本文主要是介绍高速无源链路阻抗匹配套路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在仿真优化HFSS复杂模型时,经常会发现,如果优化调整某个结构尺寸,高频VSWR指标与低频VSWR指标存在翘翘板现象,按下葫芦起了瓢!
岛主见过有人用高性能服务器优化大型HFSS模型,十个以上的结构尺寸全做参数化,设置好全频段VSWR指标,然后启动HFSS优化,7X24小时不停机盲跑。
这种盲目优化,恐怕跑到宇宙毁灭也得不到最优解,急死俺了!
何以解忧?唯有套路。
套路一:在哪个位置分段?
下图来自于百度:
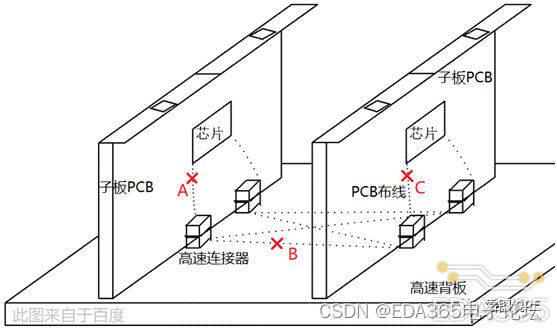
芯片~封装~子板PCB~连接器~高速背板~连接器~子板PCB~封装~芯片构成的高速无源链路,在设计阶段,将此链路在A、B、C位置断开成四截:
- 芯片封装载板 ~ 子板 PCB
- 子板 PCB~ 高速连接器 ~ 背板
- 背板 ~ 高速连接器 ~ 子板 PCB
- 子板 PCB~ 芯片封装载板
如果链路对称,则只需要考虑链路的一半,也就是两截。
当然,仍然可以细分无源链路。典型的芯片封装载板/SIP结构如下图所示:
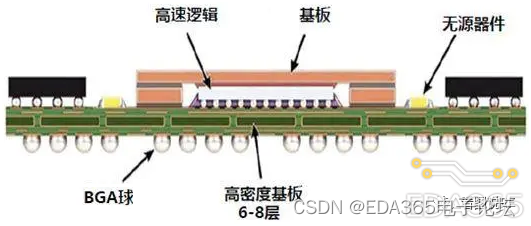
上图这样的芯片封装载板~子板PCB这段链路还可细分为以下两段:
- 芯片 ~Bonding~ 封装载板
- 封装载板 ~BGA 焊球 ~ 子板 PCB
分段位置必须位于横截面尺寸稳定的传输线上,也就是阻抗连续的位置,例如PCB微带线、带状线、同轴电缆。
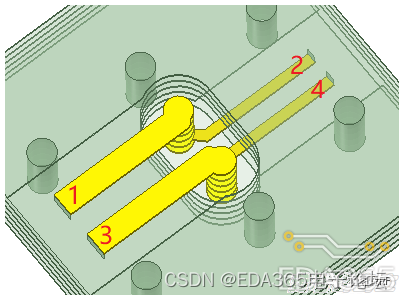
上图是差分过孔仿真模型,在横截面尺寸不变(阻抗连续)的PCB布线处分断是正常的做法。
套路二:先撸低频,后撸高频。
有些高频无源链路,由于高频信号的波长几乎与横截面结构尺寸相比拟,仿真或测试TDR指标已经不管用了!
在仿真优化HFSS复杂模型时,经常会发现,如果优化某个尺寸,高频VSWR指标与低频VSWR指标存在翘翘板现象,按下葫芦起了瓢!
怎么办呢?
要先撸低频,后撸高频。举例说明具体做法:
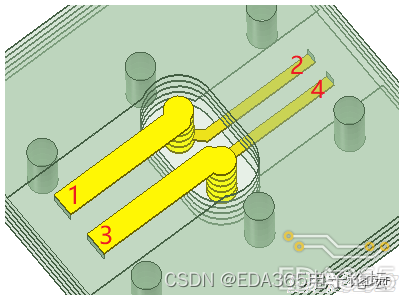
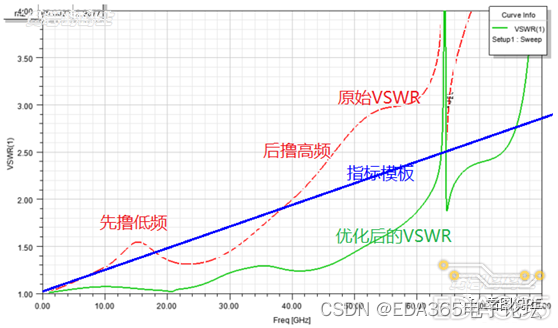
上图VSWR曲线是高频66GHz同轴连接器PCB转换结构模型的仿真指标
(后续有文章专门阐述如何定位64GHz谐振尖峰问题,敬请关注本公众号:看图说RF)。
蓝线是我们预期的无源链路的VSWR指标模板,依据无源链路复杂性(或经验)选择模板斜率;
红线在原始模型的VSWR曲线,红线在8~18GHz低频段超过模板,先调整某个结构尺寸,强制压下8~18GHz低频段的VSWR指标;
然后保持此结构尺寸不变的前提下,再调整无源链路的另一个结构尺寸,压下38~66GHz高频段VSWR指标;
优化后的模型对应绿线所示的VSWR指标。
此做法隐含的原理是:
低频是基础,高频是大楼。
基础不牢,地动山摇。
总结
复杂无源链路仿真优化套路:
ü 复杂无源链路可分断做仿真优化,分断位置必须位于横截面尺寸稳定的传输线上,也就是阻抗连续的位置。
ü 优化某个尺寸,高频VSWR指标与低频VSWR指标存在翘翘板现象,按下葫芦起了瓢!怎么办?要先撸低频,后撸高频。
出品|EDA365
作者|何平华老师
这篇关于高速无源链路阻抗匹配套路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









