本文主要是介绍阿里架构之旅(三)——动物园管理者zookeeper,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们来说一下zookeeper,它翻译为中文的意思是:动物园管理者,可是这跟我们的架构有什么关系呢?接着看。之前我们谈到了dubbo,在dubbo解析中,我们提到了一种注册服务的机制,但是当时并不知道那是个什么东东,今天我们就来揭晓答案。
一、是什么
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、 小猪(Pig) 的管理员,也就是说它是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
它为分布式系统提供了高效可靠且易于使用的协同服务,它可以为分布式应用提供相当多的服务,诸如统一命名服务,配置管理,状态同步和组服务等。
说的这么抽象,它到底是个什么呢。
简单的说,zookeeper=文件系统+通知机制。1、文件系统
Zookeeper维护一个类似文件系统的数据结构:
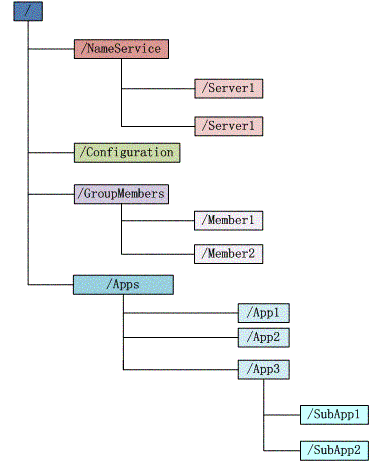
每个子目录项如 NameService 都被称作为 znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
PERSISTENT-持久化目录节点客户端与zookeeper断开连接后,该节点依旧存在
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
EPHEMERAL-临时目录节点客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
2、 通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
二、做什么
1、 命名服务
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。Name Service 已经是 Zookeeper 内置的功能,你只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。
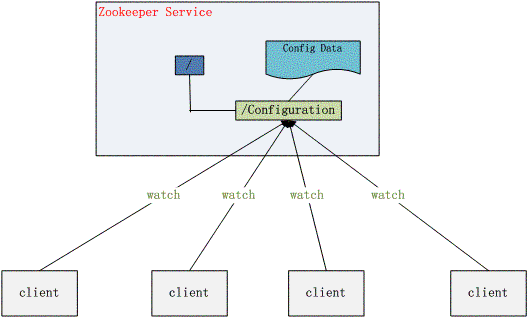
2、 配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。好吧,现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
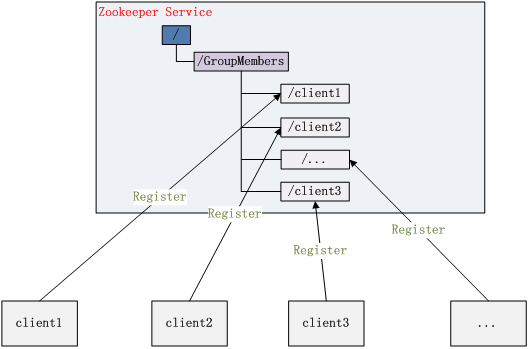
3、 集群管理
Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个master知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它节点必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让master知道。Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个master,让这个master来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。
它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。
Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server 编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL 节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前 Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
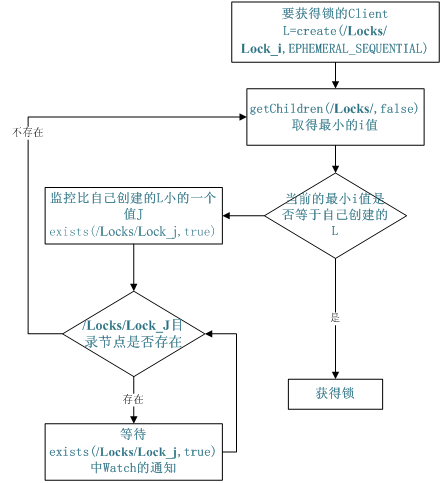
4、 分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。厕所有言:来也冲冲,去也冲冲,用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
5、队列管理
Zookeeper 可以处理两种类型的队列:
(1)同步队列:当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。同步队列用 Zookeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
(2)FIFO 队列:先进先出队列,例如实现生产者和消费者模型。FIFO 队列用 Zookeeper 实现思路如下:
实现的思路也非常简单,就是在特定的目录下创建 SEQUENTIAL 类型的子目录 /queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证 FIFO。
三、产生背景
有这样一个场景:系统中有大约100w的用户,每个用户平 均有3个邮箱账号,每隔5分钟,每个邮箱账需要收取100封邮件,最多3亿份邮件需要下载到服务器中(不含附件和正文)。用20台机器划分计算的压力,从 多个不同的网路出口进行访问外网,计算的压力得到缓解,那么每台机器的计算压力也不会很大了。
通过我们的讨论和以往的经验判断在这场景中可以实现并行计算,但我们还期望能对并行计算的节点进行动态的添加/删除,做到在线更新并行计算的数目并且不会影响计算单元中的其他计算节点,但是有4个问题需要解决,否则会出现一些严重的问题:
20台机器同时工作时,有一台机器down掉了,其他机器怎么进行接管计算任务,否则有些用户的业务不会被处理,造成用户服务终断。
随着用户数量增加,添加机器是可以解决计算的瓶颈,但需要重启所有计算节点,如果需要,那么将会造成整个系统的不可用。
用户数量增加或者减少,计算节点中的机器会出现有的机器资源使用率繁忙,有的却空闲,因为计算节点不知道彼此的运行负载状态。
怎么去通知每个节点彼此的负载状态,怎么保证通知每个计算节点方式的可靠性和实时性。
先不说那么多专业名词,白话来说我们需要的是:1记录状态,2事件通知 ,3可靠稳定的中央调度器,4易上手、管理简单。
采用Zookeeper完全可以解决我们的问题,分布式计算中的协调员,观察者,分布式锁 都可以作为zookeeper的关键词,在系统中利用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁等功能,利用这些特色在分布式计算中发挥重要的作用。
总结:
今天我们介绍了一下zookeeper,知道了它是一个文件系统+通知机制,这也就使它可以作为dubbo的一个服务注册机制来管理分布式服务,而至于它的工作原理,我们将在下次博客中继续说明,请大家继续关注。
这篇关于阿里架构之旅(三)——动物园管理者zookeeper的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







