本文主要是介绍对话王小川:很多人认为我适合做大模型 用搜狗老班底更易磨合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

雷递网 雷建平 8月8日
百川智能创始人、CEO王小川在发布会上对雷递网表示,做大模型比做搜索更吸引人。
百川智能团队已有百人的规模,核心高管及很多员工均来自搜狗,包括前搜狗COO茹立云、前搜狗CMO洪涛、前搜狗搜索总经理陈炜鹏均已加盟。
王小川说,搜狗老班底互相之间有信任,会更优先归队。
当前,百川智能已获得5000万美元启动资金,来自王小川与其业内好友的个人支持。王小川对雷递网透露,百川智能首次融资时,估值已经超过5亿美元,下一轮融资,估值就会超过10亿美元。
谈及下一轮融资是否已完成时,王小川说,融资非常顺利,但现在还不能公布情况。
百川智能会加快商业化
2023年7月,百川智能发布参数量130亿通用大语言模型Baichuan-13B-Base、对话模型Baichuan-13B-Chat及其INT4/INT8两个量化版本。
今日,百川智能发布第三个模型baichuan-53B,其具有搜索增强、对齐能力等特点。所谓搜索增强是解决模型时效性和幻觉的有效手段,将搜索技术与大语言模型能力相结合,实现创新性的模型优化与改进。
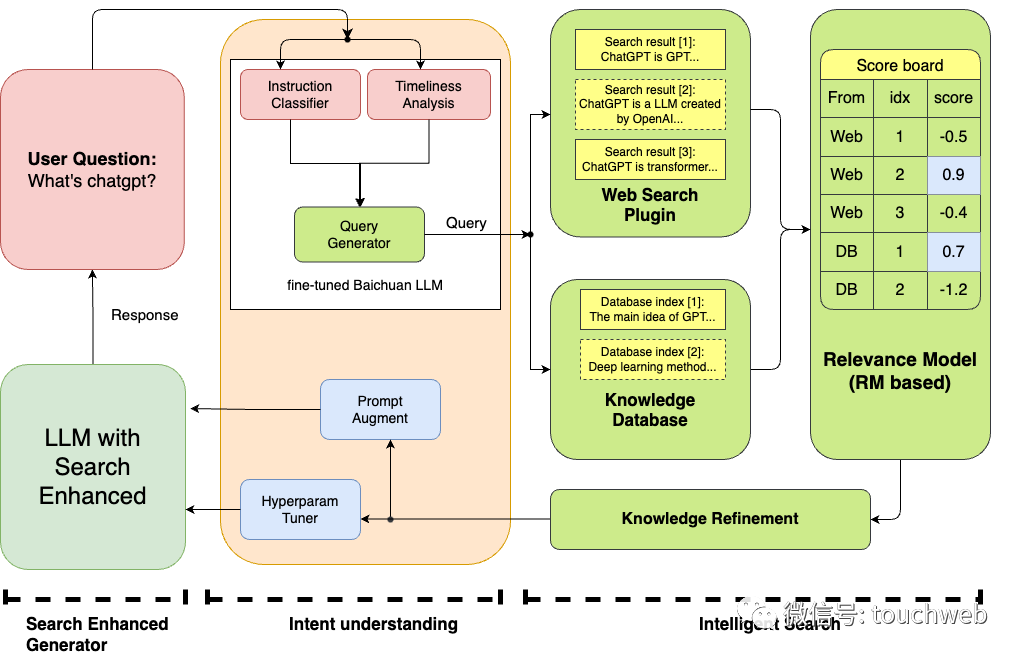
百川智能称,baichuan-53B的搜索增强系统融合了多个模块,包括指令意图理解、智能搜索和结果增强等关键组件。这一综合体系通过深入理解用户指令,精确驱动查询词的搜索,并结合大语言模型技术来优化模型结果生成的可靠性。通过这一系列协同作用,我们实现了更精确、更智能的模型结果回答,减少了模型的幻觉。
搜索结果的质量直接决定了回答生成的质量。低质量的搜索结果可能导致生成的回答质量下降。
为解决这个问题,百川智能构建一个搜索结果相关性模型,该模型对从搜索内容和知识库中获取的信息进行相关性评分。通过这种方法,我们可以筛选出高质量的搜索引用内容,减少在知识抽取阶段引入的无关、低质量的信息;该相关性模型也可以作为RM模型,用于在RL训练阶段进一步优化意图理解模型,提高其对人类指令的对齐度,并更高效地调用搜索引擎。
王小川说,2023年4月10日到6月15日的2个月零5天,百川智能开发了第一款7B的开源模型,模型发布后超出大家想象速度得快。大家通常认为发一个模型至少要半年的时间,到数据积累准备,到训练,到发,百川智能只用了2个的时间。7月11日,百川智能发了第二款模型13B,130亿的参数。这个模型能力比原来的能力又有明显的提升。
“今天是立秋这天,我们发了第三个模型,baichuan-53B,跟之前相比参数规模大了很多。”王小川称,百川智能下个月会开放API,甚至开放后面的组件,帮助大家更好地去做对齐,强化,也有相关的数据库等对接,把2B的服务优先做起来。
近期,前搜狗CMO洪涛入职百川智能,负责商业化方面业务。洪涛已经开始了招聘,称急需各类商业人才。
王小川透露,洪涛加盟后,百川智能会加快商业化。
很多人认为王小川适合做大模型
自腾讯合并搜狗后,王小川沉寂了有近两年时间,直到ChatGPT火热,王小川才又高调的投入到了AI浪潮,很多搜狗旧部跟随王小川重新创业。
王小川对雷递网表示,这次做大模型有一些比较有意思的地方。比如,有些朋友跟王小川说:“小川,你特别适合做大模型”,恰恰它又是原来积累语言相关的AI能力,正好能用到原来的技术,包括对数据的积累。
王小川说,大家对可能数据、算法、算力都听得很多,而数据里面,搜索公司对数据的理解和实操最多,之前做搜索天天要面对怎么样找数据。同时大家提到算法,以前在AI发展的时候大家慢慢忘了搜索本身也是AI做的事情。而现在做大模型要高质量、多样化、有权威的、规模巨大的数据。
“包括搜狗在腾讯并购的时候,我们当时一查资产,在线的服务是1.2万颗GPU,也是强AI的公司,尤其CV,大家知道CV代表了AI,但大家知道今天大模型应用的是LLM(语言模型),其实语言也是原来做搜索做输入法相应的积累,而且也是算法工程的迭代。”
王小川还回想了一下,说一直没有一个人说“小川,你特别适合做搜索”。“我干了20多年的搜索大家都没这么说,而今天做大模型和搜索有非常多的类似之处。”
王小川认为,这次做大模型,比原来做搜索更吸引人,尤其是对搜狗而言。搜狗是百度之后大概4年的时候开始做。互联网晚半年就是了不得的事情,晚4年开始做,一直处于跟随的位置,也在创新在突破里会难很多。
“做大模型则刚刚赶上大的时代变化,我们从信息时代走向智能时代,这次搜狗老班底愿意一起做,是有无数多的事情可以做,此外,之前亲密无间的合作,搜狗老班底互相之间有很好的信任。还有一点不同在于,创业公司会有失败率,但创业成功之后股权回报比在搜狗时会多很多。”
投身大模式浪潮创业,正好是迎接了风口。如今的百川智能,与搜狗办公楼很近。站在这里,甚至可以看清对楼窗边的办公环境。
王小川说,当初搜狗想从清华拉人就很费劲,而今天,无论是找字节跳动,还是腾讯、阿里的员工,还有搜狗的同学,及其他优秀的人都会愿意加入。而且,大模型公司起步就不一样,要迅速进入到大的“战役”。
一方面创业公司拿到很多钱互相卷,还有大厂之间的竞争,大厂有更多的钱,更多人,更多算力进来,迅速形成一个战斗力。这种情况下,王小川就优先把搜狗老班底拉进来,大家能迅速磨合,才能适应这么大的挑战。
这自然带来的压力巨大。就在近期,有AI行业创业者因抑郁,暂时离岗,引发了外界对创业者心理健康的问题,尤其是做大模型是否压力过大。
对此,王小川说,“没有技术背景做决策,最终会非常痛苦。相对而言,我们的进度是在一个快乐的状态。”
———————————————
雷递由媒体人雷建平创办,若转载请写明来源。


这篇关于对话王小川:很多人认为我适合做大模型 用搜狗老班底更易磨合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









