本文主要是介绍论文研读|TextBack: Watermarking Text Classifiers using Backdooring,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
- 论文信息
- 文章简介
- 研究动机
- 研究方法
- 水印生成
- 水印嵌入
- 版权验证
- 实验结果
- 保真度 & 有效性
- 消融实验
- 方法评估
- 相关文献
论文信息
论文名称:TextBack: Watermarking Text Classifiers using Backdooring
作者:Nandish Chattopadhyay, et al. Nanyang Technological University Singapore
发表年份:2022
发表会议:DSD
开源代码:无
文章简介
本文提出一种使用黑盒水印方式保护文本分类模型的方法。通过构建触发集,将其混入干净训练数据微调预训练模型,嵌入水印。(不使用基于FromScratch的方法从头开始训练模型是为了减少不必要的计算资源浪费)
研究动机
现有的模型水印及其攻击方法主要围绕CV领域展开[5,13],而对于自然语言处理领域的模型保护仍处于起步阶段。基于此,本文借鉴后门攻击的思想,提出一种保护文本分类模型的黑盒水印方法。
研究方法
水印生成
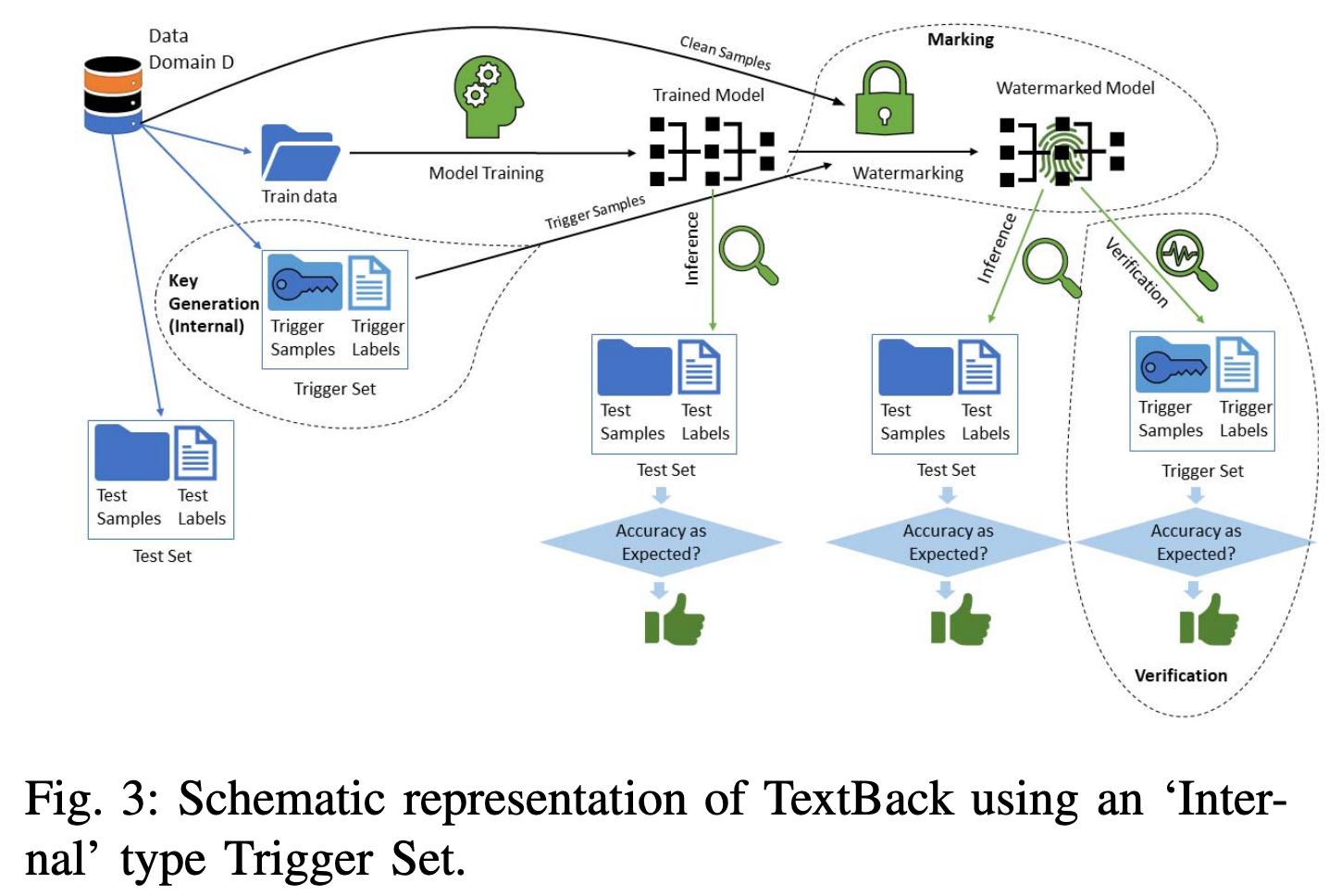
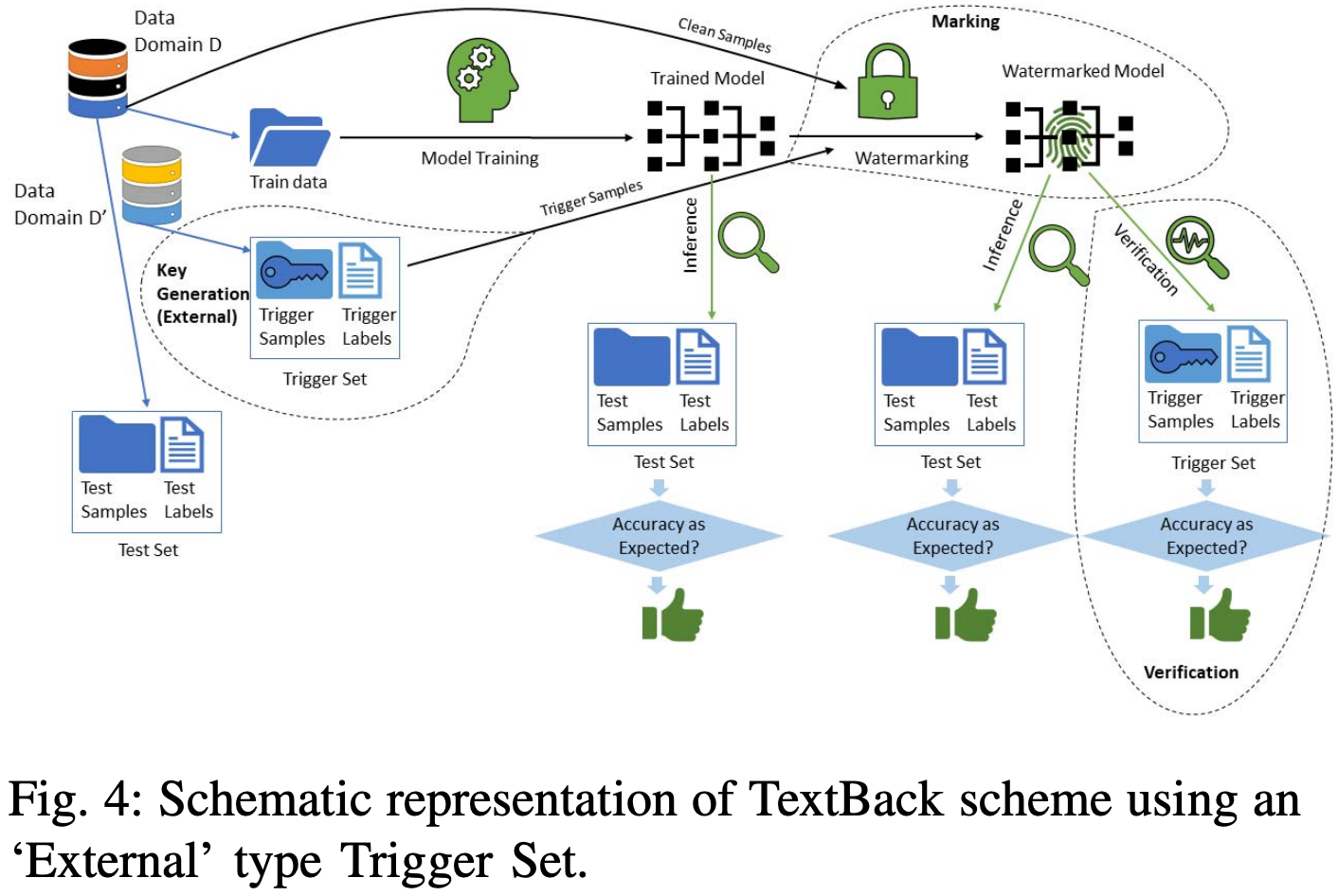
本文介绍了两种触发集构造方法:(1)训练数据内选取触发样本(Intra-domain);(2)训练数据外选取触发样本(Inter-domain)。对选取出的触发集样本,保持文本不变,只修改标签为水印标签,实现了clean-text的触发集构建。
水印嵌入
首先使用干净训练数据训练模型得到预训练模型,然后将使用上述方式构建好的触发集其混入干净训练数据微调预训练模型,嵌入水印。 Figure 3 和 Figure 4 分别展示了通过 Intra-domain 和 Inter-domain 构造触发集并进行水印嵌入的流程。
版权验证
将触发集中的样本输入待检测模型中,若模型的预测准确率超过一定阈值,则认为该模型含有水印。
实验结果
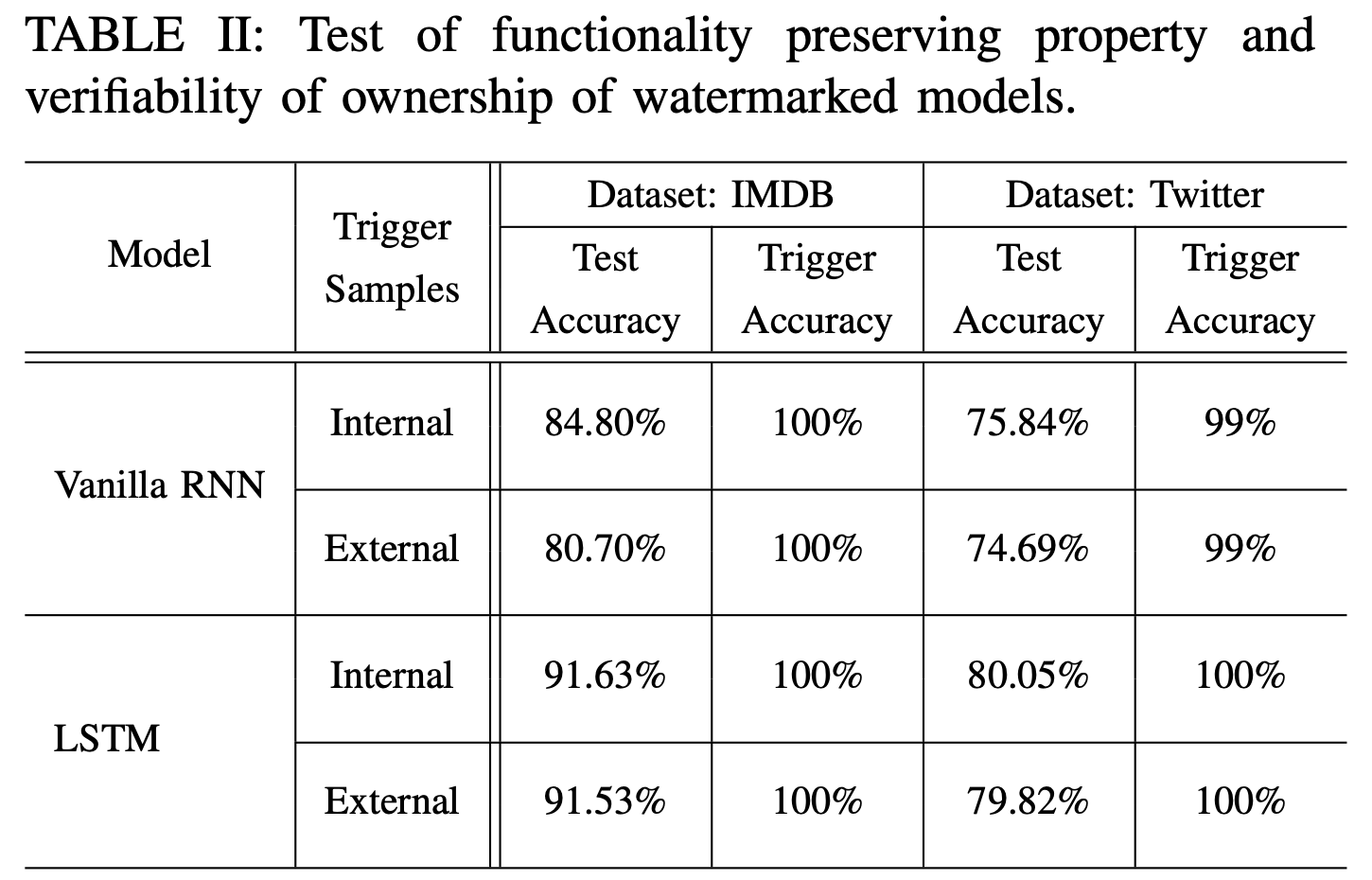
本文在 IMDB 和 Twitter 两个数据集上进行了测试。选取 vanilla RNN 和 LSTM 作为测试模型。文章首先给出了不含水印模型在原始测试集和触发集上的测试性能,说明不含水印模型无法达到版权验证的效目的。
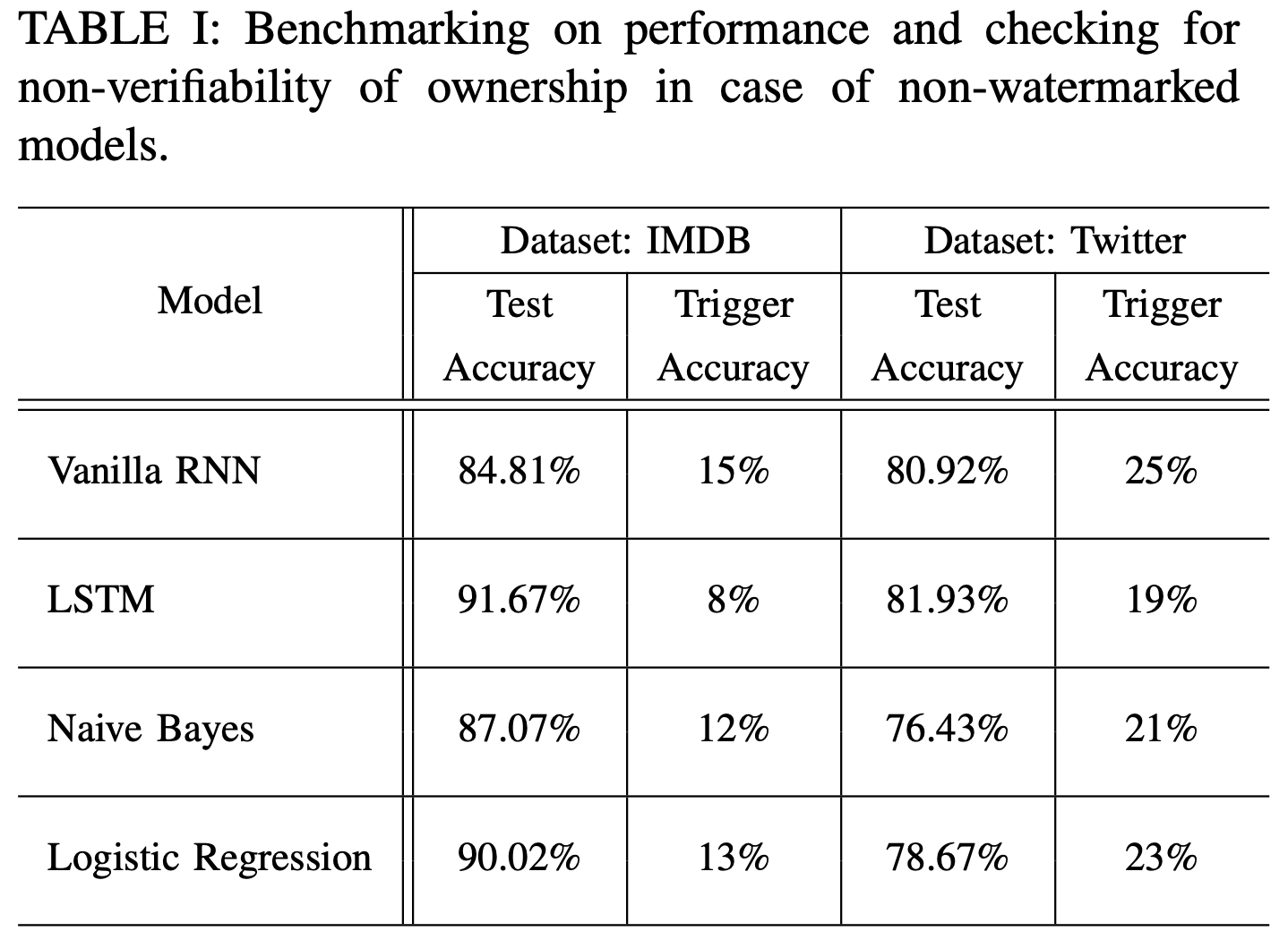
5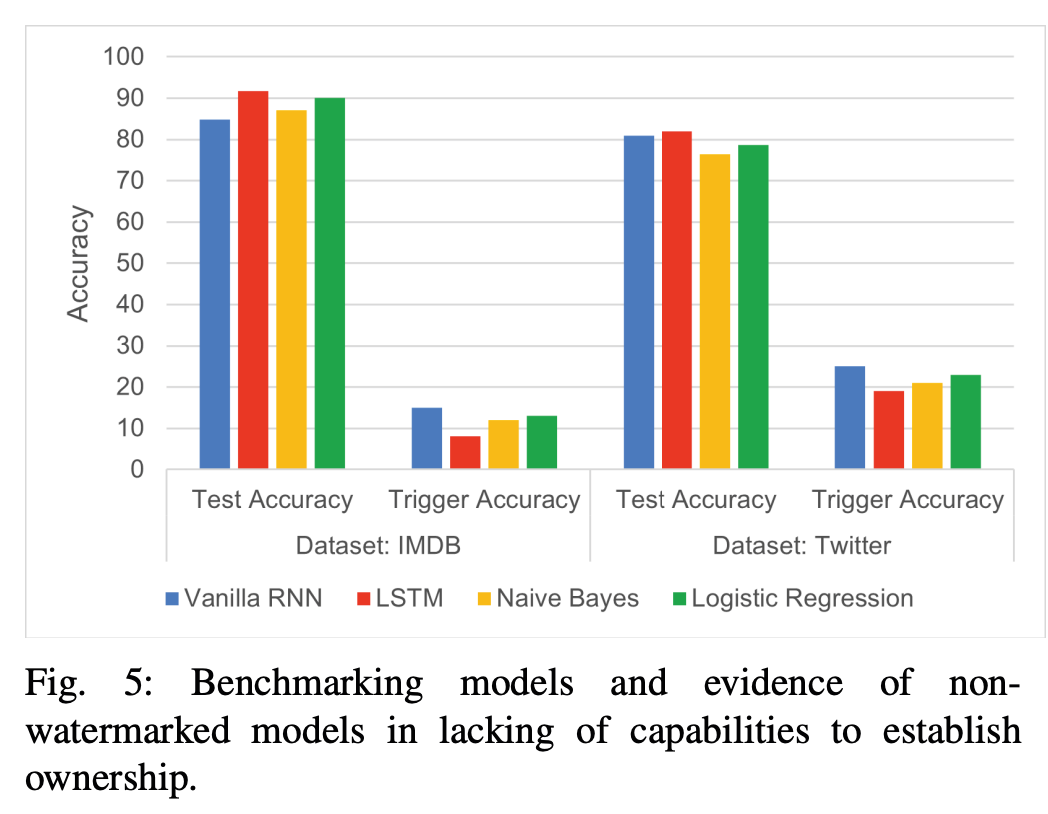
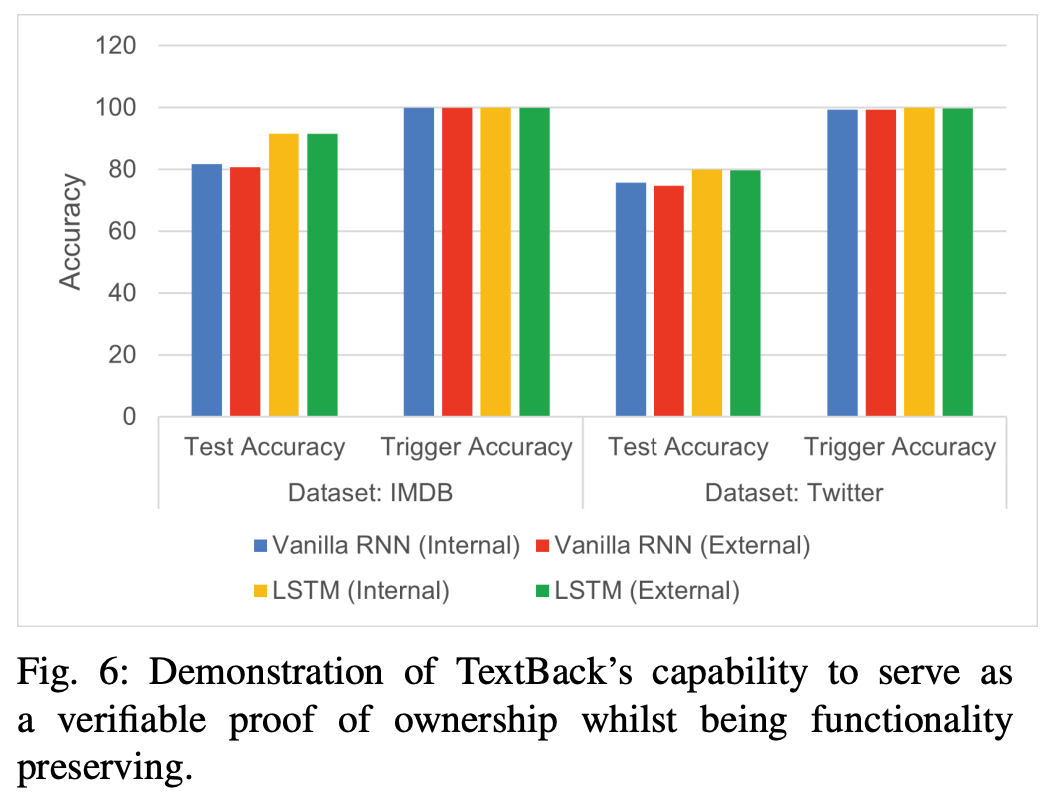
保真度 & 有效性
消融实验
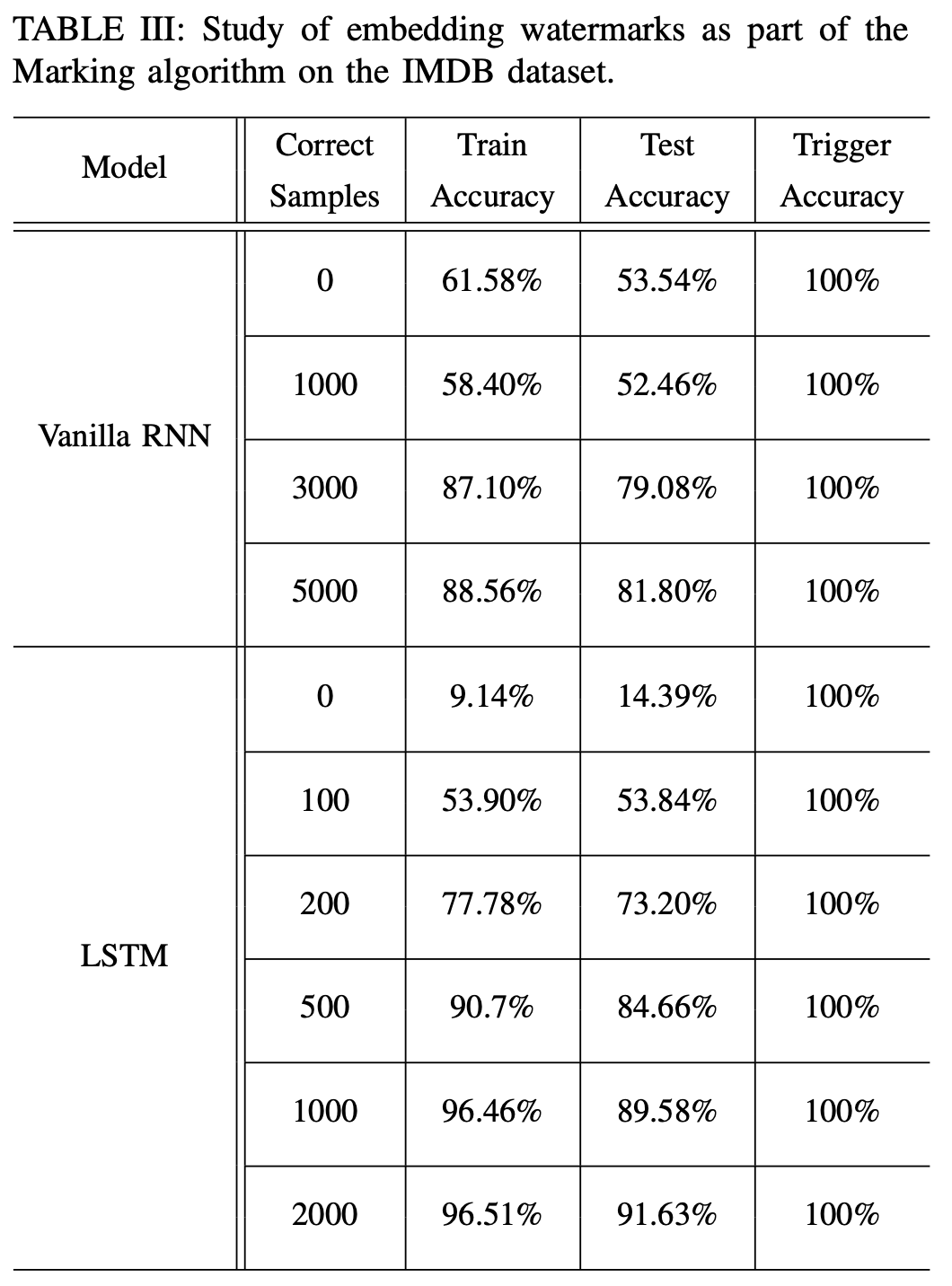
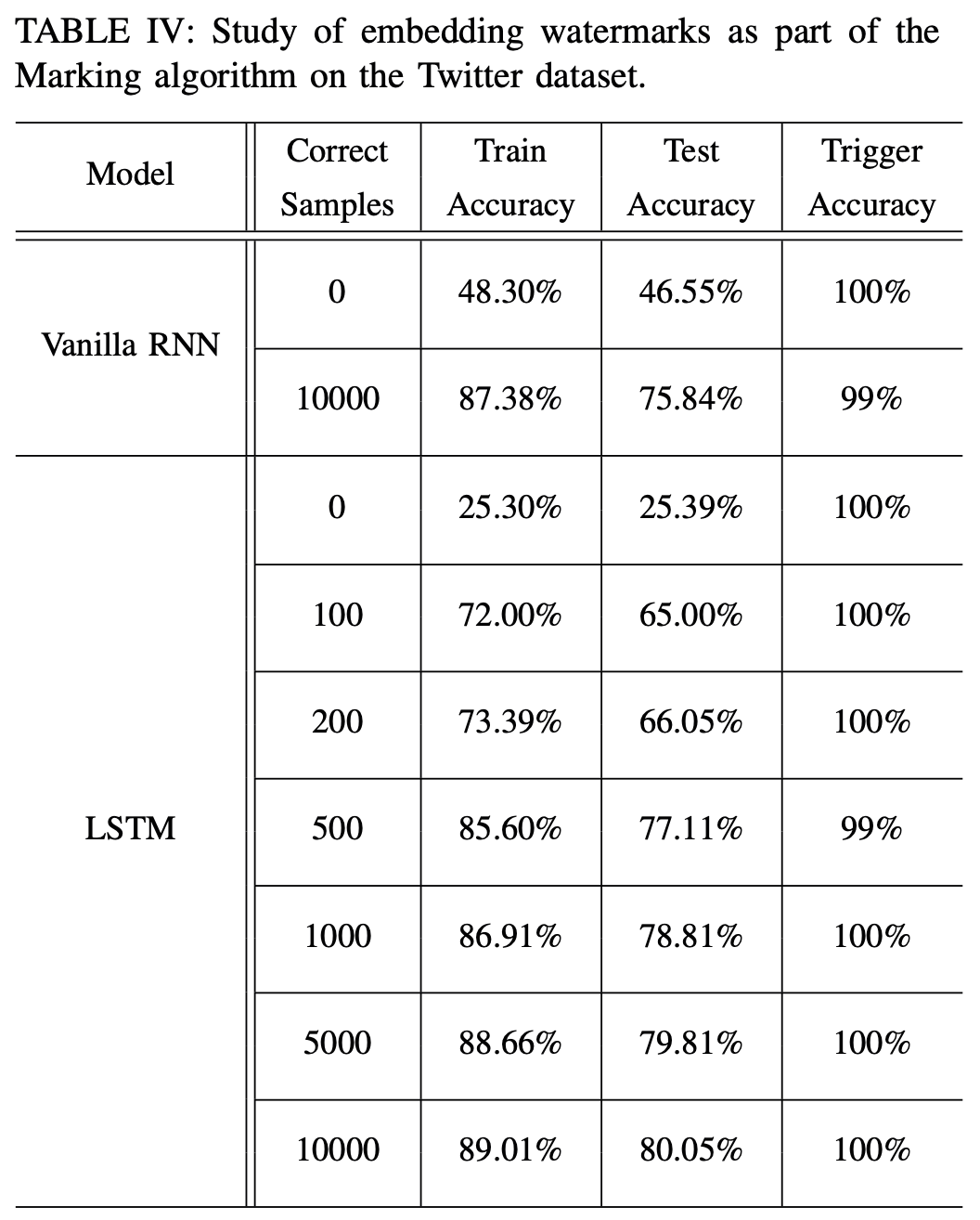
本实验验证了在微调阶段,clean samples 的数量对于模型预测结果的影响,可以看到,微调时必须混入足够数量的clean samples,才能保证原始任务的精度。
方法评估
这个方法是把[13]中的方法CV迁移到NLP中,文章出自同一个团队,图也大差不差……而且触发集的构造方式也没有多少新意,和这篇文章中clean-image+label change的思路类似,只不过这里是clean-text+label change;此外,internal & external 借鉴这篇文章中触发集的构造思路,分别从训练数据内外选取触发样本进行修改。而且本文没有展示鲁棒性实验,不清楚这种方法对于剪枝和微调等攻击手段的鲁棒性。
相关文献
[5] H. Chen, B. D. Rouhani, and F. Koushanfar, “Blackmarks: Blackbox multibit watermarking for deep neural networks,” arXiv preprint arXiv:1904.00344, 2019.
[6] H. Chen, B. D. Rohani, and F. Koushanfar, “Deepmarks: a digital fingerprinting framework for deep neural networks,” ICMR, 2019.
[7] B. D. Rouhani, H. Chen, and F. Koushanfar, “Deepsigns: A generic watermarking framework for protecting the ownership of deep learning models.” ASPLOS, 2019.
[8] S. Szyller, B. G. Atli, S. Marchal, and N. Asokan, “Dawn: Dynamic adversarial watermarking of neural networks,” ACM Multimedia, 2021.
[9] H. Chen, C. Fu, J. Zhao, and F. Koushanfar, “Deepinspect: A black-box trojan detection and mitigation framework for deep neural networks.” in IJCAI, 2019, pp. 4658–4664.
[10] W. Guo, L. Wang, X. Xing, M. Du, and D. Song, “Tabor: A highly accurate approach to inspecting and restoring trojan backdoors in ai systems,” arXiv preprint arXiv:1908.01763, 2019.
[11] N. Chattopadhyay, C. S. Y. Viroy, and A. Chattopadhyay, “Re-markable: Stealing watermarked neural networks through synthesis,” in International Conference on Security, Privacy, and Applied Cryptography
Engineering. Springer, 2020, pp. 46–65.
[12] Y. Adi, C. Baum, M. Cisse, B. Pinkas, and J. Keshet, “Turning your weakness into a strength: Watermarking deep neural networks by backdooring,” USENIX, 2018.
[13] N. Chattopadhyay and A. Chattopadhyay, “Rowback: Robust watermarking for neural networks using backdoors,” in 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA). IEEE, 2021, pp. 1728–1735.
这篇关于论文研读|TextBack: Watermarking Text Classifiers using Backdooring的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

