本文主要是介绍「五度易链」产业园区大数据招商之“筑巢引凤 以商招商”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

招商引资”是现代园区发展的奠基石,是产业聚集的必行路,它就像是一根杠杆,撬动、支撑着整个地方经济的发展。随着我国招商同质化竞争日趋激烈,以让利为核心的传统招商引资策略吸引投资的效能日渐式微, “以商招商”等创新高效的招商模式已逐渐成为产业园区招商的重要途径。

「五度易链」“筑巢引凤,以商招商”
“以商招商”的核心思想就是“筑巢引凤,内配外引”,通过培植园区现有企业,创建良好的营商环境,建立口碑,再挖掘现有企业的上下游、配套及关联项目企业,或利用现有企业的商务渠道、人脉资源,通过现有企业的口碑宣传进行招商。
01、搭建“以商”基础
以商招商首先需要搭建好“以商”的基础,要求政府和园区建立长效机制做好企业服务,营造亲商稳商的投资发展环境,针对本地区有发展潜力或者已经发展壮大的企业进行培养,通过一系列帮扶政策,比如说聘请专家指导,提供项目低息贷款或者是帮助寻找销售渠道等,先将其做大做强,在业内形成有规模的影响力。
02、开展“招商”工作
有了“以商”基础,可以利用园区龙头企业的影响力,拓展企业产业链上下游进行招商,因为行业相通、产品相关联,企业招引的概率很大,反之企业来了也难以生存。
五度易链区域产业管理平台将围绕区域/园区龙头企业、优质企业,绘制企业关联图,分析招商路径,梳理潜在招商对象,精准匹配具备潜在供销关系的上下游招商标的,让招商实现 1+1>2 的效果。
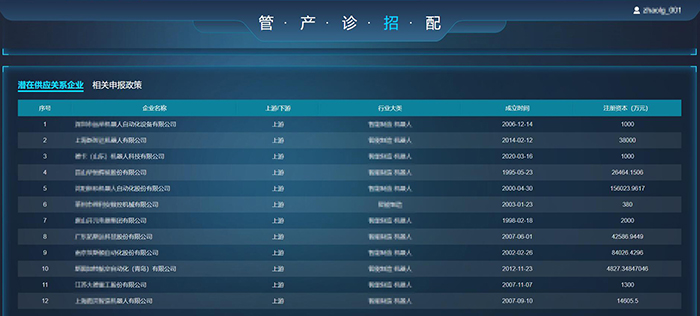
优质产业链上下游招商标的推荐
其次,园区培植的龙头企业此时将会起到“领头雁”的作用,群雁通常会选择最强者领飞,在空中组成“一”字或“人”字形雁阵,雁群始终追随“头雁”,队形始终不乱,这就是“雁阵效应”。在招商工作中,大型企业和标志性企业关联度高、聚集效应强,一旦引进落户,出于订单与成本的考量,很容易吸引配套企业和项目。
此外,以商招商,传的就是个「好口碑」,中国是一个熟人社会,人们因熟悉而信任,因信任而认可,产业园区可以通过现有企业以情招商、以诚感商,巧打感情牌。
03、做好“稳商”服务
新的企业入驻,园区应给予其足的够重视,硬件上提供保障、税收上提供优惠,遇到困难积极帮助解决等,建立起“亲”商“清”的园企关系,园区与企业打交道,要坦坦荡荡,尽心尽力,企业也有困难就说,有要求就提,真正做到“亲”不逾矩,“清”不疏远,企业才会因为园区的福利和贴心而留下来。
在以商招商的过程中,要充分调动园区内企业的招商积极性,除了企业因产业集聚获得降本增效的内在动力外,还可以通过较为直接的奖励措施进行外部激励。
五度易链区域产业数字化管理平台基于产业大数据,利用 AI 人工智能算法,致力帮助园区提高招商的主动性和实效性,提升招商工作效能,改变园区招商长期被动状态,推动招商引资工作快速发展,让招商便捷、更精准、更智能。
原创声明:本文为「五度易链」原创,欢迎转载,转载请标明出处,违者必究!
推荐阅读:产业链图谱/产业链全景图汇总,读懂各大产业链细分领域!
原文地址:筑巢引凤,『五度易链』助力大数据招商!
这篇关于「五度易链」产业园区大数据招商之“筑巢引凤 以商招商”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




