本文主要是介绍脑电公开数据集解码准确率再创新高, Weight-Freezing立大功,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

鉴于人工神经网络(ANN)具有强大的特征提取和分类能力,它们正在成为BCI 应用中解码EEG 信号的热门选择(Schwemmer et al. (2018); Acharya et al. (2018))。例如,Schirrmeister 等人(2017)探索了Shallow-ConvNet 和Deep-ConvNet 在MI 和运动执行(ME)EEG 信号中的特征提取能力(Schirrmeister et al. (2017))。Lawhern 等人(2018)在Shallow-ConvNet 解码器中添加了一个时间卷积层,并使用可分离卷积来提高解码器在各种EEG 范式下的性能(Lawhern et al. (2018))。Borra 等人(2020)提出了一种轻量级浅层CNN,它堆叠了一个时间同步卷积层和一个空间深度卷积层,以提取高效的MI 和ME-EEG 特征(Borra et al. (2020))。在我们之前的工作中,我们提出了LMDA-Net,它在原始的时域和空域卷积基础上增加了通道注意力模块和深度注意力模块,以增强各种BCI 任务的特征提取能力(Miao et al. (2023))。这些模型都是端到端的人工神经网络,旨在从特征提取网络的角度增强ANN 对EEG 信号的解码能力。然而,据我们所知,没有工作研究过端到端ANN 中的分类器对EEG 解码性能的影响。其中一个重要原因可能是机器视觉、自然语言处理或EEG 解码中分类器的设置相对固定,通常使用一个或多个全连接层进行分类。这项研究面临的问题是,对于具有低信噪比和小数据量的EEG 信号,现有的全连接网络是否是最优的分类器。
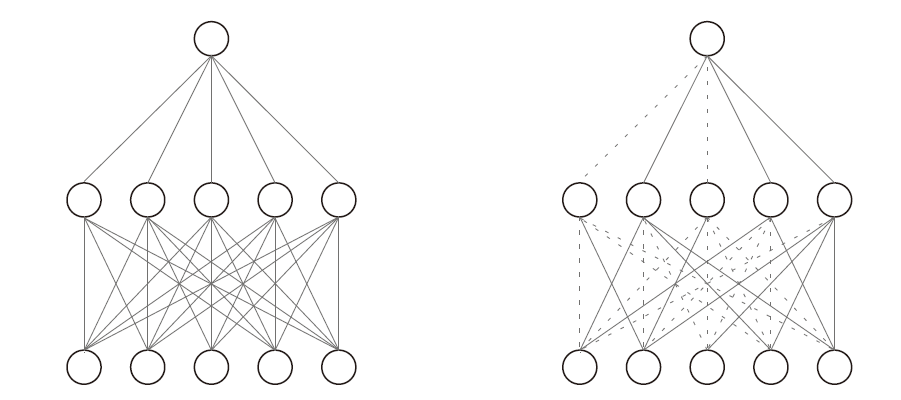
▲图1: Weight-Freezing 前后的比较图。(左图) 标准的全连接网络。(右图) 带有Weight-Freezing 的全连接层。虚线表示冻结的权重。
为了探讨这个问题,本研究提出了一种Weight-Freezing 技术。顾名思义,Weight-Freezing 在全连接层的反向传播过程中冻结了部分权重。如图1所示,与全连接网络相比,Weight-Freezing 抑制了全连接网络中一些参数的更新,从而在分类决策过程中有效地抑制了一些输入神经元对决策结果的影响。
# 贡献:
1. 据我们所知,本文是第一篇研究ANN 中分类器对EEG 解码性能影响的论文。为此,我们提出了Weight-Freezing 技术,通过冻结全连接层中的某些参数,抑制了某些输入神经元对特定决策结果的影响,从而实现更高的分类准确性。
2. Weight-Freezing 也是一种新颖的正则化方法,可以在全连接网络中实现稀疏连接。
3. 我们在三个经典解码网络和三个高引用的公开EEG 数据集上对Weight-Freezing 进行了全面验证和分析。实验结果验证了Weight-Freezing 在分类方面的优越性,并在这三个高引用数据集上取得了最先进的分类性能(对所有参与者的分类准确率进行平均)。
本研究另一个贡献在于强化了人工神经网络(ANN)模型在脑机接口(BCI)系统中的应用和实施。同时,它为将来使用更大模型(如transformers Vaswani et al. (2017))解码EEG 信号设定了新的性能基准。最近,(Ahn et al. (2022); Bagchi and Bathula (2022); Zhang et al. (2023); Ma et al. (2023); Song et al.(2023))越来越多的研究人员采用transformer 网络进行EEG 信号解码。这些方法可以视为对现有ANN 模型的丰富,通过更复杂的特征提取网络提高EEG 分类准确性。然而,这些改进不可避免地使得在真实世界的BCI 系统中部署这些ANN 模型变得更加复杂。与之形成鲜明对比的是,我们的研究引入了Weight-Freezing 作为一种创新的减法策略来改进现有的ANN 模型。借助Weight-Freezing ,一些轻量级和浅层的解码网络在相同的公开数据集上超越了所有当前基于transformer 的方法的分类性能。Weight-Freezing 的引入不仅简化了在BCI 系统中部署ANN 模型的过程,还为未来部署更大模型(如transformer)设定了新的性能标准。
# 与Dropout的区别
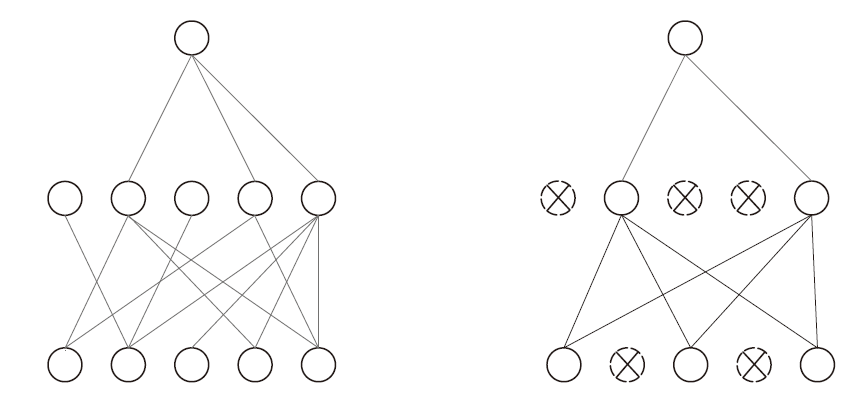
▲图 2: Dropout 与 Weight-Freezing 在正则化时的区别 (左图): 使用 Weight-Freezing 实现正则化。(右图): 使用 Dropout实现正则化。
Weight-Freezing 和Dropout 都可以被视为神经网络中的正则化方法,用于防止过拟合。Weight-Freezing 和Dropout 的实现原理比较如下:
1. 作用目标:Dropout 通过改变神经元的激活状态实现稀疏连接,而Weight-Freezing 通过将掩码部分的可学习参数设为0来实现全连接层的稀疏连接。
2. 信息传递:Dropout 影响前向传播和反向传播,而Weight-Freezing 仅影响反向传播。
3. 作用方式:Dropout 丢弃的神经元完全失去决策能力,而Weight-Freezing 仅影响部分神经元的决策能力。
4. 灵活性:Dropout 和Weight-Freezing 都可以应用于全连接层。此外,由于Dropout 和Weight-Freezing 具有不同的实现原理,它们可以同时使用。
# 实验结果1:
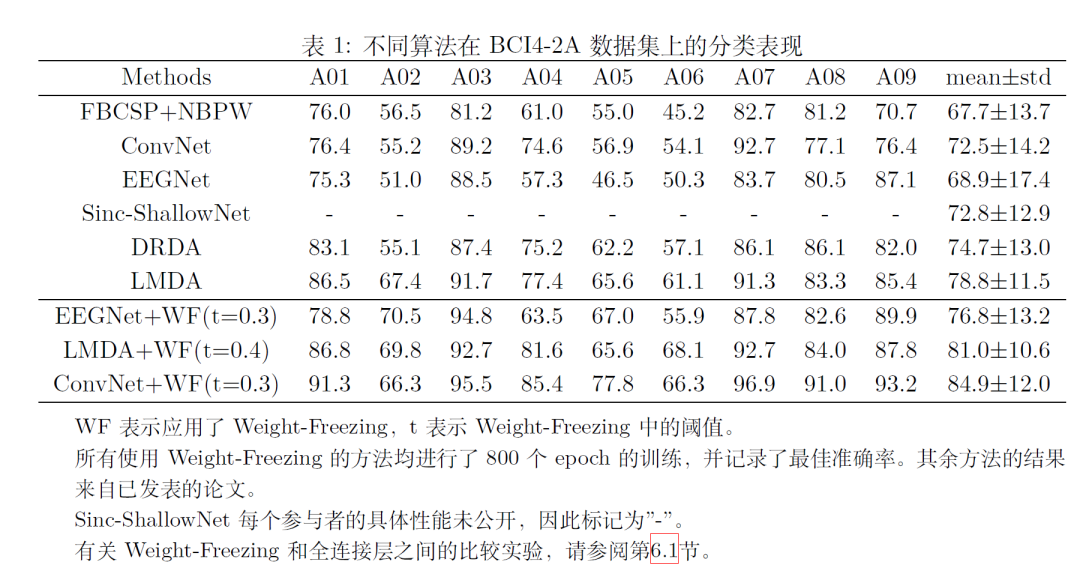
运动想象4分类(BCI4-2A, 22导联, 左手, 右手, 双脚和舌头)
运动想象2分类(BCI4-2B, 3导联, 左手, 右手)

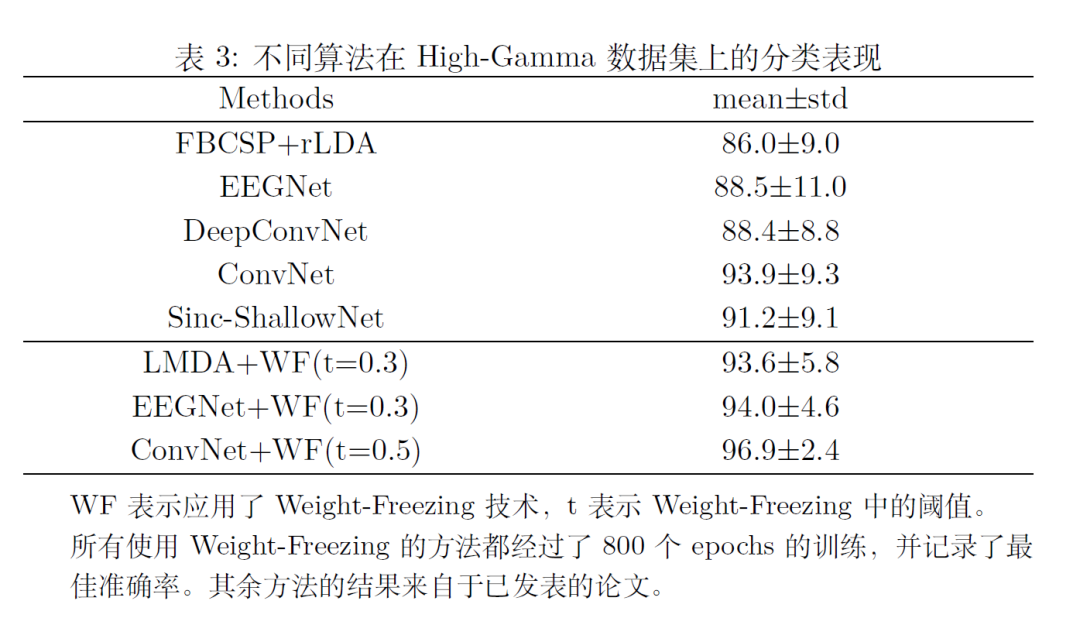
运动执行4分类(High-Gamma, 44导联, 左手, 右手, 双脚, 休息)
# 实验分析
EEGNet, Shallow-ConvNet, LMDA-Net全连接与Weight-Freezing训练对比图. (基准FBCSP+NBPW)
以BCI4-2A四分类运动想象为例, 下图呈现了两个有意思的结论. FBCSP+NBPW是机器学习算法是运动想象中的代表方法, 基于Weight-Freezing的人工神经网络算法在各个被试中的分类表现已经和FBCSP+NBPW拉开了明显的差距.在对EEGNet, Shallow-ConvNet和LMDA-Net进行了200轮训练以后, 这些人工神经网络的分类表现就体现出了优势, 这有望推动人工神经网络在BCI系统中的部署和应用. 另一个有趣的现象是, Weight-Freezing能全面提升EEGNet, Shallow-ConvNet和LMDA-Net的分类表现, 尽管这三个解码架构具有很大的差异性, 但是Weight-Freezing具有很好的通用性.
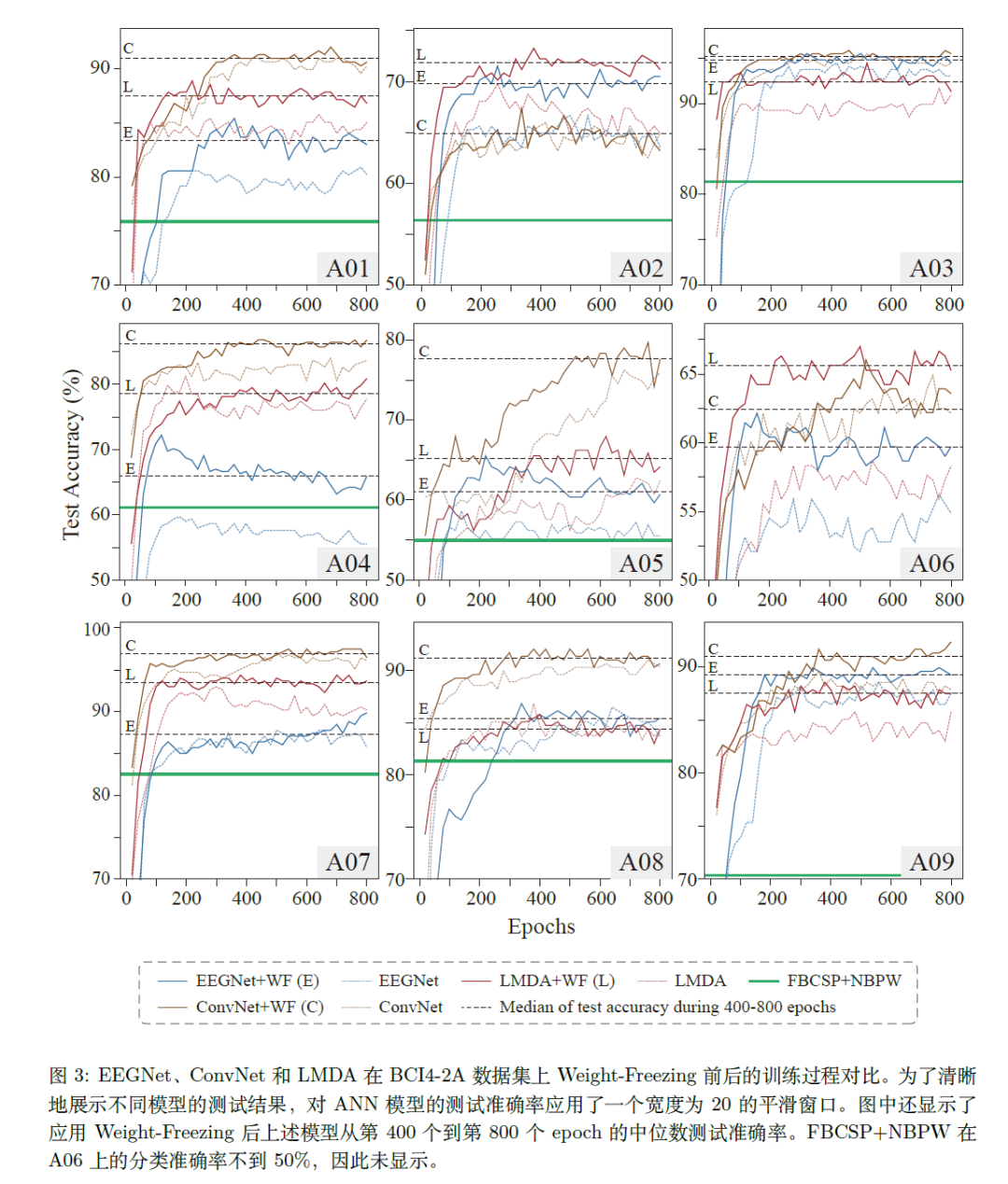
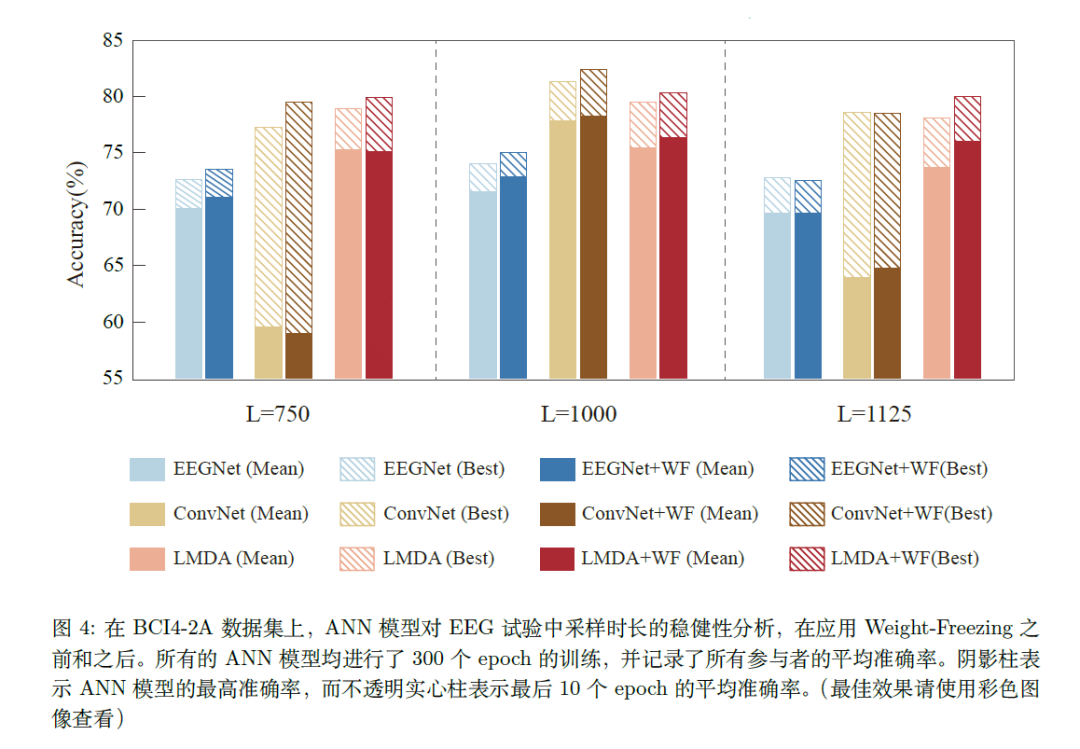
对任务期采样长度的鲁棒性
在分类器鲁棒性的实验过程中,有一个有趣的实验结果可能对EEG实验设计相关的科研人员有一些启发。以运动想象为例,目前的实验设置都采用了4s的任务期(对应图中L=1000),但是和3s的任务期(对应图中L=750)相比,部分算法的分类准确率和预测的波动性并没有明显变化,但是却能减少25%的数据量。相信数据量的大幅减低在在线脑机接口系统的中应用有着重要的意义。
# 测试准则
为了公平, 公正, 透明地比较不同算法在同一公开数据集中的表现, Weight-Freezing这部分内容沿用了LMDA-Net提出的测试准则, 以此来尽可能消除随机性给不同算法比较带来的偏差. 需要强调的是, 这个准则是我LMDA-Net一直使用的测试准则, 也是我认为目前能做到的能以最公平和透明的方式比较不同人工神经网络模型的测试准则, 但是其也带有一定的主观性. 规则如下:
在算法比较时明确训练集和测试集的划分, 包括每个被试分别拥有多少训练和测试样本, 有无对包含伪迹的数据进行剔除. 如果剔除了部分包含伪迹的数据, 那么剔除的准则是什么, 剔除后的每个被试训练集和测试集的训练数据量是多少? 在我们的研究中, 针对BCI4-2A和BCI4-2B数据集, 我们并没有剔除包含伪迹的数据, 即采用了数据集中全部的训练数据进行训练, 全部的测试数据进行测试. 训练集和测试集的划分遵循数据集中的原始划分. 在High-Gamma中, 我们使用了和Shallow-ConvNet(Schirrmeister et al. (2017)同样的标准来剔除训练集和测试集中包含伪迹的试次.
需不需要使用验证集进行检测人工神经网络的训练过程? 在Weight-Freezing中,我们沿用了LMDA-Net中所提到的标准, 即不对训练集划分额外的验证集. 这么做的考量有两点: (1) 验证集的划分具有随机性, 因为EEG是非稳态数据, 不同验证集的选取带来的结果差异性大, 算法复现难度大. (2) EEG训练数据稀少, 在训练集中划分验证集会一定程度上减少训练样本的数量, 可能会降低ANN模型的准确率.
需不需要使用交叉验证? 在Weight-Freezing中, 我们同样延续了LMDA-Net的测试条件, 即不进行交叉验证. 交叉验证同设置验证集具有相同的问题, 即交叉验证也具有随机性, 这种随机性会影响EEG解码的准确率,以及算法的可重复性. 虽然采用多次实验的求取平均值的方法能一定程度上降低随机性, 但是其仍存在算法可重复性低的问题. 不利于各个算法之间公平透明的比较.
网络参数的随机性. 网络参数的随机性设置也会给不同被试的准确率带来影响, 为了比较算法的泛化性, 论文中常用的方法是以数据集中的各个被试的平均准确率作为算法综合的解码能力的体现. 在Weight-Freezing中,我们同样沿用了LMDA-Net中的测试准则, 让每一位被试都拥有相同的初始化条件. 为此, 我们固定了Numpy和Pytorch中全部的随机数种子, 以此来尽可能保证人工神经网络模型在多次测试中的可重复性.
Early-stopping? 在Weight-Freezing中, 我们同样延续了LMDA-Net中的准则, 即没有使用early-stopping来自动检测人工神经网络的训练程度. 那么如何体现或者衡量人工神经网络在训练过程中波动性呢? 也就是说不同的训练轮次下, 人工神经网络模型表现出来的准确率有一定差异? 在实际BCI系统中, 测试集的数据是没有标签的,那么如何选择最优的解码模型呢? 在Weight-Freezing中, 我们给出的答案是, 训练一定的轮次,然后记录人工神经网络模型在某个训练轮次区间内的平均准确率或中位数. 这种方法得到的平均值和中位数可以代表算法在实际BCI系统中的分类表现, 在实际应用时,即使不能确定最优的人工神经网络模型, 也可以通过投票的方式, 让解码的准确率达到上述平均值或者中位数.
# 主要作者简介:

苗政清,天津大学精仪学院博士研究生,师从赵美蓉教授, 主要研究方向为轻量级人工神经网络技术在脑机接口中的应用。
更多实验分析, 请参考本文链接:
https://arxiv.org/pdf/2306.05775.pdf
Weight-Freezing代码, 请参考下面的链接
https://github.com/MiaoZhengQing/WeightFreezing/tree/main
—— End ——
仅用于学术分享,若侵权请留言,即时删侵!
更多阅读
格拉斯哥大学中国博士生提出计算鬼成像架构
专家观点:最近Neuralink FDA IDE的真正含义是什么?
植入式脑机接口技术的医疗器械之路
LMDA-Net第一作者亲自讲述其设计思想
伸手运动想象训练与伸手抓取想象的关系

加入社群
欢迎加入脑机接口社区交流群,
探讨脑机接口领域话题,实时跟踪脑机接口前沿。
加微信群:
添加微信:RoseBrain【备注:姓名+行业/专业】。
加QQ群:913607986
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBrain
2.加入社区成为兼职创作者,请联系微信:RoseBrain


一键三连「分享」、「点赞」和「在看」
不错每一条脑机前沿进展 ~
这篇关于脑电公开数据集解码准确率再创新高, Weight-Freezing立大功的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






