本文主要是介绍pack_padded_sequence and pad_packed_sequence,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
此文章为阐述pytorch中pack_padded_sequence 和pad_packed_sequence的原理
在变长序列文本中,一个batch中的各样本长度可能不一致,在使用RNN模型时,需要填充至统一长度,被填充的位置实际无意义。我们通常取最后一个时刻的输出作为最终输出,但是填充后的最后时刻并非是原样本的最后时刻。为了获取每个样本真实的最后时刻位置输出,便有了pack_padded_sequence 和pad_packed_sequence。
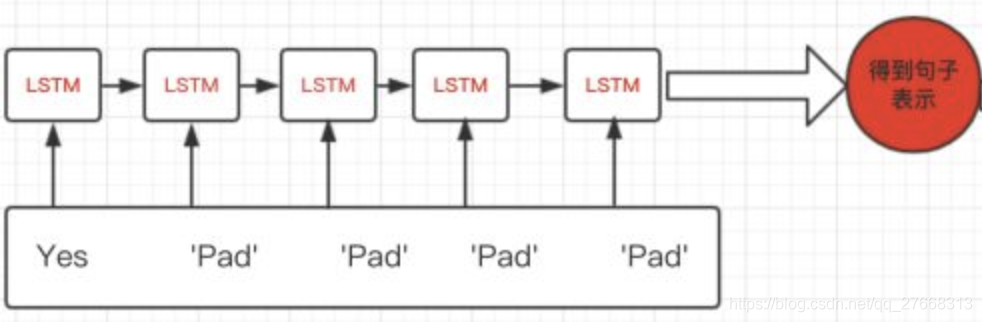
如下图,句子yes被填充4个pad,为了获取句子的句向量,取最后时刻的输出,即最后一个pad位置的输出。但最自然的想法是获取yes位置的输出作为句向量。
-
pack_padded_sequence
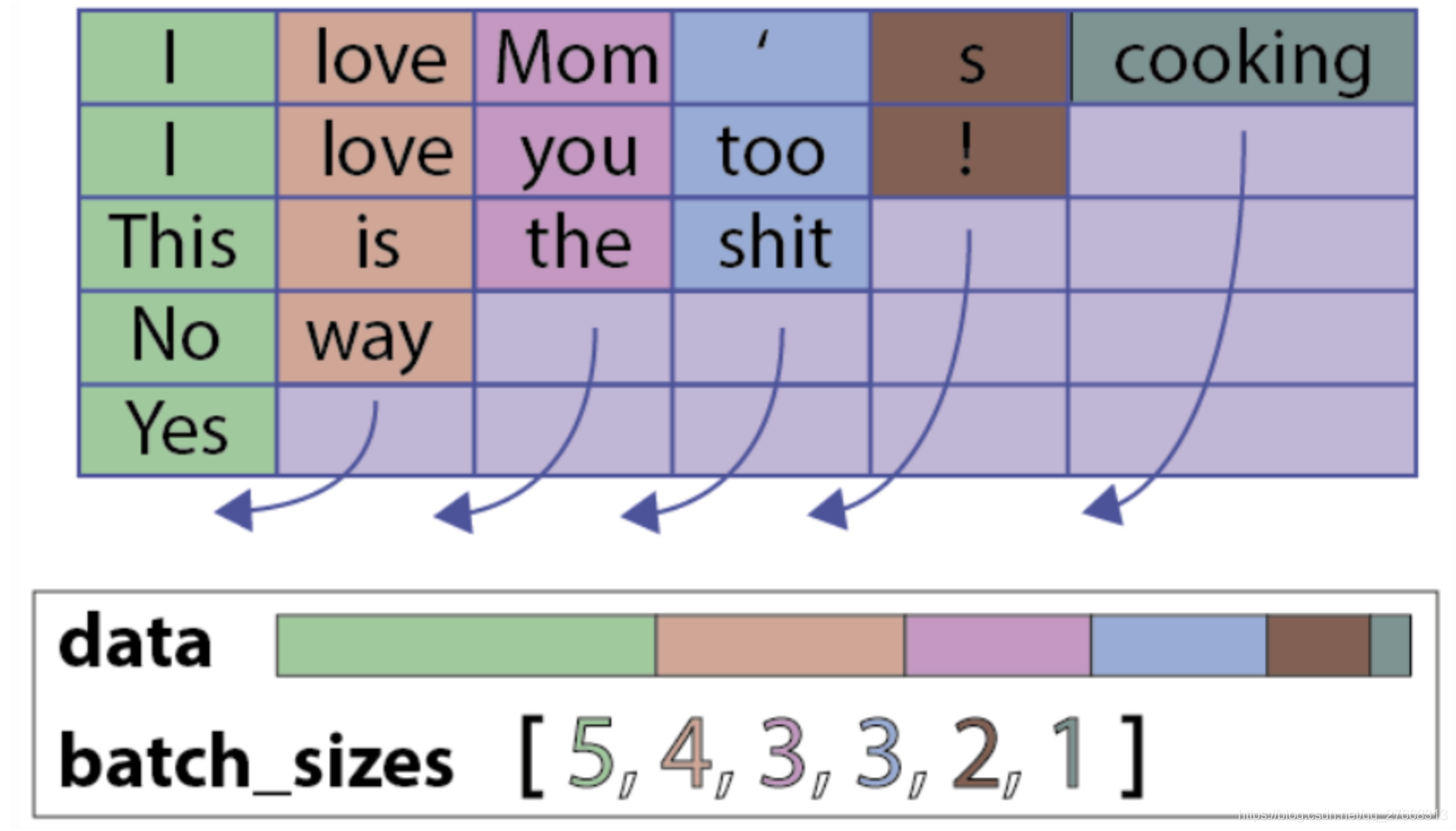
pack可理解为压缩,将一个batch中的样本按列压缩为一个序列。例如一个batch的样本为:
[[1, 2, 3, 4],
[2, 3, 5],
[6,7],
[8]]
压缩后为:
[[1, 2, 6, 8],
[2, 3, 7],
[3, 5],
[4]]
每个样本的第一列元素组成第一个列表,依次类推。
这种形式和压缩前并无区别,为此,我们将序列变为一个list,即:
[1, 2, 6, 8, 2, 3, 7, 3, 5, 4]
变成这样后,为了方便还原成原形式,还记录原来每个list的长度:
size = [4, 3, 2, 1]
所以经过pack_padded_sequence后,我们得到两个列表:
data=[1, 2, 6, 8, 2, 3, 7, 3, 5, 4]和size=[4, 3, 2, 1]
在输入RNN时,按照[4, 3, 2, 1]的顺序,第一次输入data中4个值,然后输入3个值,以此类推。
完整示例图如下:
-
pad_packed_sequence
和pack_padded_sequence相反,该函数把压缩的序列再填充回来。默认填充为0。
[[1, 2, 3, 4],
[2, 3, 5, 0],
[6, 7, 0, 0],
[8, 0, 0 ,0]]
实际值并非是原值,因为经过RNN后,输出值其维度和大小均与原值不同,此处只是为了方便理解函数,直接在原值中填充0。实际效果可看下面代码 -
代码
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn import utilsbatch_size = 4
max_length = 4
hidden_size = 2
n_layers = 1# 实际上需要先按长度由大到小排好序,此处已排序好,并用0 pad为同一长度
input = torch.FloatTensor([[1, 2, 3, 4],[2, 3, 5, 0],[6,7, 0, 0],[8, 0, 0, 0]]).resize_(4, 4, 1)
input = Variable(input)
seq_len = [4,3, 2,1] # 每个样本的长度pack = utils.rnn.pack_padded_sequence(input, seq_len, batch_first=True)
print(pack) # 输出压缩后的结果rnn = nn.RNN(1, hidden_size, n_layers, batch_first=True)out, _ = rnn(pack)
print(out) # 输出RNN输出结果unpacked = utils.rnn.pad_packed_sequence(out, batch_first=True)
print(unpacked) # 输出扩充后的结果
输出压缩后的结果:

输出RNN输出结果:
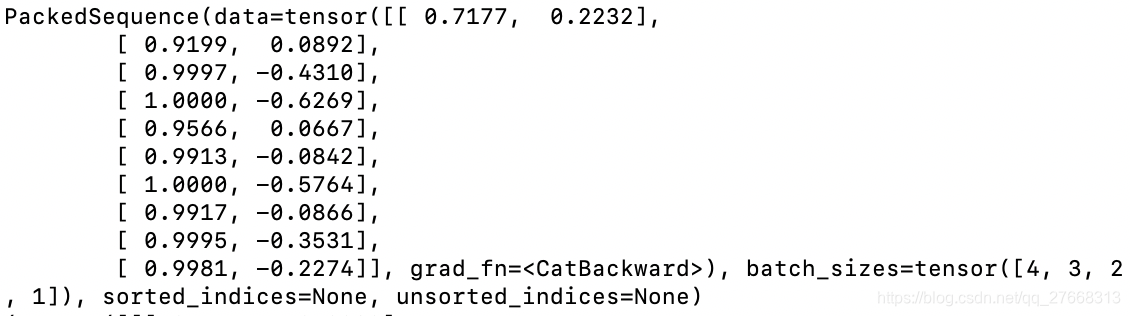
因为代码中设置hidden_size=2,所以每个值输出为两个值,例如原值中[1.]输出结果为第一行的[0.7177, 0.2232]
输出扩充后的结果:

这篇关于pack_padded_sequence and pad_packed_sequence的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






