本文主要是介绍[oeasy]python0 113_字符编码_VT100控制码_iso_8859_1_拉丁字符_latin,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
拉丁字符
回忆上次内容
- 上次回顾了字型编码的进化过程
- 7-bit 的 点阵字库
- 终于让 字母、数字、标点 明确了字型
- 但是 7-bit 的 ascii中
没有法文字符的位置
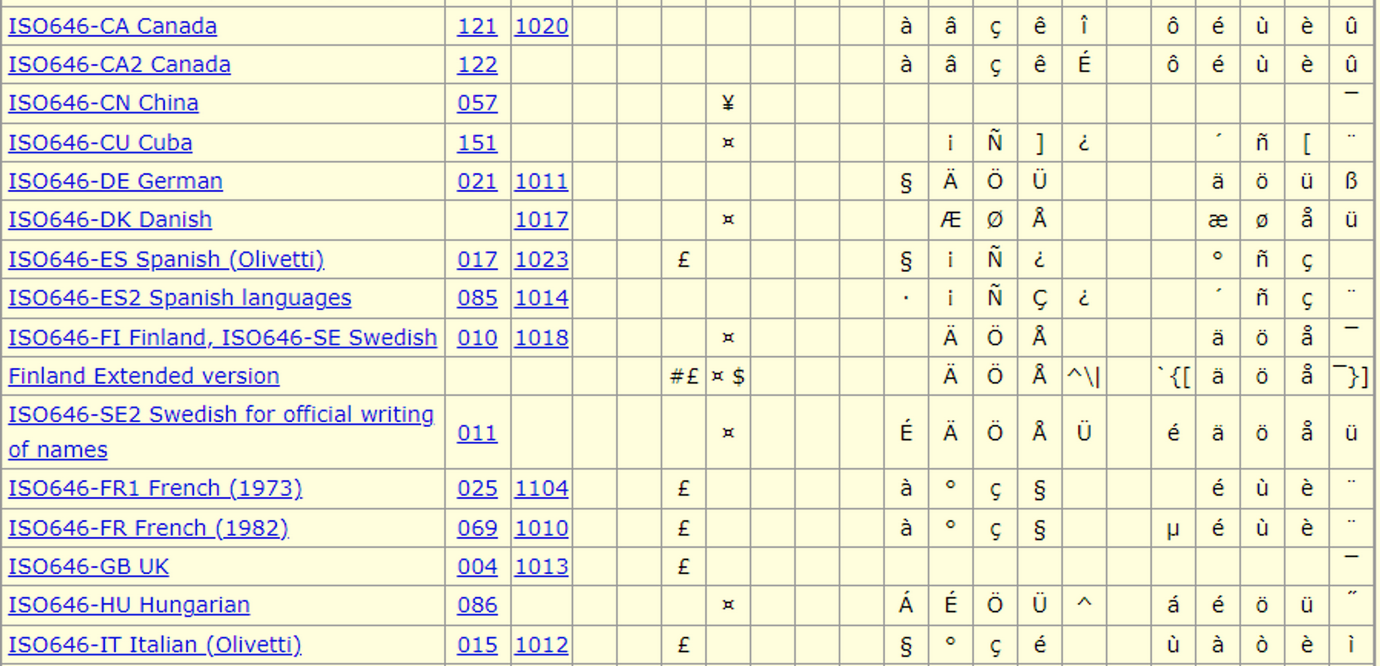
- 如果扩展位为1
- 不同的计算机厂商
- 有各自不同的 扩展方式
- 不同的计算机厂商
- 这噩梦
- 比法语不兼容 更可怕!😱
- 这以后 编码就越来越多了
- 互认对方为乱码
- 法文字符
- 完全被 不同的字符集
- 直接 变成乱码
- 完全被 不同的字符集
- 这可怎么办呢?🤔
那可是法国啊!
- 法国毕竟 曾是 与英国全球争霸的对手

- 美国 从英国独立 最早靠的
- 还是 富兰克林来法国
- 找路易十五要的 军事和经济支持
- 现在美国字符集ascii里面
- 没有法文字符的位置?
- 还是 富兰克林来法国
- 伤心的法国人 不由得回忆起那场海战
特拉法尔加海战
- 如果当年法国拿破仑选用富尔顿的火轮船
- 那特拉法尔加海战会被改写
- 如果 结局改写
- 美利坚 可能是 法国殖民地
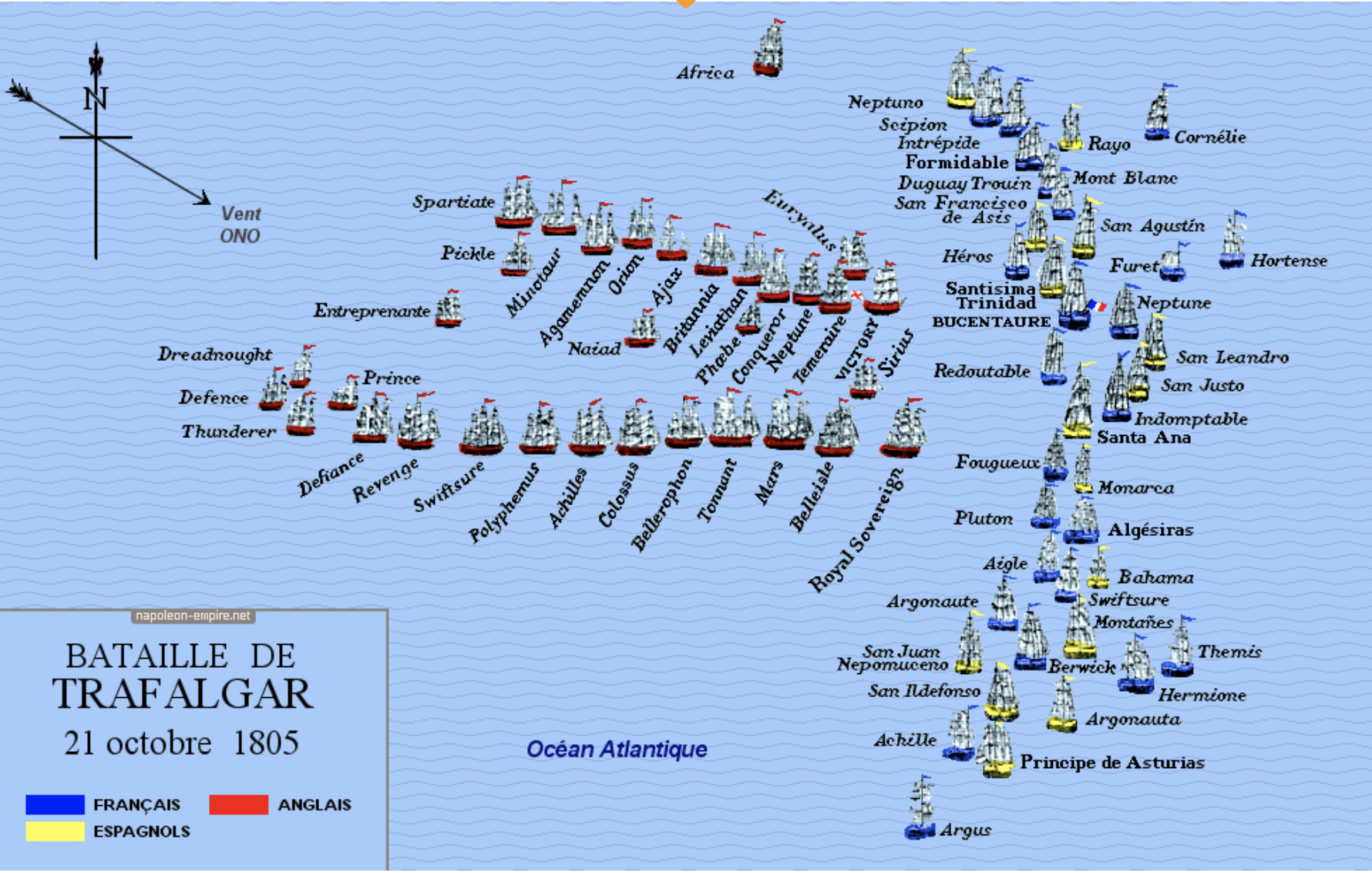
- 英国应该 无法和法国 在海上争霸
- 最终 世界语言是法语
- 美国 入学考的不是TOEFL
- 而是 TOFFL

- 再往前
- 英国就更非主流了
征服者威廉
- 法兰克王国 诺曼地区的公爵威廉
- 跨过英吉利海峡
- 成了 不列颠岛的征服者威廉
- 跨过英吉利海峡

- 不列颠岛 北高南低
- 挡住北边的冷风
- 非常 适合生存
- 从来就 不乏 征服者
英伦
- 伊比利亚、凯尔特、罗马、昂撒、丹麦、法国诺曼都曾征服不列颠
- 英格兰岛的名字 来自于 盎格鲁部落
- 当时昂撒 是 凯尔特人 搬来的救兵
- 假途灭虢 占了这个南方平坦的宝岛
- 说 这是我们盎格鲁人的岛
- England
- 盎格鲁岛人说的语言
- English

- 英国的文化 本就是 多民族、宗教杂糅出来的一个混合体
- 从不希望 欧洲大陆出现强大的帝国
- 那就会 威胁到岛上的安全
- 英国对于 欧洲各国制衡之术
- 又被后来的美国 学去制衡 整个欧亚大陆
- 不过说到底 所有文化的开局 都是从非洲走出来的
- 最最开始都是 从无机物 偶然变成 有机物
- 但是 电子信息化到数字化 是一个新的大环境
- 法文字符 的编码方式 会统一 吗?
- 先回顾 ASCII的基本情况
ascii
- 目前最熟悉的编码是
ascii编码- 包括控制字符、大小写字符、数字、符号
- 字节中 第
1位 为0- 后 7 位
- 从
0x00-0x7F
- 从
- 这里面 没有法文字符
- 后 7 位
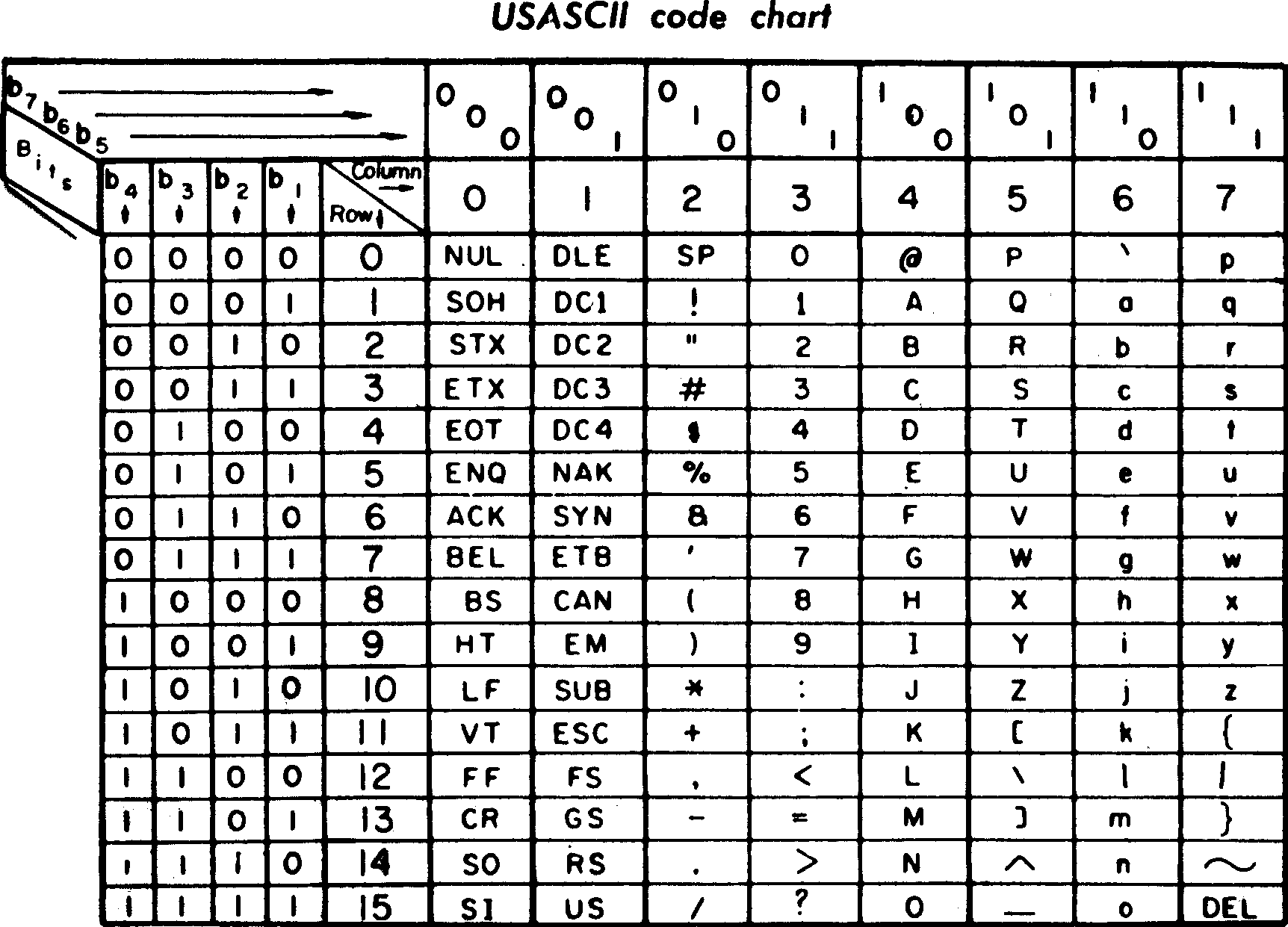
- 但如果第
1位是1- 又会如何呢?
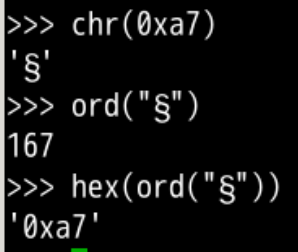
尝试输出
- 找到一个数字 0xa7
- 找到 数字对应的字符
- 这是个 章节符号
- 也可以形成
- 一个闭环
闭环
- 这规律
- 和ascii 一样的
- 也就是说 这个字节里面除了 ascii 的 128 个字符之外
- 还可以 有一定的
空间 - 还可以 对应更多字符
- 还可以 有一定的
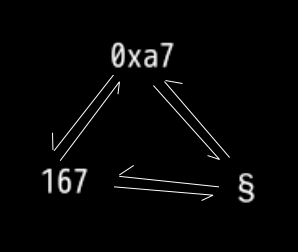
- 等于是 把ascii编码 给扩展了
编码格式
- 跨国跨语言的事情 怎么办?
- 还是要 看用户数量

- Dec公司的 VT100
- 质量 过硬
- 价格 实惠
- 终成 新一代机皇
机皇的影响力
- 新的终端
- 就必须兼容VT100
- 包括VT100中 一项新功能
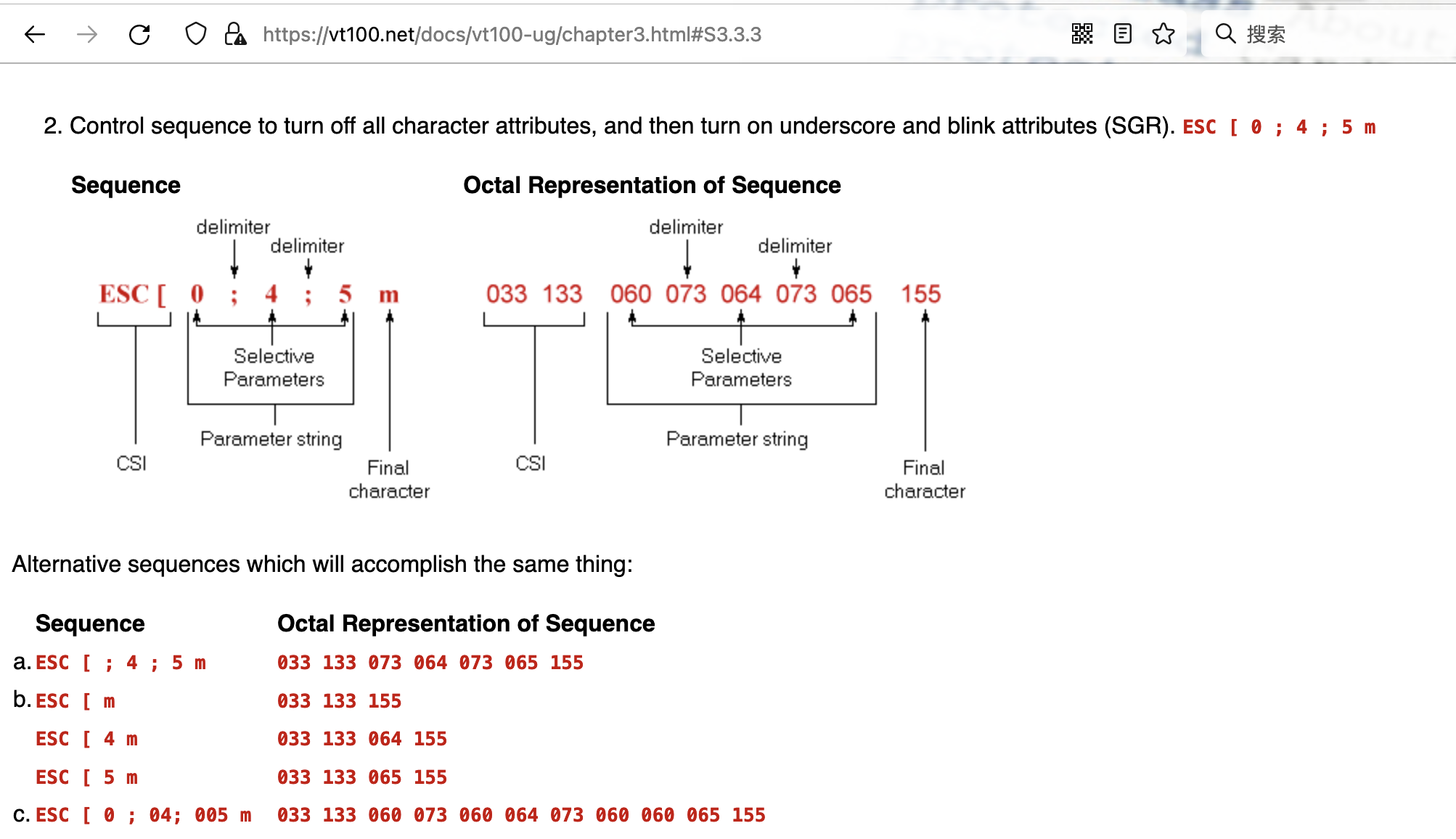
- 这CSI
- 不就是 控制序列\e 吗?
事实上的标准
- VT100 是当时 最流行的终端
- 不但支持 常用的转义字符
- 还创造出 VT100控制码
\033[0m // 关闭所有属性
\033[1m // 设置为高亮
\033[4m // 下划线
\033[5m // 闪烁
\033[7m // 反显
\033[8m // 消隐
\033[nA // 光标上移 n 行
\033[nB // 光标下移 n 行
\033[nC // 光标右移 n 行
\033[nD // 光标左移 n 行
\033[y;xH // 设置光标位置
\033[2J // 清屏
- 这就是 后来CSI的雏形 😁
- Control Sequence Introducer
- 有了这个 就可以控制
- 字体
- 位置
- 颜色
- 慢慢 DEC的VT100标准
- 就成了 计算机终端的标准
ISO组织
- 总部在 瑞士日内瓦湖的 ISO组织
- 负责 跨国跨公司的标准化
- 在Dec所用 编码格式的基础 上
- 发展出 iso-8859-1 字符集
- 为什么 选择Dec的 编码格式?
- 因为 VT100是 当时的 一代机皇
- 用户数量 就是 事实上的标准

- 根据 dec公司的 字符集
- 生成了 扩展ascii字符集(charset)
- 前一半(0-127)
- 没有动
- 还是ascii
- 后一半(128-255)
- 换成了 西欧北欧各国拉丁字符
- 这个 编码
- 叫做 iso-8859-1
- 也叫做 latin-1
- latin-1覆盖的 范围如何呢?
覆盖范围
- 西欧北欧语族都可以覆盖到
- 拉丁人的罗曼语族(法意西葡)
- 日耳曼人的日耳曼语族(瑞丹挪德冰)
- 凯尔特人的盖尔语族(苏爱)

latin-1
- 拉丁语(法意西葡)我们好理解
- 拉丁正宗
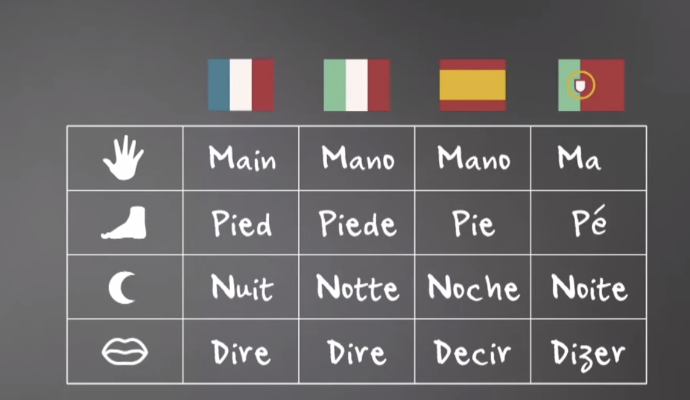
- 北欧 这么多国家
- 为什么 都使用拉丁字符呢?
- 北欧 不是有 自己的一套符文系统吗?
- 日耳曼语族 不是和 拉丁语族 并列的吗?
总结
- 这次回顾了 非ascii的拉丁字符编码的进化过程
- 0-127 是 ascii 的领域
- 西欧、北欧语言 大多使用 拉丁字符
- 由iso组织 制定iso-8859-1

-
北欧 原来 不是有自己的卢恩文字(Runes)符文系统吗?
-
我们下次再说!👋
-
蓝桥->https://www.lanqiao.cn/courses/3584
-
github->https://github.com/overmind1980/oeasy-python-tutorial
-
gitee->https://gitee.com/overmind1980/oeasypython
这篇关于[oeasy]python0 113_字符编码_VT100控制码_iso_8859_1_拉丁字符_latin的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




