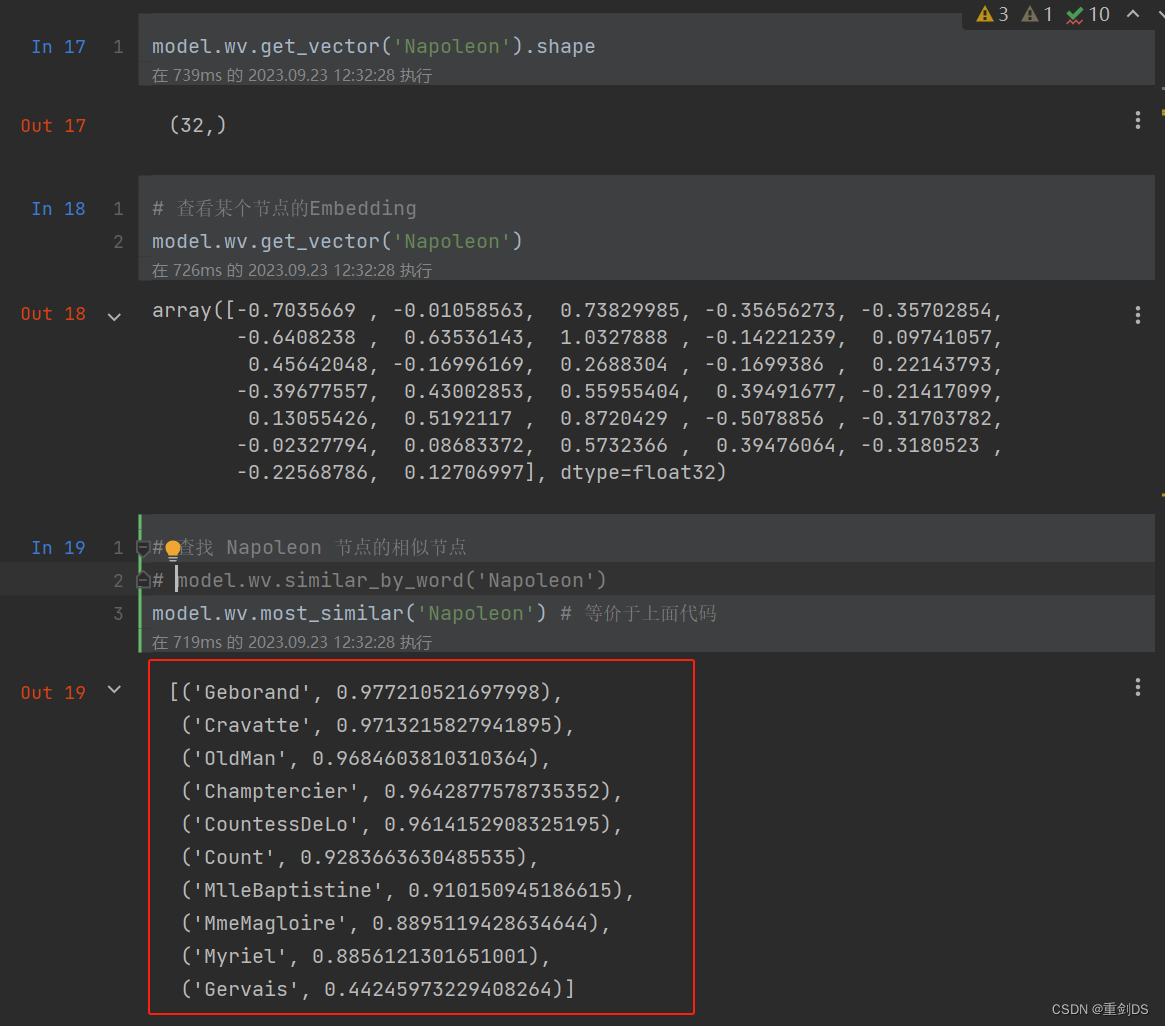
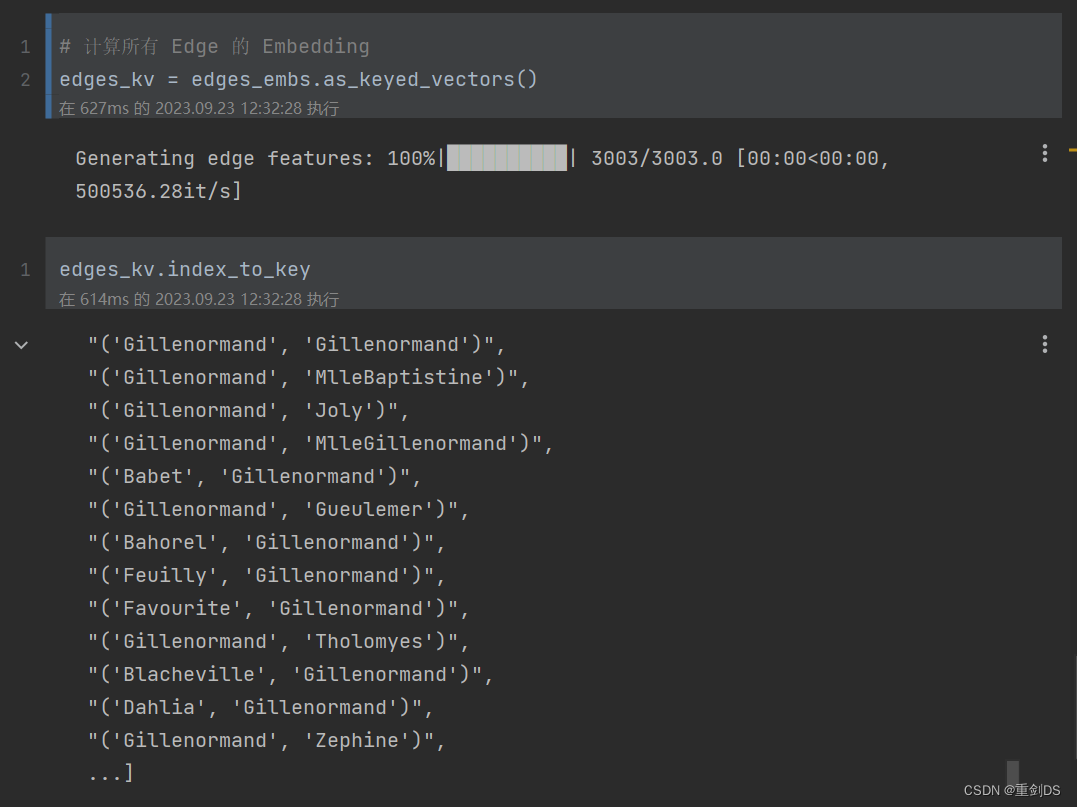
8. 对edge连接进行embedding
from node2vec.edges import HadamardEmbedder # 导入工具包# Hadamard 二元操作符:两个 Embedding 对应元素相乘
edges_embs = HadamardEmbedder(keyed_vectors=model.wv)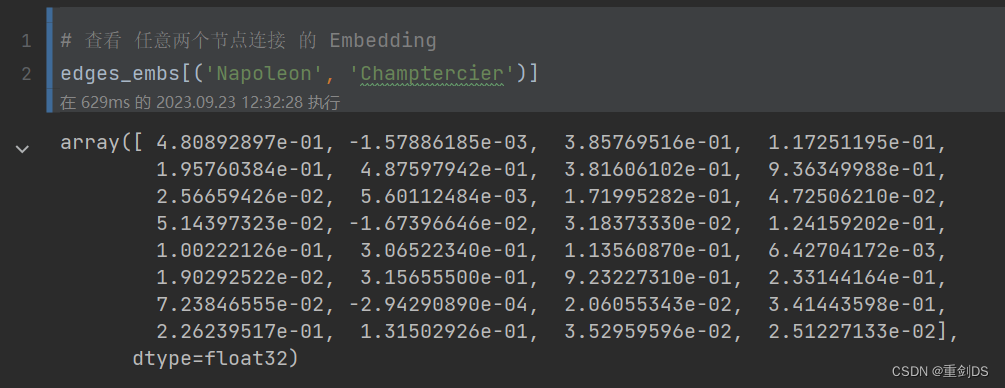
后言:虽说调包也不用考虑什么原理问题(),但是针对O(1)的采样方法alias sampling我还是想说下我自己对此的理解,大佬解说的视频:
因为好像有可能事件的概率不一定是相等的,就是不均匀的,一开始我还想用哈希表,用key:概率区间的某个值,value:事件编号,发现好像即使是0~1里面都有无数个实数,那就不可能hash了()
也就是如果“把四个柱子加在一起,然后直接让它们原本的大小等于自己的区间长度”,不太可能存在 概率映射到事件 的情况。
但是经过alias sampling以后,直接都是均匀的,其实就可以直接定位到某个区间了,剩下就取alias事件或者是原来的事件就行了,因为那个区间只可能是这两种情况 。
这篇关于Node2Vec实战---《悲惨世界》人物图嵌入的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





